
An incredible function of the human mind is the power to search out variations even in an enormous quantity of visible data. When finding out giant quantities of knowledge, this capability seems to be very helpful, as a result of the content material of the info have to be compressed right into a type comprehensible to human intelligence. For visible analytics, the issue of dimensionality discount stays the primary one.
Scientists from Aalto College and the College of Helsinki on the Finnish Heart for Synthetic Intelligence (FCAI) performed a examine the place they examined the performance of essentially the most well-known visible analytics strategies and located that none of them work when the quantity of knowledge will increase considerably. For instance, the t-SNE, LargeViz, and UMAP strategies might not distinguish extraordinarily robust sign groupings of observations within the information, when the variety of observations runs into the a whole lot of 1000’s. The t-SNE, LargeViz, and UMAP strategies not work correctly.
The researchers have developed a brand new non-linear dimensionality discount methodology referred to as Stochastic Cluster Embedding (SCE) for higher cluster visualization. It goals to visualise information units as clearly as potential and is designed to visualise information clusters and different macroscopic options in such a approach that they’re as distinct, simple to watch and human-understandable as potential. SCE makes use of graphics acceleration just like trendy synthetic intelligence strategies for computing in neural networks.
The invention of the Higgs boson was the premise for the invention of this algorithm. The information set for the experiments related to it comprises over 11 million function vectors. And these information required handy, clear visualization. This impressed the scientists to develop a brand new methodology.
The researchers generalized the SNE utilizing a household of I-divergences, parameterized by a scale issue s, between non-normalized similarities in enter and output area. SNE is a particular case within the household the place s is chosen because the normalizing issue for similarity of outputs. Nonetheless, throughout testing, it was discovered that the most effective worth of s for cluster visualization usually differs from the worth chosen by the SNE. Subsequently, to beat the shortcoming of t-SNE, the brand new SCE methodology makes use of a special method that mixes enter similarities when calculating s. The coefficient is adaptively adjusted when optimizing the brand new studying goal and thus the info factors are higher clustered. The researchers additionally developed an environment friendly optimization algorithm utilizing asynchronous stochastic descent over block coordinates. The brand new algorithm can use parallel computing units and is appropriate for mega-scale duties with giant quantities of knowledge.
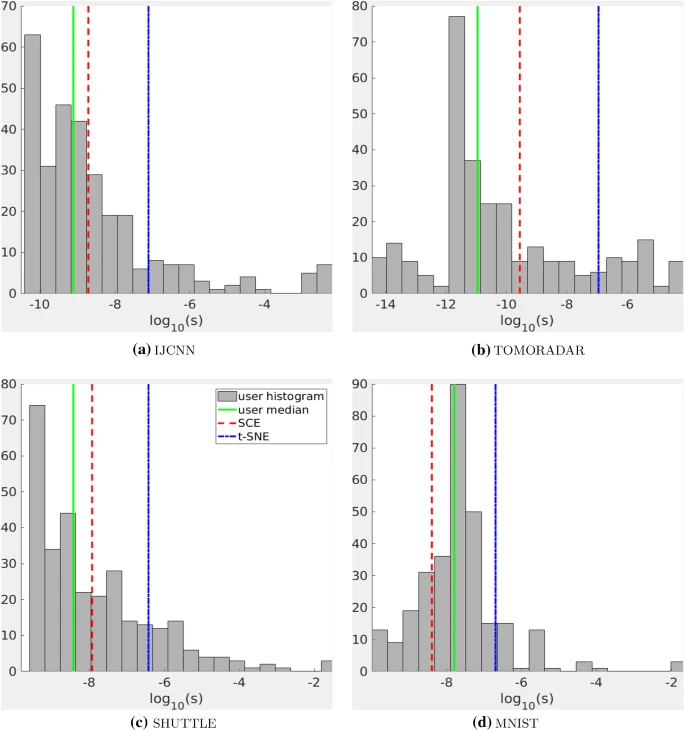
Through the improvement of the venture, the scientists examined the strategy on varied units of actual information and in contrast it with different trendy NLDR strategies. Customers taking part within the testing chosen essentially the most applicable visualizations that matched the vary of s values for viewing clusters. The researchers then in contrast the ensuing s values in SCE and t-SNE to see which was nearer to human selection. The 4 smallest datasets IJCNN, TOMORADAR, SHUTTLE and MNIST had been used for testing. For every dataset, check members had been offered with a collection of visualizations the place they used a slider to point an s worth and examined the corresponding precomputed visualization. The person selected the popular worth of s for cluster visualization.
The check outcomes clearly reveal that the s chosen by SNE is to the fitting of the human median (stable inexperienced line) for all datasets. This implies that for people, GSNE with smaller s is commonly higher than t-SNE for cluster visualization. In distinction, the SCE choice (pink dashed strains) is nearer to the human median for all 4 datasets.
By making use of the Stochastic Cluster Embedding methodology to information on the Higgs boson, their most vital bodily traits had been clearly recognized. The brand new non-linear dimensionality discount methodology Stochastic Clustering Embedding for higher cluster visualization works a number of orders of magnitude quicker than earlier strategies, and can be rather more dependable in advanced purposes. It modifies t-SNE utilizing an adaptive and environment friendly compromise between attraction and repulsion. Experimental outcomes demonstrated that the strategy can constantly determine inner clusters. As well as, scientists have supplied a easy and quick optimization algorithm that may be simply carried out on trendy parallel computing platforms. Environment friendly software program has been developed that makes use of asynchronous stochastic block gradient descent to optimize a brand new household of goal capabilities. Experimental outcomes have proven that the strategy constantly and considerably improves the visualization of knowledge clusters in comparison with trendy stochastic Neighbor Embedding approaches.
The code of the strategy is publicly obtainable at github.