
This submit is written by Chaim Rand, Principal Engineer, Pini Reisman, Software program Senior Principal Engineer, and Eliyah Weinberg, Efficiency and Expertise Innovation Engineer, at Mobileye. The Mobileye workforce want to thank Sunita Nadampalli and Man Almog from AWS for his or her contributions to this resolution and this submit.
Mobileye is driving the worldwide evolution towards smarter, safer mobility by combining pioneering AI, intensive real-world expertise, a sensible imaginative and prescient for the superior driving programs of as we speak, and the autonomous mobility of tomorrow. Highway Expertise Administration™ (REM™) is a vital element of Mobileye’s autonomous driving ecosystem. REM™ is liable for creating and sustaining extremely correct, crowdsourced high-definition (HD) maps of street networks worldwide. These maps are important for:
- Exact car localization
- Actual-time navigation
- Figuring out modifications in street circumstances
- Enhancing general autonomous driving capabilities
Mobileye Highway Expertise Administration (REM)™ (Supply: https://www.mobileye.com/know-how/rem/)
Map technology is a steady course of that requires gathering and processing knowledge from hundreds of thousands of autos geared up with Mobileye know-how, making it a computationally intensive operation that requires environment friendly and scalable options.
On this submit, we deal with one portion of the REM™ system: the automated identification of modifications to the street construction which we’ll seek advice from as Change Detection. We are going to share our journey of architecting and deploying an answer for Change Detection, the core of which is a deep studying mannequin referred to as CDNet. We are going to cowl the next factors:
- The tradeoff between working on GPU in comparison with CPU, and why our present resolution runs on CPU.
- The affect of utilizing a mannequin inference server, particularly Triton Inference Server.
- Working the Change Detection pipeline on AWS Graviton based mostly Amazon Elastic Compute Cloud (Amazon EC2) cases and its affect on deployment flexibility, in the end ensuing greater than a 2x enchancment in throughput.
We are going to share real-life choices and tradeoffs when constructing and deploying a high-scale, extremely parallelized algorithmic pipeline based mostly on a Deep Studying (DL) mannequin, with an emphasis on effectivity and throughput.
Highway change detection
Excessive-definition maps are considered one of many elements of Mobileye’s resolution for autonomous driving which are generally utilized by autonomous autos (AVs) for car localization and navigation. Nonetheless, as human drivers know, it isn’t unusual for street construction to alter. Borrowing a quote usually attributed to the Greek thinker Heraclitus: In relation to street maps – “The one fixed in life is change.” A typical reason for a street change is street development, when lanes, and their related lane-markings, could also be added, eliminated, or repositioned.
For human drivers, modifications within the street could also be inconvenient, however they’re often manageable. However for autonomous autos, such modifications can pose important challenges if not correctly accounted for. The potential for street modifications requires that the AV programs be programmed with ample redundancy and adaptableness. It additionally requires applicable mechanisms for modifying and deploying corrected REM™ maps as shortly as attainable. The diagram under captures the change detection subsystem in REM™ that’s liable for figuring out modifications within the map and, within the case a change is detected, deploying a map replace.
 REM™ Highway Change Detection and Map Replace move
REM™ Highway Change Detection and Map Replace move
Change detection is run in parallel and independently on a number of street segments from around the globe. It’s triggered utilizing a proprietary algorithm that proactively inspects knowledge collected from autos geared up with Mobileye know-how. The change detection activity is usually triggered hundreds of thousands of instances a day the place every activity runs on a separate street phase. Every street phase is evaluated at a minimal, predetermined, cadence.
The principle element of the Change Detection activity is Mobileye’s proprietary AI mannequin, CDNet, that consumes a proprietary encoding of the information collected from a number of latest drives, together with the present map knowledge, and produces a sequence of outputs which are used to robotically assess whether or not, the truth is, a street change occurred, and decide if remapping is required. Though the total change detection algorithm contains extra elements, the CDNet mannequin is the heaviest by way of its compute and reminiscence necessities. Throughout a single Change Detection activity working on a single phase, the CDNet mannequin may be referred to as dozens of instances.
Prioritizing price effectivity
Given the big scale of the change detection system, the first goal we set for ourselves when designing an answer for its deployment was minimizing prices by means of rising the common variety of accomplished change detection duties per greenback. This goal took priority over different frequent metrics comparable to minimizing latency or maximizing reliability. For instance, a key element of the deployment resolution is reliance on Amazon EC2 Spot Cases for our compute sources, that are greatest to run fault-tolerant workloads. When working offline processes, we’re ready for the potential of occasion preemption and a delayed algorithm response as a way to profit from the steep reductions of utilizing Spot Cases. As we’ll clarify, prioritizing price effectivity motivated lots of our design choices.
Architecting an answer
We made the next issues when designing our structure.
1. Run Deep Studying inference on CPU as an alternative of GPU
For the reason that core of the Change Detection pipeline is an AI/ML mannequin, the preliminary method was to design an answer based mostly on using GPU cases. And certainly, when isolating simply the CDNet mannequin inference execution, GPUs demonstrated a major benefit over CPUs. The next desk illustrates the CDNet inference uncooked efficiency on CPU in comparison with GPU.
| Occasion sort | Samples per second |
| CPU (c7i.4xlarge) | 5.85 |
| GPU (g6e.2xlarge) | 54.8 |
Nonetheless, we shortly concluded that though CDNet inference could be slower, working it on a CPU occasion would enhance general price effectivity with out compromising end-to-end pace, for the next causes:
- The pricing of GPU cases is mostly a lot increased than CPU cases. Compound that with the truth that, as a result of they’re in excessive demand, GPU cases have a lot decrease Spot availability, and endure from extra frequent Spot preemptions, than CPU cases.
- Whereas CDNet is a major element, the change detection algorithm contains many extra elements which are extra fitted to working on CPU. Though the GPU was extraordinarily quick for working CDNet, it might stay idle for a lot of the change detection pipeline, thereby lowering its effectivity. Moreover, working the complete algorithm on CPU reduces the overhead of managing and passing knowledge between completely different compute sources (utilizing CPU cases for the non-inference work and GPU cases for inference work).
Preliminary deployment resolution
For our preliminary method, we designed an auto-scaling resolution based mostly on multi-core EC2 CPU Spot Cases processing duties which are streamed from Amazon Easy Queue Service (Amazon SQS). As change detection duties have been acquired, they might be scheduled, distributed, and run in a brand new course of on a vacant slot on one of many CPU cases. The cases could be scaled up and down based mostly on the duty load.
The next diagrams illustrate the structure of this configuration.
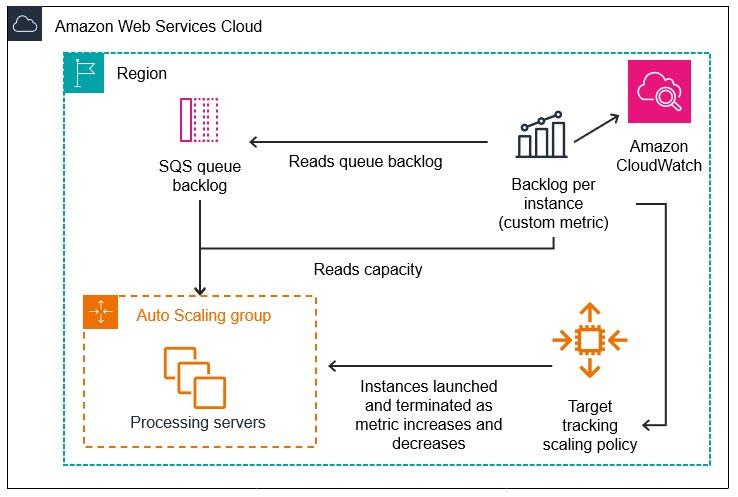
At this stage in growth, every course of would load and handle its personal copy of CDNet. Nonetheless, this turned out to be a major and limiting bottleneck. The reminiscence sources required by every course of for loading and working its copy of CDNet was 8.5 GB. Assuming for instance, that our occasion sort was a r6i.8xlarge with 256 GB of reminiscence, this implied that we have been restricted to working simply 30 duties per occasion. Furthermore, we discovered that roughly 50% of the whole time of a change detection activity was spent downloading the mannequin weights and initializing the mannequin.
2. Serve mannequin inference with Triton Inference Server
The primary optimization we utilized was to centralize the mannequin inference executions utilizing a mannequin inference server resolution. As an alternative of every course of sustaining its personal copy of CDNet, every CPU employee occasion could be initialized with a single (containerized) copy of CDNet managed by an inference server, serving the change detection processes working on the occasion. We selected to make use of Triton Inference Server as our inference server as a result of it’s open supply, easy to deploy, and contains assist for a number of runtime environments and AI/ML frameworks.
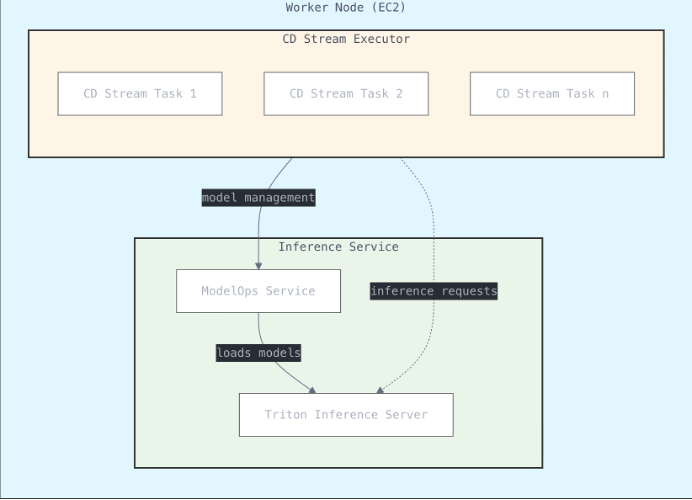
The outcomes of this optimization have been profound: The reminiscence footprint of 8.5 GB per course of dropped all the way in which right down to 2.5 GB and the common runtime per change detection activity dropped from 4 minutes to 2 minutes. With removing of the CPU reminiscence bottleneck we may enhance the variety of duties per occasion as much as full CPU utilization. Within the case of Change Detection, the optimum variety of duties per 32-vCPU occasion turned out to be 32. Total, this optimization elevated effectivity by simply over 2x.
The next desk illustrates the CDNet Inference efficiency enchancment with centralized Triton Inference Server internet hosting.
| Reminiscence required per activity | Duties per occasion | Common runtime | Duties per minute | |
| Remoted inference | 8.5 GB | 30 | 4 minutes | 7.5 |
| Centralized inference | 2.5 GB | 32 | 2 minutes | 16 |
We additionally thought-about another structure through which a scalable inference server would run in a separate unit and on unbiased cases, presumably on GPUs. Nonetheless, this selection was rejected for a number of causes:
- Elevated latency: Calling CDNet over the community quite than on the identical gadget added important latency.
- Elevated community visitors: The comparatively giant payload of CDNet considerably elevated community visitors, thereby additional rising latency.
We discovered that the automated scaling of inference capability inherent in our resolution (utilizing a further server for every CPU employee occasion), was properly suited to the inference demand.
Optimizing Triton Inference Server: Lowering Docker picture dimension for leaner deployments
The default Triton picture contains assist for a number of machine studying backends and each CPU and GPU execution, leading to a hefty picture dimension of round 15 GB. To streamline this, we rebuilt the Docker picture by together with solely the ML backend we required and proscribing execution to CPU-only. The outcome was a dramatically decreased picture dimension, down to simply 2.7 GB. This served to additional cut back reminiscence utilization and enhance the capability for added change detection processes. A smaller picture dimension interprets to sooner container startup instances.
3. Enhance occasion diversification: Use AWS Graviton cases for higher worth efficiency
At peak capability there are a lot of 1000’s of change detection duties working concurrently on a big group of Spot Cases. Inevitably, Spot availability per occasion fluctuates. A key to maintaining with the demand is to assist a big pool of occasion varieties. Our robust choice was for newer and stronger CPU cases which demonstrated important advantages each in pace and in price effectivity in comparison with different comparable cases. Right here is the place AWS Graviton introduced a major alternative.
AWS Graviton is a household of processors designed to ship the most effective worth efficiency for cloud workloads working in Amazon EC2. They’re additionally optimized for ML workloads, together with Neon vector processing engines, assist for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) directions, making them a great option to run our batched deep studying inference workloads for our Change Detection programs. Main machine studying frameworks comparable to PyTorch, TensorFlow, and ONNX have been optimized for Graviton processors.
Because it turned out, adapting our resolution to run on Graviton was easy. Most fashionable AI/ML frameworks together with Triton Inference Server embody inbuilt assist for AWS Graviton. To adapt our resolution, we needed to make the next modifications:
- Create a brand new Docker picture devoted to working the change detection pipeline on AWS Graviton (ARM structure).
- Recompile the trimmed down model of Triton Inference Server for Graviton.
- Add Graviton cases to node pool.
Outcomes
By enabling change detection to run on AWS Graviton cases we improved the general price effectivity of the change detection sub-system and elevated our occasion diversification and Spot Occasion availability considerably.
1. Elevated throughput
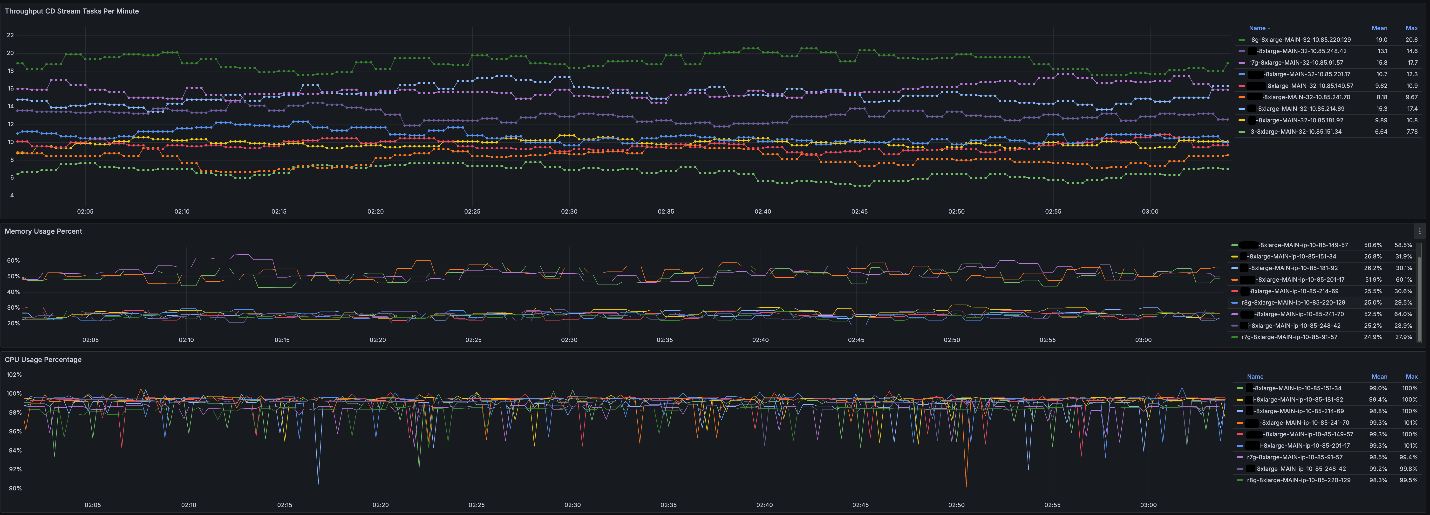
To quantify the affect, we are able to share an instance. Suppose that the present activity load calls for 5,000 compute cases, solely half of which could be stuffed by fashionable non-Graviton CPU cases. Earlier than including AWS Graviton to our useful resource pool, we would want to fill the remainder of the demand with older technology CPUs which run 3x slower. Following our occasion diversification optimization, we are able to fill these with AWS Graviton Spot availability. Within the case of our instance, this doubles the general effectivity.Lastly, on this instance, the throughput enchancment seems to exceed 2x, because the runtime efficiency of CDNet on AWS Graviton cases is usually sooner than the comparable EC2 cases.
The next desk illustrates the CDNet Inference efficiency enchancment with AWS Graviton cases.
| Occasion Sort | Samples per second |
| AWS Graviton based mostly EC2 occasion – r8g.8xlarge | 19.4 |
| Comparable non Graviton CPU occasion – 8xlarge | 13.5 |
| Older Technology non Graviton CPU occasion – 8xlarge | 6.64 |
With AWS Graviton cases, we may see the next CDNet Inference efficiency.
2. Improved person expertise
With the Triton Inference Server deployment and elevated fleet diversification and occasion availability, we’ve got improved our Change Detection system throughput considerably that gives an enhanced person expertise for our prospects.
3. Skilled seamless migration
Most fashionable AI/ML frameworks together with Triton Inference Server embody inbuilt assist for AWS Graviton which made adapting our resolution to run on Graviton easy.
Conclusion
In relation to optimizing runtime effectivity, the work just isn’t performed. There are sometimes extra parameters to tune and extra flags to use. AI/ML frameworks and libraries are always enhancing and optimizing their assist for a lot of completely different endpoint occasion varieties, significantly AWS Graviton. We anticipate that with additional effort, we’ll proceed to enhance on our optimization efforts. We look ahead to sharing the subsequent steps in our journey in a future submit.For additional studying, seek advice from the next:
In regards to the authors
 Chaim Rand is a Principal Engineer and machine studying algorithm developer engaged on deep studying and pc imaginative and prescient applied sciences for Autonomous Car options at Mobileye.
Chaim Rand is a Principal Engineer and machine studying algorithm developer engaged on deep studying and pc imaginative and prescient applied sciences for Autonomous Car options at Mobileye.
 Pini Reisman is a Software program Senior Principal Engineer main the Efficiency Engineering and Technological Innovation within the Engineering group in REM – the mapping group in Mobileye.
Pini Reisman is a Software program Senior Principal Engineer main the Efficiency Engineering and Technological Innovation within the Engineering group in REM – the mapping group in Mobileye.
 Eliyah Weinberg is a Efficiency and scale optimization and know-how innovation engineer at Mobileye REM.
Eliyah Weinberg is a Efficiency and scale optimization and know-how innovation engineer at Mobileye REM.
 Sunita Nadampalli is a Principal Engineer and AI/ML knowledgeable at AWS. She leads AWS Graviton software program efficiency optimizations for AI/ML and HPC workloads. She is enthusiastic about open-source software program growth and delivering high-performance and sustainable software program options for SoCs based mostly on the Arm ISA.
Sunita Nadampalli is a Principal Engineer and AI/ML knowledgeable at AWS. She leads AWS Graviton software program efficiency optimizations for AI/ML and HPC workloads. She is enthusiastic about open-source software program growth and delivering high-performance and sustainable software program options for SoCs based mostly on the Arm ISA.
 Man Almog is a Senior Options Architect at AWS, specializing in compute and machine studying. He works with giant enterprise AWS prospects to design and implement scalable cloud options. His function includes offering technical steerage on AWS companies, creating high-level options, and making architectural suggestions that concentrate on safety, efficiency, resiliency, price optimization, and operational effectivity.
Man Almog is a Senior Options Architect at AWS, specializing in compute and machine studying. He works with giant enterprise AWS prospects to design and implement scalable cloud options. His function includes offering technical steerage on AWS companies, creating high-level options, and making architectural suggestions that concentrate on safety, efficiency, resiliency, price optimization, and operational effectivity.