? Functions, Options, and Advantages")
Giant Multimodal Fashions (LMMs) are a revolution in synthetic intelligence (AI). In contrast to conventional AI fashions that function inside a single knowledge atmosphere similar to textual content, photographs, or audio, LMMs are able to creating and processing a number of modalities concurrently.
Therefore the technology of outputs with context-aware multimedia info. The aim of this text is to unravel what LMMs are, how they get to be completely different from LLMs, and the place they are often utilized, grounded by applied sciences that make this potential.
Giant Multimodal Fashions Defined
LMMs are AI techniques that may course of and interpret a number of forms of knowledge modalities. A modality is a time period used to symbolize any knowledge construction that may be enter right into a system. Briefly, conventional AI fashions work on just one modality (for instance, text-based language fashions or picture recognition techniques) at a time; LMMs break this barrier by bringing info from completely different sources into a typical framework for evaluation.
For instance—LLMs will be one of many AI techniques that will learn a information article (textual content), analyze the accompanying images (photographs), and correlate it with associated video clips to render an intensive abstract.
It will possibly learn a picture of a menu in a international language, do a textual translation of it, and make dietary suggestions relying on the content material. Such modality integration opens a cosmic door for LMMs to do these issues that had been beforehand tough for unimodal AI techniques.
How LMMs Work
The strategies that allow LMMs to deal with multimodal knowledge successfully and optimally will be grouped into architectures and coaching strategies. Right here is how they work:
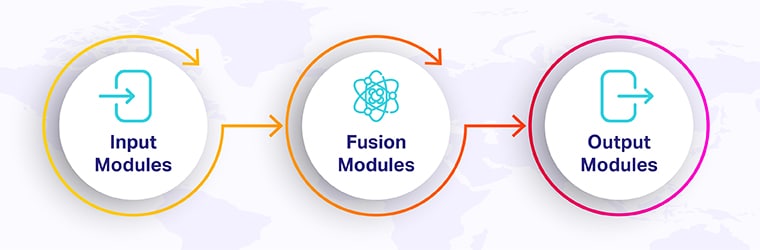
- Enter Modules: Emotional and distinct neural networks handle each modality. On this case, textual content can be a pure language processing by a pure language processing mannequin (NLP); a picture can be a convolutional neural community (CNN); and audio can be a skilled RNN or transformer.
- Fusion Modules: This is able to take the outputs of the enter modules and mix them right into a single illustration.
- Output Modules: Right here the merged illustration offers option to producing a consequence within the type of a prediction, choice, or response. For instance—producing captions about an image-answering question a few video-translating spoken enable into actions.
LMMs vs. LLMs: Key Variations
| Function | Giant Language Fashions (LLMs) | Giant Multimodal Fashions (LMMs) |
|---|---|---|
| Information Modality | Textual content-only | Textual content, photographs, audio, video |
| Capabilities | Language understanding and technology | Cross-modal understanding and technology |
| Functions | Writing articles, summarizing paperwork | Picture captioning, video evaluation, multimodal Q&A |
| Coaching Information | Textual content corpora | Textual content + photographs + audio + video |
| Examples | GPT-4 (text-only mode) | GPT-4 Imaginative and prescient, Google Gemini |
Functions for Giant Multimodal Fashions
Because the LMMs can compute a number of forms of knowledge on the identical time, the levels of their functions and unfold are very excessive in numerous sectors.
Coaching LMMs
In contrast to unimodal fashions, coaching multimodal fashions normally entails considerably better complexity. The simple purpose is the necessary use of differing datasets and sophisticated architectures:
- Multimodal Datasets: Throughout coaching, giant datasets should be used amongst completely different modalities. For this occasion, we are able to use:
- Photographs and textual content captions correspond to visible language duties.
- Movies paired with written transcripts similar to audiovisual duties.
- Optimization Strategies: Coaching must be optimized to reduce loss operate to explain the distinction between predictions and the bottom reality knowledge regarding all modalities.
- Consideration Mechanisms: A mechanism that permits the mannequin to give attention to all of the related parts of the enter knowledge and ignore unwarranted info. For instance:
- Specializing in specific objects in a picture when trying to answer questions associated to them.
- Concentrating on specific phrases in a transcript when trying to generate subtitles for a video.
- Multimodal Embeddings: These create a joint house of representations throughout the modalities, letting the mannequin perceive the relationships between the modalities. For instance:
- The time period “canine”; a picture of the canine; and the sound of barking as related.
Challenges in Constructing LMMs
Constructing efficient LMMs creates a number of challenges together with:
How Shaip might help?
The place there’s nice potential, there additionally exists challenges of integration, scaling, computational expense, and intermodal consistency, which may impose limits on these fashions’ full adoption. That is the place Shaip comes into the image. We ship high-quality, diverse, and well-annotated multimodal datasets to offer you numerous knowledge whereas following all the rules.
With our custom-made knowledge providers and annotation providers, Shaip ensures that LMMs had been initially skilled on legitimate and noticeably operational datasets, thereby enabling companies to deal with the great potentialities of multimodal AI whereas concurrently performing effectively and scalably.