
Think about entering into your first knowledge science interview—your palms are sweaty, your thoughts racing, after which… you get a query you truly know the reply to. That’s the facility of preparation. With knowledge science reshaping how companies make selections, the race to rent expert knowledge scientists is extra intense than ever. For freshers, standing out in a sea of expertise means extra than simply figuring out the fundamentals—it means being interview-ready. On this article, we’ve handpicked the highest 100 knowledge science interview questions that regularly seem in actual interviews, supplying you with the sting you want.
From Python programming and EDA to statistics and machine studying, every query is paired with insights and suggestions that will help you grasp the ideas and ace your solutions. Whether or not you’re aiming for a startup or a Fortune 500 firm, this information is your secret weapon to land that dream job and kickstart your journey as a profitable knowledge scientist.
Knowledge Science Interview Questions Relating to Python
Allow us to have a look at knowledge science interview questions and solutions relating to Python.
Newbie Interview Python Questions for Knowledge Science
Q1. Which is quicker, python checklist or Numpy arrays, and why?
A. NumPy arrays are faster than Python lists when it involves numerical computations. NumPy is a Python library for array processing, and it presents a number of features for performing operations on arrays in an environment friendly method.
One of the causes NumPy arrays are quicker than Python lists is that NumPy arrays are written in C, whereas Python lists are written in Python. This implies that operations on NumPy arrays are written in a compiled language and therefore are quicker than operations on Python lists, that are written in an interpreted language.
Q2. What’s the distinction between a python checklist and a tuple?
A. An inventory in Python is a sequence of objects of various sorts. Lists are mutable, i.e., you possibly can alter the worth of an inventory merchandise or insert or delete objects in an inventory. Lists are outlined utilizing sq. brackets and a comma-delimited checklist of values.
A tuple can be an ordered checklist of objects, however it’s immutable, which means that you just can’t alter the worth of a tuple object or add or delete parts from a tuple.
Lists are initiated utilizing sq. brackets ([ ” ]), whereas tuples are initiated utilizing parentheses ((”, )).
Lists have quite a few built-in strategies for including, deleting, and manipulating parts, however tuples don’t have these strategies.
Usually, tuples are faster than lists in Python
Q3. What are python units? Clarify a number of the properties of units.
A. In Python, a set is an unordered assortment of distinctive objects. Units are sometimes used to retailer a group of distinct objects and to carry out membership checks (i.e., to examine if an object is within the set). Units are outlined utilizing curly braces ({ and }) and a comma-separated checklist of values.
Listed here are some key properties of units in Python:
- Units are unordered: Units would not have a selected order, so you can not index or slice them like you possibly can with lists or tuples.
- Units are distinctive: Units solely permit distinctive objects, so if you happen to attempt to add a replica object to a set, it won’t be added.
- Units are mutable: You may add or take away parts from a set utilizing the add and take away strategies.
- Units should not listed: Units don’t help indexing or slicing, so you can not entry particular person parts of a set utilizing an index.
- Units should not hashable: Units are mutable, so that they can’t be used as keys in dictionaries or as parts in different units. If you want to use a mutable object as a key or a component in a set, you need to use a tuple or a frozen set (an immutable model of a set).
This fall. What’s the distinction between cut up and be part of?
A. Break up and be part of are each features of python strings, however they’re fully totally different on the subject of functioning.
The cut up perform is used to create an inventory from strings primarily based on some delimiter, for eg. area.
a = ‘This can be a string’
Li = a.cut up(‘ ‘)
print(li)Output:
[‘This’, ‘is’, ‘a’, ‘string’]The be part of() methodology is a built-in perform of Python’s str class that concatenates an inventory of strings right into a single string. It’s referred to as on a delimiter string and invoked with an inventory of strings to be joined. The delimiter string is inserted between every string within the checklist when the strings are concatenated.
Right here is an instance of the way to use the be part of() methodology:
“ “.be part of(li)Output:
This can be a stringRight here the checklist is joined with an area in between.
Q5. Clarify the logical operations in python.
A. In Python, the logical operations and, or, and never can be utilized to carry out boolean operations on reality values (True and False).
The and operator returns True if each the operands are True, and False in any other case.
The or operator returns True if both of the operands is True, and False if each operands are False.
The not operator inverts the boolean worth of its operand. If the operand is True, not return False, and if the operand is False, not return True.
Q6. Clarify the highest 5 features used for python strings.
A. Listed here are the highest 5 Python string features:
| Operate | Description |
|---|---|
| len() | Returns the size of a string. |
| strip() | Removes main and trailing whitespace from a string. |
| cut up() | Splits a string into an inventory of substrings primarily based on a delimiter. |
| substitute() | Replaces all occurrences of a specified string with one other string. |
| higher() | Converts a string to uppercase. |
| decrease() | Converts a string to lowercase. |
s="Good day, World!"
len(s) # 13
s.strip() # 'Good day, World!'
s.cut up(',') # ['Hello', ' World!']
s.substitute('World', 'Universe') # 'Good day, Universe!'
s.higher() # 'HELLO, WORLD!'
s.decrease() # 'whats up, world!'Q7. What’s the usage of the go key phrase in python?
A. go is a null assertion that does nothing. It’s typically used as a placeholder the place a press release is required syntactically, however no motion must be taken. For instance, if you wish to outline a perform or a category however haven’t but determined what it ought to do, you need to use go as a placeholder.
Q8. What’s the usage of the proceed key phrase in python?
A. proceed is utilized in a loop to skip over the present iteration and transfer on to the subsequent one. When proceed is encountered, the present iteration of the loop is terminated, and the subsequent one begins.
Intermediate Interview Python Knowledge Science Questions
Q9. What are immutable and mutable knowledge varieties?
A. In Python, an immutable object is an object whose state can’t be modified after it’s created. This implies you can’t change the worth of an immutable object as soon as it’s created. Examples of immutable objects in Python embrace numbers (resembling integers, floats, and sophisticated numbers), strings, and tuples.
Alternatively, a mutable object is an object whose state might be modified after it’s created. This implies you can change the worth of a mutable object after it’s created. Examples of mutable objects in Python embrace lists and dictionaries.
Understanding the distinction between immutable and mutable objects in Python is necessary as a result of it may possibly have an effect on how you employ and manipulate knowledge in your code. For instance, if in case you have an inventory of numbers and also you need to type the checklist in ascending order, you need to use the built-in type() methodology to do that. Nevertheless, if in case you have a tuple of numbers, you possibly can’t use the type() methodology as a result of tuples are immutable. As an alternative, you would need to create a brand new sorted tuple from the unique tuple.
Q10. What’s the usage of attempt to settle for block in python
A. The attempt to besides block in Python are used to deal with exceptions. An exception is an error that happens throughout the execution of a program.
The attempt block accommodates code which may trigger an exception to be raised. The besides block accommodates code that’s executed if an exception is raised throughout the execution of the attempt block.
Utilizing a try-except block will save the code from an error to happen and might be executed with a message or output we wish within the besides block.
Q11. What are 2 mutable and a couple of immutable knowledge varieties in python?
A. 2 mutable knowledge varieties are:
You may change/edit the values in a python dictionary and an inventory. It isn’t essential to make a brand new checklist which signifies that it satisfies the property of mutability.
2 immutable knowledge varieties are:
You can’t edit a string or a price in a tuple as soon as it’s created. It is advisable to both assign the values to the tuple or make a brand new tuple.
Q12. What are python features, and the way do they assist in code optimization?
A. In Python, a perform is a block of code that may be referred to as by different elements of your program. Features are helpful as a result of they mean you can reuse code and divide your code into logical blocks that may be examined and maintained individually.
To name a perform in Python, you merely use the perform identify adopted by a pair of parentheses and any obligatory arguments. The perform could or could not return a price that will depend on the utilization of the flip assertion.
Features also can assist in code optimization:
- Code reuse: Features mean you can reuse code by encapsulating it in a single place and calling it a number of instances from totally different elements of your program. This might help to cut back redundancy and make your code extra concise and simpler to keep up.
- Improved readability: By dividing your code into logical blocks, features could make your code extra readable and simpler to know. This will make it simpler to establish bugs and make adjustments to your code.
- Simpler testing: Features mean you can take a look at particular person blocks of code individually, which might make it simpler to seek out and repair bugs.
- Improved efficiency: Features also can assist to enhance the efficiency of your code by permitting you to make use of optimized code libraries or by permitting the Python interpreter to optimize the code extra successfully.
Q13. Why does NumPy have enormous recognition within the area of knowledge science?
A. NumPy (brief for Numerical Python) is a well-liked library for scientific computing in Python. It has gained a number of recognition within the knowledge science neighborhood as a result of it gives quick and environment friendly instruments for working with giant arrays and matrices of numerical knowledge.
NumPy gives quick and environment friendly operations on arrays and matrices of numerical knowledge. It makes use of optimized C and Fortran code behind the scenes to carry out these operations, which makes them a lot quicker than equal operations utilizing Python’s built-in knowledge constructions. It gives quick and environment friendly instruments for working with giant arrays and matrices of numerical knowledge.
NumPy gives a lot of features for performing mathematical and statistical operations on arrays and matrices.
It means that you can work with giant quantities of knowledge effectively. It gives instruments for dealing with giant datasets that might not slot in reminiscence, resembling features for studying and writing knowledge to disk and for loading solely a portion of a dataset into reminiscence at a time.
NumPy integrates effectively with different scientific computing libraries in Python, resembling SciPy (Scientific Python) and pandas. This makes it simple to make use of NumPy with different libraries to carry out extra advanced knowledge science duties.
Q14. Clarify checklist comprehension and dict comprehension.
A. Record comprehension and dict comprehension are each concise methods to create new lists or dictionaries from current iterables.
Record comprehension is a concise technique to create an inventory. It consists of sq. brackets containing an expression adopted by a for clause, then zero or extra for or if clauses. The result’s a brand new checklist that evaluates the expression within the context of the for and if clauses.
Dict comprehension is a concise technique to create a dictionary. It consists of curly braces containing a key-value pair, adopted by a for clause, then zero or extra for or if clauses. A result’s a brand new dictionary that evaluates the key-value pair within the context of the for and if clauses.
Q15. What are world and native variables in python?
A. In Python, a variable that’s outlined exterior of any perform or class is a worldwide variable, whereas a variable that’s outlined inside a perform or class is an area variable.
A worldwide variable might be accessed from anyplace in this system, together with inside features and lessons. Nevertheless, an area variable can solely be accessed throughout the perform or class through which it’s outlined.
You will need to observe that you need to use the identical identify for a worldwide variable and an area variable, however the native variable will take priority over the worldwide variable throughout the perform or class through which it’s outlined.
# This can be a world variable
x = 10
def func():
# This can be a native variable
x = 5
print(x)my_function
func()
print(x)Output:
This may print 5 after which 10Within the instance above, the x variable contained in the func() perform is an area variable, so it takes priority over the worldwide variable x. Due to this fact, when x is printed contained in the perform, it prints 5; when it’s printed exterior the perform, it prints 10.
Q16. What’s an ordered dictionary?
A. An ordered dictionary, also called an OrderedDict, is a subclass of the built-in Python dictionary class that maintains the order of parts through which they had been added. In a daily dictionary, the order of parts is decided by the hash values of their keys, which might change over time because the dictionary grows and evolves. An ordered dictionary, then again, makes use of a doubly linked checklist to recollect the order of parts, in order that the order of parts is preserved no matter how the dictionary adjustments.
Q17. What’s the distinction between return and yield key phrases?
A. Return is used to exit a perform and return a price to the caller. When a return assertion is encountered, the perform terminates instantly, and the worth of the expression following the return assertion is returned to the caller.
yield, then again, is used to outline a generator perform. A generator perform is a particular sort of perform that produces a sequence of values one after the other, as a substitute of returning a single worth. When a yield assertion is encountered, the generator perform produces a price and suspends its execution, saving its state for later
Superior Python Interview Questions
Q18. What are lambda features in python, and why are they necessary?
A. In Python, a lambda perform is a small nameless perform. You need to use lambda features while you don’t need to outline a perform utilizing the def key phrase.
Lambda features are helpful while you want a small perform for a brief time period. They’re typically utilized in mixture with higher-order features, resembling map(), filter(), and cut back().
Right here’s an instance of a lambda perform in Python:
x = lambda a : a + 10
x(5)
15On this instance, the lambda perform takes one argument (a) and provides 10 to it. The lambda perform returns the results of this operation when it’s referred to as.
Lambda features are necessary as a result of they mean you can create small nameless features in a concise approach. They’re typically utilized in practical programming, a programming paradigm that emphasizes utilizing features to resolve issues.
Q19. What’s the usage of the ‘assert’ key phrase in python?
A. In Python, the assert assertion is used to check a situation. If the situation is True, then this system continues to execute. If the situation is False, then this system raises an AssertionError exception.
The assert assertion is commonly used to examine the interior consistency of a program. For instance, you would possibly use an assert assertion to examine {that a} checklist is sorted earlier than performing a binary search on the checklist.
It’s necessary to notice that the assert assertion is used for debugging functions and isn’t meant for use as a technique to deal with runtime errors. In manufacturing code, it’s best to use attempt to besides blocks to deal with exceptions that may be raised at runtime.
Q20. What are decorators in python?
A. In Python, decorators are a technique to modify or lengthen the performance of a perform, methodology, or class with out altering their supply code. Decorators are sometimes carried out as features that take one other perform as an argument and return a brand new perform that has the specified habits.
A decorator is a particular perform that begins with the @ image and is positioned instantly earlier than the perform, methodology, or class it decorates. The @ image is used to point that the next perform is a decorator.
Interview Questions Relating to EDA and Statistics
Allow us to have a look at knowledge science interview questions and solutions relating to EDA and Statistics.
Newbie Interview Questions on Statistics
Q21. The best way to carry out univariate evaluation for numerical and categorical variables?
A. Univariate evaluation is a statistical method used to research and describe the traits of a single variable. It’s a useful gizmo for understanding the distribution, central tendency, and dispersion of a variable, in addition to figuring out patterns and relationships throughout the knowledge. Listed here are the steps for performing univariate evaluation for numerical and categorical variables:
For numerical variables:
- Calculate descriptive statistics such because the imply, median, mode, and normal deviation to summarize the distribution of the info.
- Visualize the distribution of the info utilizing plots resembling histograms, boxplots, or density plots.
- Test for outliers and anomalies within the knowledge.
- Test for normality within the knowledge utilizing statistical checks or visualizations resembling a Q-Q plot.
For categorical variables.
- Calculate the frequency or rely of every class within the knowledge.
- Calculate the proportion or proportion of every class within the knowledge.
- Visualize the distribution of the info utilizing plots resembling bar plots or pie charts.
- Test for imbalances or abnormalities within the distribution of the info.
Word that the precise steps for performing univariate evaluation could fluctuate relying on the precise wants and objectives of the evaluation. You will need to fastidiously plan and execute the evaluation with the intention to precisely and successfully describe and perceive the info.
Q22. What are the alternative ways through which we will discover outliers within the knowledge?
A. Outliers are knowledge factors which might be considerably totally different from nearly all of the info. They are often brought on by errors, anomalies, or uncommon circumstances, and so they can have a big influence on statistical analyses and machine studying fashions. Due to this fact, you will need to establish and deal with outliers appropriately with the intention to receive correct and dependable outcomes.
Listed here are some widespread methods to seek out outliers within the knowledge:
- Visible inspection: Outliers can typically be recognized by visually inspecting the info utilizing plots resembling histograms, scatterplots, or boxplots.
- Abstract statistics: Outliers can typically be recognized by calculating abstract statistics such because the imply, median, or interquartile vary, and evaluating them to the info. For instance, if the imply is considerably totally different from the median, it may point out the presence of outliers.
- Z-score: The z-score of a knowledge level is a measure of what number of normal deviations it’s from the imply. Knowledge factors with a z-score larger than a sure threshold (e.g., 3 or 4) might be thought of outliers.
There are a lot of different strategies for detecting outliers within the knowledge, and the suitable methodology will depend upon the precise traits and wishes of the info. You will need to fastidiously consider and select probably the most acceptable methodology for figuring out outliers with the intention to receive correct and dependable outcomes.
Q23. What are the alternative ways by which you’ll be able to impute the lacking values within the dataset?
A. There are a number of methods you can impute null values (i.e., lacking values) in a dataset:
- Drop rows: One possibility is to easily drop rows with null values from the dataset. This can be a easy and quick methodology, however it may be problematic if a lot of rows are dropped, as it may possibly considerably cut back the pattern dimension and influence the statistical energy of the evaluation.
- Drop columns: An alternative choice is to drop columns with null values from the dataset. This generally is a good possibility if the variety of null values is giant in comparison with the variety of non-null values, or if the column just isn’t related to the evaluation.
- Imputation with imply or median: One widespread methodology of imputation is to switch null values with the imply or median of the non-null values within the column. This generally is a good possibility if the info are lacking at random and the imply or median is an inexpensive illustration of the info.
- Imputation with mode: An alternative choice is to switch null values with the mode (i.e., the most typical worth) of the non-null values within the column. This generally is a good possibility for categorical knowledge the place the mode is a significant illustration of the info.
- Imputation with a predictive mannequin: One other methodology of imputation is to make use of a predictive mannequin to estimate the lacking values primarily based on the opposite obtainable knowledge. This generally is a extra advanced and time-consuming methodology, however it may be extra correct if the info should not lacking at random and there’s a sturdy relationship between the lacking values and the opposite knowledge.
Q24. What are Skewness in statistics and its varieties?
A. Skewness is a measure of the symmetry of a distribution. A distribution is symmetrical whether it is formed like a bell curve, with a lot of the knowledge factors concentrated across the imply. A distribution is skewed if it isn’t symmetrical, with extra knowledge factors focused on one facet of the imply than the opposite.
There are two sorts of skewness: constructive skewness and detrimental skewness.
- Constructive skewness: Constructive skewness happens when the distribution has a protracted tail on the proper facet, with nearly all of the info factors focused on the left facet of the imply. Constructive skewness signifies that there are just a few excessive values on the proper facet of the distribution that’s pulling the imply to the proper.
- Unfavourable skewness: Unfavourable skewness happens when the distribution has a protracted tail on the left facet, with nearly all of the info factors focused on the proper facet of the imply. Unfavourable skewness signifies that there are just a few excessive values on the left facet of the distribution that’s pulling the imply to the left.
Q25. What are the measures of central tendency?
A. In statistics, measures of central tendency are values that signify the middle of a dataset. There are three principal measures of central tendency: imply, median, and mode.
The imply is the arithmetic common of a dataset and is calculated by including all of the values within the dataset and dividing by the variety of values. The imply is delicate to outliers, or values which might be considerably increased or decrease than nearly all of the opposite values within the dataset.
The median is the center worth of a dataset when the values are organized so as from smallest to largest. To search out the median, you have to first organize the values so as after which find the center worth. If there’s an odd variety of values, the median is the center worth. If there’s an excellent variety of values, the median is the imply of the 2 center values. The median just isn’t delicate to outliers.
The mode is the worth that happens most regularly in a dataset. A dataset could have a number of modes or no modes in any respect. The mode just isn’t delicate to outliers.
Q26. Are you able to clarify the distinction between descriptive and inferential statistics?
A. Descriptive statistics is used to summarize and describe a dataset by utilizing measures of central tendency (imply, median, mode) and measures of unfold (normal deviation, variance, vary). Inferential statistics is used to make inferences a few inhabitants primarily based on a pattern of knowledge and utilizing statistical fashions, speculation testing and estimation.
Q27. What are the important thing parts of an EDA report and the way do they contribute to understanding a dataset?
A. The important thing parts of an EDA report embrace univariate evaluation, bivariate evaluation, lacking knowledge evaluation, and fundamental knowledge visualization. Univariate evaluation helps in understanding the distribution of particular person variables, bivariate evaluation helps in understanding the connection between variables, lacking knowledge evaluation helps in understanding the standard of knowledge, and knowledge visualization gives a visible interpretation of the info.
Intermediate Interview Questions on Statistics for Knowledge Science
Q28 What’s the central restrict theorem?
A. The Central Restrict Theorem is a elementary idea in statistics that states that because the pattern dimension will increase, the distribution of the pattern imply will method a traditional distribution. That is true whatever the underlying distribution of the inhabitants from which the pattern is drawn. Because of this even when the person knowledge factors in a pattern should not usually distributed, by taking the typical of a giant sufficient variety of them, we will use regular distribution-based strategies to make inferences in regards to the inhabitants.
Q29. Point out the 2 sorts of goal variables for predictive modeling.
A. The 2 sorts of goal variables are:
Numerical/Steady variables – Variables whose values lie inside a spread, may very well be any worth in that vary and the time of prediction; values should not certain to be from the identical vary too.
For instance: Peak of scholars – 5; 5.1; 6; 6.7; 7; 4.5; 5.11
Right here the vary of the values is (4,7)
And, the peak of some new college students can/can’t be any worth from this vary.
Categorical variable – Variables that may tackle considered one of a restricted, and normally mounted, variety of attainable values, assigning every particular person or different unit of statement to a specific group on the premise of some qualitative property.
A categorical variable that may tackle precisely two values is termed a binary variable or a dichotomous variable. Categorical variables with greater than two attainable values are referred to as polytomous variables
For instance Examination Outcome: Move, Fail (Binary categorical variable)
The blood sort of an individual: A, B, O, AB (polytomous categorical variable)
Q30. What would be the case through which the Imply, Median, and Mode would be the identical for the dataset?
A. The imply, median, and mode of a dataset will all be the identical if and provided that the dataset consists of a single worth that happens with 100% frequency.
For instance, take into account the next dataset: 3, 3, 3, 3, 3, 3. The imply of this dataset is 3, the median is 3, and the mode is 3. It is because the dataset consists of a single worth (3) that happens with 100% frequency.
Alternatively, if the dataset accommodates a number of values, the imply, median, and mode will usually be totally different. For instance, take into account the next dataset: 1, 2, 3, 4, 5. The imply of this dataset is 3, the median is 3, and the mode is 1. The dataset accommodates a number of values, and no worth happens with 100% frequency.
You will need to observe that outliers or excessive values within the dataset can have an effect on the imply, median, and mode. If the dataset accommodates excessive values, the imply and median could also be considerably totally different from the mode, even when the dataset consists of a single worth that happens with a excessive frequency.
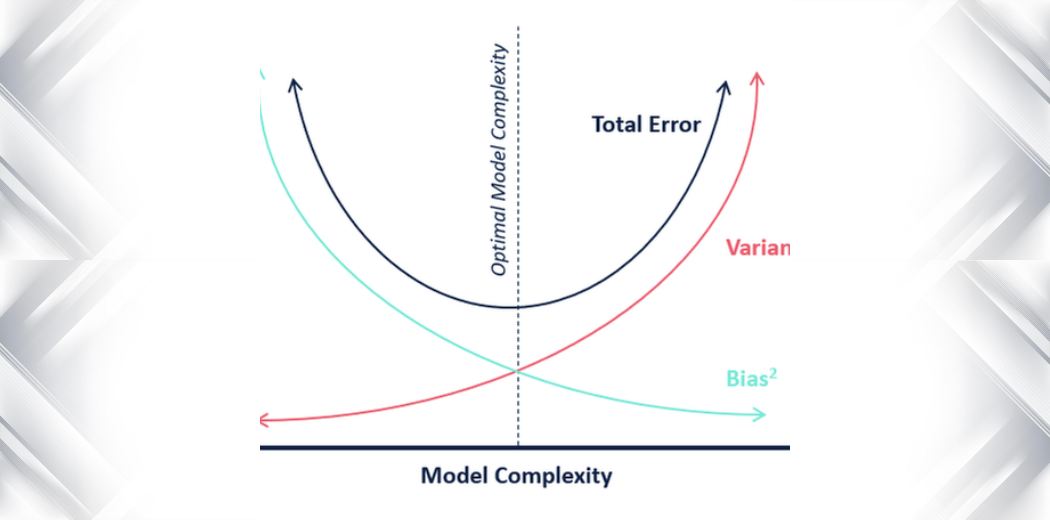
Q31. What’s the distinction between Variance and Bias in Statistics?
A. In statistics, variance, and bias are two measures of the standard or accuracy of a mannequin or estimator.
- Variance: Variance measures the quantity of unfold or dispersion in a dataset. It’s calculated as the typical squared deviation from the imply. A excessive variance signifies that the info are unfold out and could also be extra susceptible to error, whereas a low variance signifies that the info are concentrated across the imply and could also be extra correct.
- Bias: Bias refers back to the distinction between the anticipated worth of an estimator and the true worth of the parameter being estimated. A excessive bias signifies that the estimator is constantly beneath or overestimating the true worth, whereas a low bias signifies that the estimator is extra correct.
You will need to take into account each variance and bias when evaluating the standard of a mannequin or estimator. A mannequin with low bias and excessive variance could also be susceptible to overfitting, whereas a mannequin with excessive bias and low variance could also be susceptible to underfitting. Discovering the proper steadiness between bias and variance is a vital facet of mannequin choice and optimization.
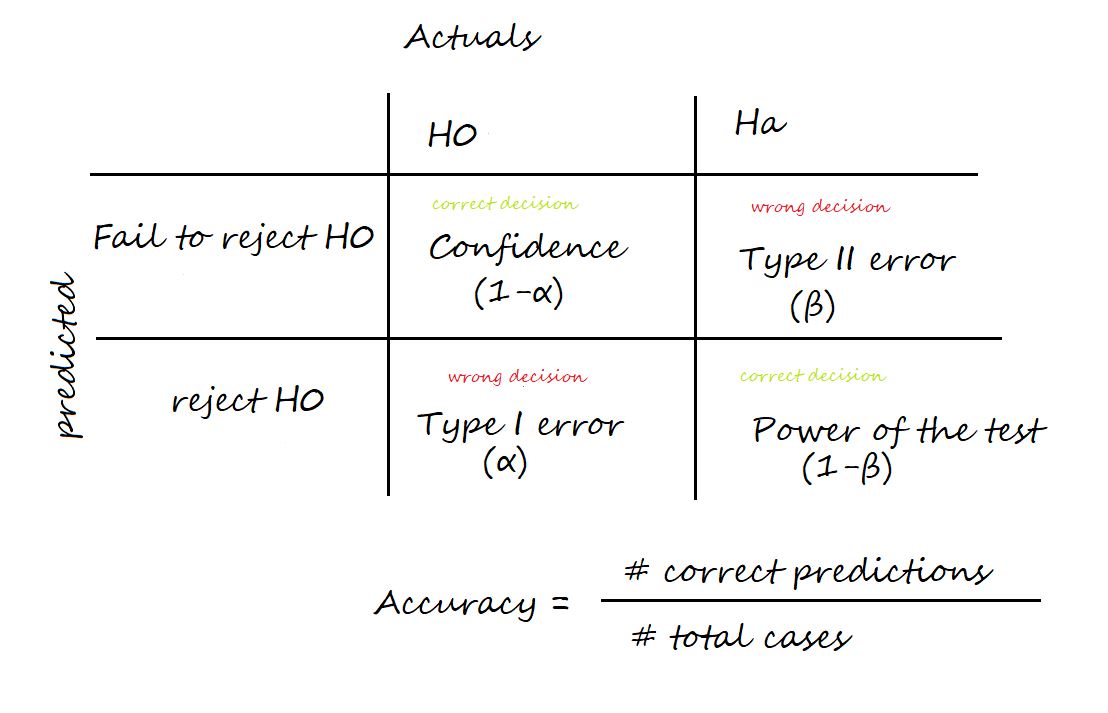
Q32. What’s the distinction between Kind I and Kind II errors?
A. Two sorts of errors can happen in speculation testing: Kind I errors and Kind II errors.
A Kind I error, also called a “false constructive,” happens when the null speculation is true however is rejected. This kind of error is denoted by the Greek letter alpha (α) and is normally set at a stage of 0.05. This implies that there’s a 5% likelihood of creating a Kind I error or a false constructive.
A Kind II error, also called a “false detrimental,” happens when the null speculation is fake however just isn’t rejected. This kind of error is denoted by the Greek letter beta (β) and is commonly represented as 1 – β, the place β is the facility of the take a look at. The ability of the take a look at is the chance of accurately rejecting the null speculation when it’s false.
It’s necessary to attempt to reduce the possibilities of each sorts of errors in speculation testing.
Q33. What’s the Confidence Interval in statistics?
A. The arrogance interval is the vary inside which we anticipate the outcomes to lie if we repeat the experiment. It’s the imply of the outcome plus and minus the anticipated variation.
The usual error of the estimate determines the latter, whereas the middle of the interval coincides with the imply of the estimate. The most typical confidence interval is 95%.
Q34. Are you able to clarify the idea of correlation and covariance?
A. Correlation is a statistical measure that describes the power and course of a linear relationship between two variables. A constructive correlation signifies that the 2 variables enhance or lower collectively, whereas a detrimental correlation signifies that the 2 variables transfer in reverse instructions. Covariance is a measure of the joint variability of two random variables. It’s used to measure how two variables are associated.
Superior Statistics Interview Questions
Q35. Why is speculation testing helpful for a knowledge scientist?
A. Speculation testing is a statistical method utilized in knowledge science to guage the validity of a declare or speculation a few inhabitants. It’s used to find out whether or not there’s ample proof to help a declare or speculation and to evaluate the statistical significance of the outcomes.
There are a lot of conditions in knowledge science the place speculation testing is helpful. For instance, it may be used to check the effectiveness of a brand new advertising marketing campaign, to find out if there’s a vital distinction between the technique of two teams, to guage the connection between two variables, or to evaluate the accuracy of a predictive mannequin.
Speculation testing is a vital software in knowledge science as a result of it permits knowledge scientists to make knowledgeable selections primarily based on knowledge, somewhat than counting on assumptions or subjective opinions. It helps knowledge scientists to attract conclusions in regards to the knowledge which might be supported by statistical proof, and to speak their findings in a transparent and dependable method. Speculation testing is due to this fact a key element of the scientific methodology and a elementary facet of knowledge science observe.
Q36. What’s a chi-square take a look at of independence used for in statistics?
A. A chi-square take a look at of independence is a statistical take a look at used to find out whether or not there’s a vital affiliation between two categorical variables. It’s used to check the null speculation that the 2 variables are unbiased, which means that the worth of 1 variable doesn’t depend upon the worth of the opposite variable.
The chi-square take a look at of independence includes calculating a chi-square statistic and evaluating it to a essential worth to find out the chance of the noticed relationship occurring by likelihood. If the chance is under a sure threshold (e.g., 0.05), the null speculation is rejected and it’s concluded that there’s a vital affiliation between the 2 variables.
The chi-square take a look at of independence is usually utilized in knowledge science to guage the connection between two categorical variables, resembling the connection between gender and buying habits, or the connection between schooling stage and voting choice. It is a vital software for understanding the connection between totally different variables and for making knowledgeable selections primarily based on the info.
Q37. What’s the significance of the p-value?
A. The p-value is used to find out the statistical significance of a outcome. In speculation testing, the p-value is used to evaluate the chance of acquiring a outcome that’s at the least as excessive because the one noticed, provided that the null speculation is true. If the p-value is lower than the predetermined stage of significance (normally denoted as alpha, α), then the result’s thought of statistically vital and the null speculation is rejected.
The importance of the p-value is that it permits researchers to make selections in regards to the knowledge primarily based on a predetermined stage of confidence. By setting a stage of significance earlier than conducting the statistical take a look at, researchers can decide whether or not the outcomes are more likely to have occurred by likelihood or if there’s a actual impact current within the knowledge.
Q38.What are the various kinds of sampling methods utilized by knowledge analysts?
A. There are a lot of various kinds of sampling methods that knowledge analysts can use, however a number of the most typical ones embrace:
- Easy random sampling: This can be a fundamental type of sampling through which every member of the inhabitants has an equal likelihood of being chosen for the pattern.
- Stratified random sampling: This system includes dividing the inhabitants into subgroups (or strata) primarily based on sure traits, after which deciding on a random pattern from every stratum.
- Cluster sampling: This system includes dividing the inhabitants into smaller teams (or clusters), after which deciding on a random pattern of clusters.
- Systematic sampling: This system includes deciding on each kth member of the inhabitants to be included within the pattern.
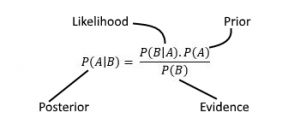
Q39.What’s Bayes’ theorem and the way is it utilized in knowledge science?
A. Bayes’ theorem is a mathematical method that describes the chance of an occasion occurring, primarily based on prior data of situations that may be associated to the occasion. In knowledge science, Bayes’ theorem is commonly utilized in Bayesian statistics and machine studying, for duties resembling classification, prediction, and estimation.
Q40.What’s the distinction between a parametric and a non-parametric take a look at?
A. A parametric take a look at is a statistical take a look at that assumes that the info follows a selected chance distribution, resembling a traditional distribution. A non-parametric take a look at doesn’t make any assumptions in regards to the underlying chance distribution of the info.
Allow us to have a look at knowledge science interview questions and solutions relating to Machine Studying.
Newbie ML Interview Questions for Knowledge Science
Q41. What’s the distinction between characteristic choice and extraction?
A. Characteristic choice is the method through which we filter the options that needs to be fed to the mannequin. That is the duty through which we choose probably the most related options. The options that clearly don’t maintain any significance in figuring out the prediction of the mannequin are rejected.
Characteristic choice then again is the method by which the options are extracted from the uncooked knowledge. It includes reworking uncooked knowledge right into a set of options that can be utilized to coach an ML mannequin.
Each of those are crucial as they assist in filtering the options for our ML mannequin which helps in figuring out the accuracy of the mannequin.
Q42. What are the 5 assumptions for linear regression?
A. Listed here are the 5 assumptions of linear regression:
- Linearity: There’s a linear relationship between the unbiased variables and the dependent variable.
- Independence of errors: The errors (residuals) are unbiased of one another.
- Homoscedasticity: The variance of the errors is fixed throughout all predicted values.
- Normality: The errors observe a traditional distribution.
- Independence of predictors: The unbiased variables should not correlated with one another.
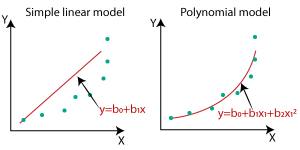
Q43. What’s the distinction between linear and nonlinear regression?
A. Linear regression is the strategy through which is used to seek out the connection between a dependent and a number of unbiased variables. The mannequin finds the best-fit line, which is a linear perform (y = mx +c) that helps in becoming the mannequin in such a approach that the error is minimal contemplating all the info factors. So the choice boundary of a linear regression perform is linear.
A non-Linear regression is used to mannequin the connection between a dependent and a number of unbiased variables by a non-linear equation. The non-linear regression fashions are extra versatile and are capable of finding the extra advanced relationship between variables.
Q44. How will you establish underfitting in a mannequin?
A. Underfitting happens when a statistical mannequin or machine studying algorithm just isn’t in a position to seize the underlying development of the info. This will occur for a wide range of causes, however one widespread trigger is that the mannequin is just too easy and isn’t in a position to seize the complexity of the info
Right here is the way to establish underfitting in a mannequin:
The coaching error of an underfitting error will probably be excessive, i.e., the mannequin will be unable to study from the coaching knowledge and can carry out poorly on the coaching knowledge.
The validation error of an underfitting mannequin may even be excessive as it should carry out poorly on the brand new knowledge as effectively.
Q45. How will you establish overfitting in a mannequin?
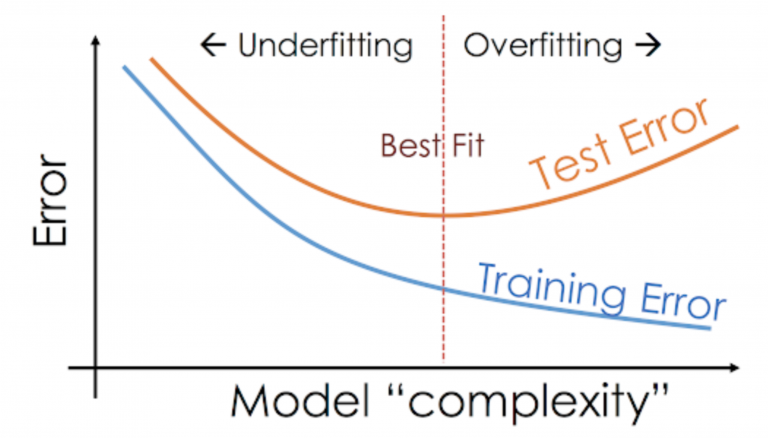
A. Overfitting in a mannequin happens when the mannequin learns the entire coaching knowledge as a substitute of taking alerts/hints from the info and the mannequin performs extraordinarily effectively on coaching knowledge and performs poorly on the testing knowledge.
The testing error of the mannequin is excessive in comparison with the coaching error. The bias of an overfitting mannequin is low whereas the variance is excessive.
Q46. What are a number of the methods to keep away from overfitting?
A. Some methods that can be utilized to keep away from overfitting;
- Practice-validation-test cut up: One technique to keep away from overfitting is to separate your knowledge into coaching, validation, and take a look at units. The mannequin is educated on the coaching set after which evaluated on the validation set. The hyperparameters are then tuned primarily based on the efficiency on the validation set. As soon as the mannequin is finalized, it’s evaluated on the take a look at set.
- Early stopping: One other technique to keep away from overfitting is to make use of early stopping. This includes coaching the mannequin till the validation error reaches a minimal, after which stopping the coaching course of.
- Regularization: Regularization is a method that can be utilized to stop overfitting by including a penalty time period to the target perform. This time period encourages the mannequin to have small weights, which might help cut back the complexity of the mannequin and forestall overfitting.
- Ensemble strategies: Ensemble strategies contain coaching a number of fashions after which combining their predictions to make a closing prediction. This might help cut back overfitting by averaging out the predictions of the person fashions, which might help cut back the variance of the ultimate prediction.
Q47. What are a number of the methods to keep away from underfitting?
A. Some methods to stop underfitting in a mannequin:
Characteristic choice: You will need to select the proper characteristic required for coaching a mannequin because the choice of the fallacious characteristic may end up in underfitting.
Growing the variety of options helps to keep away from underfitting
Utilizing a extra advanced machine-learning mannequin
Utilizing Hyperparameter tuning to high quality tune the parameters within the mannequin
Noise: If there’s extra noise within the knowledge, the mannequin will be unable to detect the complexity of the dataset.
Q48. What’s Multicollinearity?
A. Multicollinearity happens when two or extra predictor variables in a a number of regression mannequin are extremely correlated. This will result in unstable and inconsistent coefficients, and make it troublesome to interpret the outcomes of the mannequin.
In different phrases, multicollinearity happens when there’s a excessive diploma of correlation between two or extra predictor variables. This will make it troublesome to find out the distinctive contribution of every predictor variable to the response variable, because the estimates of their coefficients could also be influenced by the opposite correlated variables.
Q49. Clarify regression and classification issues.
A. Regression is a technique of modeling the connection between a number of unbiased variables and a dependent variable. The purpose of regression is to know how the unbiased variables are associated to the dependent variable and to have the ability to make predictions in regards to the worth of the dependent variable primarily based on new values of the unbiased variables.
A classification drawback is a sort of machine studying drawback the place the purpose is to foretell a discrete label for a given enter. In different phrases, it’s a drawback of figuring out to which set of classes a brand new statement belongs, on the premise of a coaching set of knowledge containing observations.
Q50. What’s the distinction between Ok-means and KNN?
A. Ok-means and KNN (Ok-Nearest Neighbors) are two totally different machine studying algorithms.
Ok-means is a clustering algorithm that’s used to divide a bunch of knowledge factors into Ok clusters, the place every knowledge level belongs to the cluster with the closest imply. It’s an iterative algorithm that assigns knowledge factors to a cluster after which updates the cluster centroid (imply) primarily based on the info factors assigned to it.
Alternatively, KNN is a classification algorithm that’s used to categorise knowledge factors primarily based on their similarity to different knowledge factors. It really works by discovering the Ok knowledge factors within the coaching set which might be most just like the info level being categorized, after which it assigns the info level to the category that’s most typical amongst these Ok knowledge factors.
So, in abstract, Ok-means is used for clustering, and KNN is used for classification.
Q51. What’s the distinction between Sigmoid and Softmax ?
A. In Sigmoid perform in case your output is binary (0,1) then use the sigmoid perform for the output layer. The sigmoid perform seems within the output layer of the deep studying fashions and is used for predicting probability-based outputs.
The softmax perform is one other sort of Activation Operate utilized in neural networks to compute chance distribution from a vector of actual numbers.
This perform is especially utilized in multi-class fashions the place it returns chances of every class, with the goal class having the very best chance.
The first distinction between the sigmoid and softmax Activation perform is that whereas the previous is utilized in binary classification, the latter is used for multivariate classification
Q52. Can we use logistic regression for multiclass classification?
A. Sure, logistic regression can be utilized for multiclass classification.
Logistic regression is a classification algorithm that’s used to foretell the chance of a knowledge level belonging to a sure class. It’s a binary classification algorithm, which signifies that it may possibly solely deal with two lessons. Nevertheless, there are methods to increase logistic regression to multiclass classification.
A method to do that is to make use of one-vs-all (OvA) or one-vs-rest (OvR) technique, the place you prepare Ok logistic regression classifiers, one for every class, and assign a knowledge level to the category that has the very best predicted chance. That is referred to as OvA if you happen to prepare one classifier for every class, and the opposite class is the “relaxation” of the lessons. That is referred to as OvR if you happen to prepare one classifier for every class, and the opposite class is the “all” of the lessons.
One other approach to do that is to make use of multinomial logistic regression, which is a generalization of logistic regression to the case the place you’ve greater than two lessons. In multinomial logistic regression, you prepare a logistic regression classifier for every pair of lessons, and you employ the expected chances to assign a knowledge level to the category that has the very best chance.
So, in abstract, logistic regression can be utilized for multiclass classification utilizing OvA/OvR or multinomial logistic regression.
Q53. Are you able to clarify the bias-variance tradeoff within the context of supervised machine studying?
A. In supervised machine studying, the purpose is to construct a mannequin that may make correct predictions on unseen knowledge. Nevertheless, there’s a tradeoff between the mannequin’s means to suit the coaching knowledge effectively (low bias) and its means to generalize to new knowledge (low variance).
A mannequin with excessive bias tends to underfit the info, which signifies that it isn’t versatile sufficient to seize the patterns within the knowledge. Alternatively, a mannequin with excessive variance tends to overfit the info, which signifies that it’s too delicate to noise and random fluctuations within the coaching knowledge.
The bias-variance tradeoff refers back to the tradeoff between these two sorts of errors. A mannequin with low bias and excessive variance is more likely to overfit the info, whereas a mannequin with excessive bias and low variance is more likely to underfit the info.
To steadiness the tradeoff between bias and variance, we have to discover a mannequin with the proper complexity stage for the issue at hand. If the mannequin is just too easy, it should have excessive bias and low variance, but it surely will be unable to seize the underlying patterns within the knowledge. If the mannequin is just too advanced, it should have low bias and excessive variance, however it is going to be delicate to the noise within the knowledge and it’ll not generalize effectively to new knowledge.
Q54. How do you resolve whether or not a mannequin is affected by excessive bias or excessive variance?
A. There are a number of methods to find out whether or not a mannequin is affected by excessive bias or excessive variance. Some widespread strategies are:
Break up the info right into a coaching set and a take a look at set, and examine the efficiency of the mannequin on each units. If the mannequin performs effectively on the coaching set however poorly on the take a look at set, it’s more likely to endure from excessive variance (overfitting). If the mannequin performs poorly on each units, it’s doubtless affected by excessive bias (underfitting).
Use cross-validation to estimate the efficiency of the mannequin. If the mannequin has excessive variance, the efficiency will fluctuate considerably relying on the info used for coaching and testing. If the mannequin has excessive bias, the efficiency will probably be constantly low throughout totally different splits of the info.
Plot the training curve, which reveals the efficiency of the mannequin on the coaching set and the take a look at set as a perform of the variety of coaching examples. A mannequin with excessive bias can have a excessive coaching error and a excessive take a look at error, whereas a mannequin with excessive variance can have a low coaching error and a excessive take a look at error.
Q55. What are some methods for balancing bias and variance in a mannequin?
A. There are a number of methods that can be utilized to steadiness the bias and variance in a mannequin, together with:
Growing the mannequin complexity by including extra parameters or options: This might help the mannequin seize extra advanced patterns within the knowledge and cut back bias, however it may possibly additionally enhance variance if the mannequin turns into too advanced.
Decreasing the mannequin complexity by eradicating parameters or options: This might help the mannequin keep away from overfitting and cut back variance, however it may possibly additionally enhance bias if the mannequin turns into too easy.
Utilizing regularization methods: These methods constrain the mannequin complexity by penalizing giant weights, which might help the mannequin keep away from overfitting and cut back variance. Some examples of regularization methods are L1 regularization, L2 regularization, and elastic internet regularization.
Splitting the info right into a coaching set and a take a look at set: This enables us to guage the mannequin’s generalization means and tune the mannequin complexity to attain a very good steadiness between bias and variance.
Utilizing cross-validation: This can be a method for evaluating the mannequin’s efficiency on totally different splits of the info and averaging the outcomes to get a extra correct estimate
of the mannequin’s generalization means.
Q56. How do you select the suitable analysis metric for a classification drawback, and the way do you interpret the outcomes of the analysis?
A. There are a lot of analysis metrics that you need to use for a classification drawback, and the suitable metric will depend on the precise traits of the issue and the objectives of the analysis. Some widespread analysis metrics for classification embrace:
- Accuracy: That is the most typical analysis metric for classification. It measures the proportion of appropriate predictions made by the mannequin.
- Precision: This metric measures the proportion of true constructive predictions amongst all constructive predictions made by the mannequin.
- Recall: This metric measures the proportion of true constructive predictions amongst all precise constructive instances within the take a look at set.
- F1 Rating: That is the harmonic imply of precision and recall. It’s a good metric to make use of while you need to steadiness precision and recall.
- AUC-ROC: This metric measures the power of the mannequin to tell apart between constructive and detrimental lessons. It’s generally used for imbalanced classification issues.
To interpret the outcomes of the analysis, it’s best to take into account the precise traits of the issue and the objectives of the analysis. For instance, in case you are making an attempt to establish fraudulent transactions, it’s possible you’ll be extra eager about maximizing precision, since you need to reduce the variety of false alarms. Alternatively, in case you are making an attempt to diagnose a illness, it’s possible you’ll be extra eager about maximizing recall, since you need to reduce the variety of missed diagnoses.
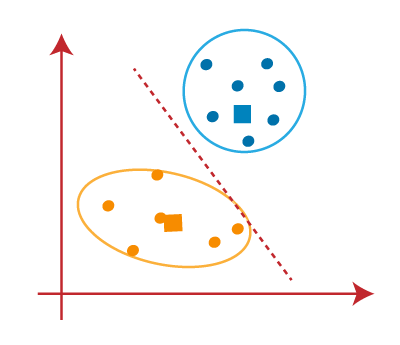
Q57. What’s the distinction between Ok-means and hierarchical clustering and when to make use of what?
A. Ok-means and hierarchical clustering are two totally different strategies for clustering knowledge. Each strategies might be helpful in numerous conditions.
Ok-means is a centroid-based algorithm, or a distance-based algorithm, the place we calculate the distances to assign some extent to a cluster. Ok-means may be very quick and environment friendly when it comes to computational time, however it may possibly fail to seek out the worldwide optimum as a result of it makes use of random initializations for the centroid seeds.
Hierarchical clustering, then again, is a density-based algorithm that doesn’t require us to specify the variety of clusters beforehand. It builds a hierarchy of clusters by making a tree-like diagram, referred to as a dendrogram. There are two principal sorts of hierarchical clustering: agglomerative and divisive. Agglomerative clustering begins with particular person factors as separate clusters and merges them into bigger clusters, whereas divisive clustering begins with all factors in a single cluster and divides them into smaller clusters. Hierarchical clustering is a gradual algorithm and requires a number of computational sources, however it’s extra correct than Ok-means.
So, when to make use of Ok-means and when to make use of hierarchical clustering? It actually will depend on the scale and construction of your knowledge, in addition to the sources you’ve obtainable. In case you have a big dataset and also you need to cluster it rapidly, then Ok-means may be a sensible choice. In case you have a small dataset or if you’d like extra correct clusters, then hierarchical clustering may be a better option.
Q58. How will you deal with imbalanced lessons in a logistic regression mannequin?
A. There are a number of methods to deal with imbalanced lessons in a logistic regression mannequin. Some approaches embrace:
- Undersampling the bulk class: This includes randomly deciding on a subset of the bulk class samples to make use of in coaching the mannequin. This might help to steadiness the category distribution, however it might additionally throw away worthwhile info.
- Oversampling the minority class: This includes producing artificial samples of the minority class so as to add to the coaching set. One in style methodology for producing artificial samples is named SMOTE (Artificial Minority Oversampling Approach).
- Adjusting the category weights: Many machine studying algorithms mean you can alter the weighting of every class. In logistic regression, you are able to do this by setting the class_weight parameter to “balanced”. This may mechanically weight the lessons inversely proportional to their frequency, in order that the mannequin pays extra consideration to the minority class.
- Utilizing a distinct analysis metric: In imbalanced classification duties, it’s typically extra informative to make use of analysis metrics which might be delicate to class imbalance, resembling precision, recall, and the F1 rating.
- Utilizing a distinct algorithm: Some algorithms, resembling determination bushes and Random Forests, are extra strong to imbalanced lessons and will carry out higher on imbalanced datasets.
Q59. When to not use PCA for dimensionality discount?
A. There are a number of conditions when it’s possible you’ll not need to use Principal Element Evaluation (PCA) for dimensionality discount:
When the info just isn’t linearly separable: PCA is a linear method, so it will not be efficient at lowering the dimensionality of knowledge that isn’t linearly separable.
The knowledge has categorical options: PCA is designed to work with steady numerical knowledge and will not be efficient at lowering the dimensionality of knowledge with categorical options.
When the info has a lot of lacking values: PCA is delicate to lacking values and will not work effectively with knowledge units which have a lot of lacking values.
The purpose is to protect the relationships between the unique options: PCA is a method that appears for patterns within the knowledge and creates new options which might be mixtures of the unique options. In consequence, it will not be the only option if the purpose is to protect the relationships between the unique options.
When the info is extremely imbalanced: PCA is delicate to class imbalances and will not produce good outcomes on extremely imbalanced knowledge units.
Q60. What’s Gradient descent?
A. Gradient descent is an optimization algorithm utilized in machine studying to seek out the values of parameters (coefficients and bias) of a mannequin that reduce the price perform. It’s a first-order iterative optimization algorithm that follows the detrimental gradient of the price perform to converge to the worldwide minimal.
In gradient descent, the mannequin’s parameters are initialized with random values, and the algorithm iteratively updates the parameters in the wrong way of the gradient of the price perform with respect to the parameters. The scale of the replace is decided by the training charge, which is a hyperparameter that controls how briskly the algorithm converges to the worldwide minimal.
Because the algorithm updates the parameters, the price perform decreases and the mannequin’s efficiency improves
Q61. What’s the distinction between MinMaxScaler and StandardScaler?
A. Each the MinMaxScaler and StandardScaler are instruments used to remodel the options of a dataset in order that they are often higher modeled by machine studying algorithms. Nevertheless, they work in numerous methods.
MinMaxScaler scales the options of a dataset by reworking them to a selected vary, normally between 0 and 1. It does this by subtracting the minimal worth of every characteristic from all of the values in that characteristic, after which dividing the outcome by the vary (i.e., the distinction between the minimal and most values). This transformation is given by the next equation:
x_scaled = (x - x_min) / (x_max - x_min)StandardScaler standardizes the options of a dataset by reworking them to have zero imply and unit variance. It does this by subtracting the imply of every characteristic from all of the values in that characteristic, after which dividing the outcome by the usual deviation. This transformation is given by the next equation:
x_scaled = (x - imply(x)) / std(x)Typically, StandardScaler is extra appropriate for datasets the place the distribution of the options is roughly regular, or Gaussian. MinMaxScaler is extra appropriate for datasets the place the distribution is skewed or the place there are outliers. Nevertheless, it’s all the time a good suggestion to visualise the info and perceive the distribution of the options earlier than selecting a scaling methodology.
Q62. What’s the distinction between Supervised and Unsupervised studying?
A. In supervised studying, the coaching set you feed to the algorithm consists of the specified options, referred to as labels.
Ex = Spam Filter (Classification drawback)
k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Help Vector Machines (SVMs)
- Choice Bushes and Random Forests
- Neural networks
In unsupervised studying, the coaching knowledge is unlabeled.
Let’s say, The system tries to study with no instructor.
- Clustering
- Ok-Means
- DBSCAN
- Hierarchical Cluster Evaluation (HCA)
- Anomaly detection and novelty detection
- One-class SVM
- Isolation Forest
- Visualization and dimensionality discount
- Principal Element Evaluation (PCA)
- Kernel PCA
- Domestically Linear Embedding (LLE)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
Q63. What are some widespread strategies for hyperparameter tuning?
A. There are a number of widespread strategies for hyperparameter tuning:
- Grid Search: This includes specifying a set of values for every hyperparameter, and the mannequin is educated and evaluated utilizing a mixture of all attainable hyperparameter values. This may be computationally costly, because the variety of mixtures grows exponentially with the variety of hyperparameters.
- Random Search: This includes sampling random mixtures of hyperparameters and coaching and evaluating the mannequin for every mixture. That is much less computationally intensive than grid search, however could also be much less efficient at discovering the optimum set of hyperparameters.
Q64. How do you resolve the scale of your validation and take a look at units?
A. You may validate the scale of your take a look at units within the following methods:
- Measurement of the dataset: Typically, the bigger the dataset, the bigger the validation and take a look at units might be. It is because there’s extra knowledge to work with, so the validation and take a look at units might be extra consultant of the general dataset.
- Complexity of the mannequin: If the mannequin may be very easy, it might not require as a lot knowledge to validate and take a look at. Alternatively, if the mannequin may be very advanced, it might require extra knowledge to make sure that it’s strong and generalizes effectively to unseen knowledge.
- Degree of uncertainty: If the mannequin is predicted to carry out very effectively on the duty, the validation and take a look at units might be smaller. Nevertheless, if the efficiency of the mannequin is unsure or the duty may be very difficult, it might be useful to have bigger validation and take a look at units to get a extra correct evaluation of the mannequin’s efficiency.
- Sources obtainable: The scale of the validation and take a look at units can also be restricted by the computational sources obtainable. It will not be sensible to make use of very giant validation and take a look at units if it takes a very long time to coach and consider the mannequin.
Q65. How do you consider a mannequin’s efficiency for a multi-class classification drawback?
A. One method for evaluating a multi-class classification mannequin is to calculate a separate analysis metric for every class, after which calculate a macro or micro common. The macro common provides equal weight to all of the lessons, whereas the micro common provides extra weight to the lessons with extra observations. Moreover, some generally used metrics for multi-class classification issues resembling confusion matrix, precision, recall, F1 rating, Accuracy and ROC-AUC can be used.
Q66. What’s the distinction between Statistical studying and Machine Studying with their examples?
A. Statistical studying and machine studying are each strategies used to make predictions or selections primarily based on knowledge. Nevertheless, there are some key variations between the 2 approaches:
Statistical studying focuses on making predictions or selections primarily based on a statistical mannequin of the info. The purpose is to know the relationships between the variables within the knowledge and make predictions primarily based on these relationships. Machine studying, then again, focuses on making predictions or selections primarily based on patterns within the knowledge, with out essentially making an attempt to know the relationships between the variables.
Statistical studying strategies typically depend on sturdy assumptions in regards to the knowledge distribution, resembling normality or independence of errors. Machine studying strategies, then again, are sometimes extra strong to violations of those assumptions.
Statistical studying strategies are usually extra interpretable as a result of the statistical mannequin can be utilized to know the relationships between the variables within the knowledge. Machine studying strategies, then again, are sometimes much less interpretable, as a result of they’re primarily based on patterns within the knowledge somewhat than express relationships between variables.
For instance, linear regression is a statistical studying methodology that assumes a linear relationship between the predictor and goal variables and estimates the coefficients of the linear mannequin utilizing an optimization algorithm. Random forests is a machine studying methodology that builds an ensemble of determination bushes and makes predictions primarily based on the typical of the predictions of the person bushes.
Q67. How is normalized knowledge useful for making fashions in knowledge science?
A. Improved mannequin efficiency: Normalizing the info can enhance the efficiency of some machine studying fashions, significantly these which might be delicate to the size of the enter knowledge. For instance, normalizing the info can enhance the efficiency of algorithms resembling Ok-nearest neighbors and neural networks.
- Simpler characteristic comparability: Normalizing the info could make it simpler to check the significance of various options. With out normalization, options with giant scales can dominate the mannequin, making it troublesome to find out the relative significance of different options.
- Low-impact of outliers: Normalizing the info can cut back the influence of outliers on the mannequin, as they’re scaled down together with the remainder of the info. This will enhance the robustness of the mannequin and forestall it from being influenced by excessive values.
- Improved interpretability: Normalizing the info could make it simpler to interpret the outcomes of the mannequin, because the coefficients and have importances are all on the identical scale.
You will need to observe that normalization just isn’t all the time obligatory or useful for all fashions. It’s essential to fastidiously consider the precise traits and wishes of the info and the mannequin with the intention to decide whether or not normalization is acceptable.
Intermediate ML Interview Questions
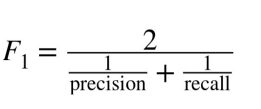
Q68. Why is the harmonic imply calculated within the f1 rating and never the imply?
A. The F1 rating is a metric that mixes precision and recall. Precision is the variety of true constructive outcomes divided by the full variety of constructive outcomes predicted by the classifier, and recall is the variety of true constructive outcomes divided by the full variety of constructive ends in the bottom reality. The harmonic imply of precision and recall is used to calculate the F1 rating as a result of it’s extra forgiving of imbalanced class proportions than the arithmetic imply.
If the harmonic means weren’t used, the F1 rating could be increased as a result of it could be primarily based on the arithmetic imply of precision and recall, which might give extra weight to the excessive precision and fewer weight to the low recall. The usage of the harmonic imply within the F1 rating helps to steadiness the precision and recall and provides a extra correct general evaluation of the classifier’s efficiency.
Q69. What are some methods to pick out options?
A. Listed here are some methods to pick out the options:
- Filter strategies: These strategies use statistical scores to pick out probably the most related options.
Instance:
- Correlation coefficient: Selects options which might be extremely correlated with the goal variable.
- Chi-squared take a look at: Selects options which might be unbiased of the goal variable.
- Wrapper strategies: These strategies use a studying algorithm to pick out the perfect options.
For instance
- Ahead choice: Begins with an empty set of options and provides one characteristic at a time till the efficiency of the mannequin is perfect.
- Backward choice: Begins with the complete set of options and removes one characteristic at a time till the efficiency of the mannequin is perfect.
- Embedded strategies: These strategies study which options are most necessary whereas the mannequin is being educated.
Instance:
- Lasso regression: Regularizes the mannequin by including a penalty time period to the loss perform that shrinks the coefficients of the much less necessary options to zero.
- Ridge regression: Regularizes the mannequin by including a penalty time period to the loss perform that shrinks the coefficients of all options in direction of zero, however doesn’t set them to zero.
- Characteristic Significance: We are able to additionally use the characteristic significance parameter which supplies us crucial options thought of by the mannequin
Q70. What’s the distinction between bagging boosting distinction?
A. Each bagging and boosting are ensemble studying methods that assist in enhancing the efficiency of the mannequin.
Bagging is the method through which totally different fashions are educated on the dataset that we’ve after which the typical of the predictions of those fashions is considered. The instinct behind taking the predictions of all of the fashions after which averaging the outcomes is making extra numerous and generalized predictions that may be extra correct.
Boosting is the method through which totally different fashions are educated however they’re educated in a sequential method. Every successive mannequin corrects the error made by the earlier mannequin. This makes the mannequin sturdy ensuing within the least error.
Q71. What’s the distinction between stochastic gradient boosting and XGboost?
A. XGBoost is an implementation of gradient boosting that’s particularly designed to be environment friendly, versatile, and moveable. Stochastic XGBoost is a variant of XGBoost that makes use of a extra randomized method to constructing determination bushes, which might make the ensuing mannequin extra strong to overfitting.
Each XGBoost and stochastic XGBoost are in style selections for constructing machine-learning fashions and can be utilized for a variety of duties, together with classification, regression, and rating. The primary distinction between the 2 is that XGBoost makes use of a deterministic tree development algorithm, whereas stochastic XGBoost makes use of a randomized tree development algorithm.
Q72. What’s the distinction between catboost and XGboost?
A. Distinction between Catboost and XGboost:
- Catboost handles categorical options higher than XGboost. In catboost, the explicit options should not required to be one-hot encoded which saves a number of time and reminiscence. XGboost then again also can deal with categorical options however they wanted to be one-hot encoded first.
- XGboost requires guide processing of the info whereas Catboost doesn’t. They’ve some variations in the way in which that they construct determination bushes and make predictions.
Catboost is quicker than XGboost and builds symmetric(balanced) bushes, in contrast to XGboost.
Q73. What’s the distinction between linear and nonlinear classifiers
A. The distinction between the linear and nonlinear classifiers is the character of the choice boundary.
In a linear classifier, the choice boundary is a linear perform of the enter. In different phrases, the boundary is a straight line, a aircraft, or a hyperplane.
ex: Linear Regression, Logistic Regression, LDA
A non-linear classifier is one through which the choice boundary just isn’t a linear perform of the enter. Because of this the classifier can’t be represented by a linear perform of the enter options. Non-linear classifiers can seize extra advanced relationships between the enter options and the label, however they can be extra susceptible to overfitting, particularly if they’ve a number of parameters.
ex: KNN, Choice Tree, Random Forest
Q74. What are parametric and nonparametric fashions?
A. A parametric mannequin is a mannequin that’s described by a hard and fast variety of parameters. These parameters are estimated from the info utilizing a most chance estimation process or another methodology, and they’re used to make predictions in regards to the response variable.
Nonparametric fashions don’t assume any particular kind for the connection between variables. They’re extra versatile than parametric fashions. They will match a greater diversity of knowledge shapes. Nevertheless, they’ve fewer interpretable parameters. This will make them tougher to know.
Q75. How can we use cross-validation to beat overfitting?
A. The cross-validation method can be utilized to establish if the mannequin is underfitting or overfitting but it surely can’t be used to beat both of the issues. We are able to solely examine the efficiency of the mannequin on two totally different units of knowledge and discover if the info is overfitting or underfitting, or generalized.
Q76. How will you convert a numerical variable to a categorical variable and when can or not it’s helpful?
A. There are a number of methods to transform a numerical variable to a categorical variable. One widespread methodology is to make use of binning, which includes dividing the numerical variable right into a set of bins or intervals and treating every bin as a separate class.
One other technique to convert a numerical variable to a categorical one is thru “discretization.” This implies dividing the vary into intervals. Every interval is then handled as a separate class. It helps create a extra detailed view of the info.
This conversion is helpful when the numerical variable has restricted values. Grouping these values could make patterns clearer. It additionally highlights tendencies as a substitute of specializing in uncooked numbers.
Q77. What are generalized linear fashions?
A. Generalized Linear Fashions are a versatile household of fashions. They describe the connection between a response variable and a number of predictors. GLMs supply extra flexibility than conventional linear fashions.
In linear fashions, the response is generally distributed. The connection with predictors is assumed to be linear. GLMs chill out these guidelines. The response can observe totally different distributions. The connection can be non-linear. Widespread GLMs embrace logistic regression for binary knowledge, Poisson regression for counts, and exponential regression for time-to-event knowledge.
Q78. What’s the distinction between ridge and lasso regression? How do they differ when it comes to their method to mannequin choice and regularization?
A. Ridge regression and lasso regression are each methods used to stop overfitting in linear fashions by including a regularization time period to the target perform. They differ in how they outline the regularization time period.
In ridge regression, the regularization time period is outlined because the sum of the squared coefficients (additionally referred to as the L2 penalty). This ends in a clean optimization floor, which might help the mannequin generalize higher to unseen knowledge. Ridge regression has the impact of driving the coefficients in direction of zero, but it surely doesn’t set any coefficients precisely to zero. Because of this all options are retained within the mannequin, however their influence on the output is diminished.
Alternatively, lasso regression defines the regularization time period because the sum of absolutely the values of the coefficients (additionally referred to as the L1 penalty). This has the impact of driving some coefficients precisely to zero, successfully deciding on a subset of the options to make use of within the mannequin. This may be helpful for characteristic choice, because it permits the mannequin to mechanically choose crucial options. Nevertheless, the optimization floor for lasso regression just isn’t clean, which might make it harder to coach the mannequin.
In abstract, ridge regression shrinks the coefficients of all options in direction of zero, whereas lasso regression units some coefficients precisely to zero. Each methods might be helpful for stopping overfitting, however they differ in how they deal with mannequin choice and regularization.
Q79.How does the step dimension (or studying charge) of an optimization algorithm influence the convergence of the optimization course of in logistic regression?
A. The step dimension, or studying charge, controls how massive the steps are throughout optimization. In logistic regression, we reduce the detrimental log-likelihood to seek out the perfect coefficients. If the step dimension is just too giant, the algorithm could overshoot the minimal. It could possibly oscillate and even diverge. If the step dimension is just too small, progress will probably be gradual. The algorithm could take a very long time to converge.
Due to this fact, you will need to select an acceptable step dimension with the intention to make sure the convergence of the optimization course of. Typically, a bigger step dimension can result in quicker convergence, but it surely additionally will increase the chance of overshooting the minimal. A smaller step dimension will probably be safer, however it should even be slower.
There are a number of approaches for selecting an acceptable step dimension. One widespread method is to make use of a hard and fast step dimension for all iterations. One other method is to make use of a lowering step dimension, which begins out giant and reduces over time. This might help the optimization algorithm to make quicker progress in the beginning after which fine-tune the coefficients because it will get nearer to the minimal.
Q80. What’s overfitting in determination bushes, and the way can or not it’s mitigated?
A. Overfitting in determination bushes happens when the mannequin is just too advanced and has too many branches, resulting in poor generalization to new, unseen knowledge. It is because the mannequin has “realized” the patterns within the coaching knowledge too effectively, and isn’t in a position to generalize these patterns to new, unseen knowledge.
There are a number of methods to mitigate overfitting in determination bushes:
- Pruning: This includes eradicating branches from the tree that don’t add vital worth to the mannequin’s predictions. Pruning might help cut back the complexity of the mannequin and enhance its generalization means.
- Limiting tree depth: By proscribing the depth of the tree, you possibly can forestall the tree from changing into too advanced and overfitting the coaching knowledge.
- Utilizing ensembles: Ensemble strategies resembling random forests and gradient boosting might help cut back overfitting by aggregating the predictions of a number of determination bushes.
- Utilizing cross-validation: By evaluating the mannequin’s efficiency on a number of train-test splits, you will get a greater estimate of the mannequin’s generalization efficiency and cut back the chance of overfitting.
Q81. Why is SVM referred to as a big margin classifier?
A. Help Vector Machine, is named a big margin classifier as a result of it seeks to discover a hyperplane with the biggest attainable margin, or distance, between the constructive and detrimental lessons within the characteristic area. The margin is the gap between the hyperplane and the closest knowledge factors, and is used to outline the choice boundary of the mannequin.
By maximizing the margin, the SVM classifier is ready to higher generalize to new, unseen knowledge and is much less susceptible to overfitting. The bigger the margin, the decrease the uncertainty across the determination boundary, and the extra assured the mannequin is in its predictions.
Due to this fact, the purpose of the SVM algorithm is to discover a hyperplane with the biggest attainable margin, which is why it’s referred to as a big margin classifier.
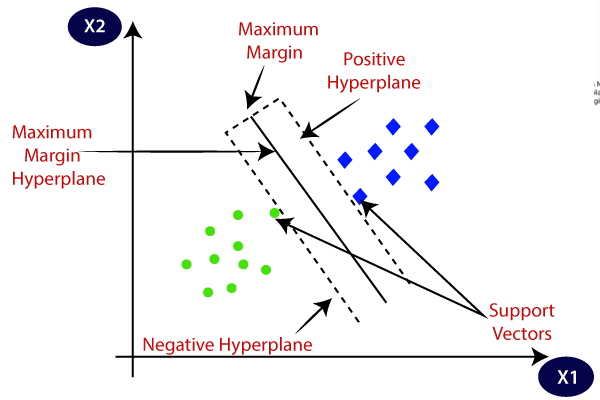
Q82. What’s hinge loss?
A. Hinge loss is a loss perform utilized in help vector machines (SVMs) and different linear classification fashions. It’s outlined because the loss that’s incurred when a prediction is wrong.
The hinge loss for a single instance is outlined as:
loss = max(0, 1 – y * f(x))
the place y is the true label (both -1 or 1) and f(x) is the expected output of the mannequin. The anticipated output is the interior product between the enter options and the mannequin weights, plus a bias time period.
Hinge loss is utilized in SVMs as a result of it’s convex. It penalizes predictions that aren’t assured and proper. The loss is zero when the prediction is appropriate. It will increase as confidence in a fallacious prediction grows. This pushes the mannequin to be assured however cautious. It discourages predictions removed from the true label.
Superior ML Interview Questions
Q83. What’s going to occur if we enhance the variety of neighbors in KNN?
A. Growing the variety of neighbors in KNN makes the classifier extra conservative. The choice boundary turns into smoother. This helps cut back overfitting. Nevertheless, it might miss refined patterns within the knowledge. A bigger okay creates a less complicated mannequin. This lowers overfitting however will increase the chance of underfitting.
To keep away from each points, choosing the proper okay is necessary. It ought to steadiness complexity and ease. It’s finest to check totally different okay values. Then, decide the one which works finest on your dataset.
Q84. What’s going to occur within the determination tree if the max depth is elevated?
A. Growing the max depth of a determination tree will enhance the complexity of the mannequin and make it extra susceptible to overfitting. If you happen to enhance the max depth of a call tree, the tree will be capable to make extra advanced and nuanced selections, which might enhance the mannequin’s means to suit the coaching knowledge effectively. Nevertheless, if the tree is just too deep, it might turn out to be overly delicate to the precise patterns within the coaching knowledge and never generalize effectively to unseen knowledge.
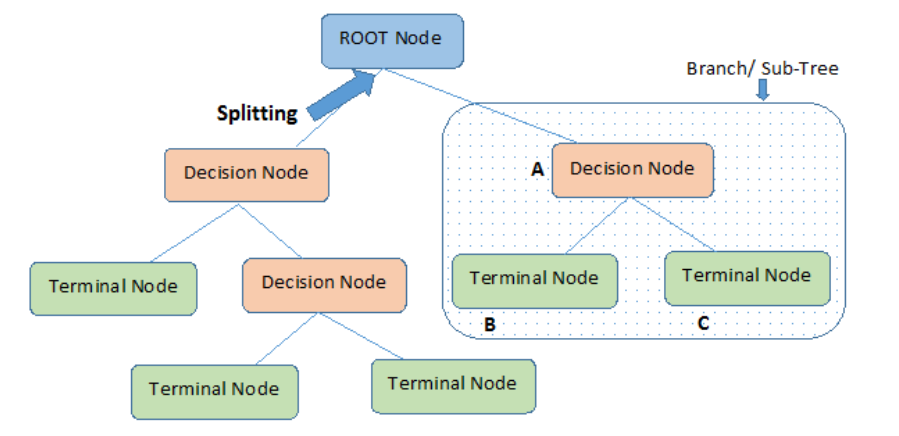
Q85. What’s the distinction between further bushes and random forests?
A. The primary distinction between the 2 algorithms is how the choice bushes are constructed.
In a Random Forest, the choice bushes are constructed utilizing bootstrapped samples of the coaching knowledge and a random subset of the options. This ends in every tree being educated on a barely totally different set of knowledge and options, resulting in a larger range of bushes and a decrease variance.
In an Further Bushes classifier, the choice bushes are constructed in an identical approach, however as a substitute of choosing a random subset of the options at every cut up, the algorithm selects the perfect cut up amongst a random subset of the options. This ends in a larger variety of random splits and the next diploma of randomness, resulting in a decrease bias and the next variance.
Q86. When to make use of one-hot encoding and label encoding?
A. One-hot encoding and label encoding are two totally different methods that can be utilized to encode categorical variables as numerical values. They’re typically utilized in machine studying fashions as a preprocessing step earlier than becoming the mannequin to the info.
One-hot encoding is used for categorical variables with none pure order. It creates binary columns for every class, utilizing 1 for presence and 0 for absence, serving to protect uniqueness and keep away from false ordinal assumptions. Label encoding is used when classes have a pure order, assigning every a singular integer to mirror that order. One-hot fits nominal knowledge, whereas label encoding suits ordinal knowledge, although the ultimate alternative will depend on the mannequin and dataset.
Q87. What’s the drawback with utilizing label encoding for nominal knowledge?
A. Label encoding is a technique of encoding categorical variables as numerical values, which might be useful in sure conditions. Nevertheless, there are some potential issues that you have to be conscious of when utilizing label encoding for nominal knowledge.
One drawback with label encoding is that it may possibly create an ordinal relationship between classes the place none exists
In case you have a categorical variable with three classes: “purple”, “inexperienced”, and “blue”, and also you apply label encoding to map these classes to numerical values 0, 1, and a couple of, the mannequin could assume that the class “inexperienced” is one way or the other “between” the classes “purple” and “blue”. This generally is a drawback in case your mannequin will depend on the belief that the classes are unbiased of each other.
One other drawback with label encoding is that it may possibly result in sudden outcomes if in case you have an imbalanced dataset. For instance, if one class is rather more widespread than the others, it is going to be assigned a a lot decrease numerical worth, which could lead on the mannequin to provide it much less significance than it deserves.
Q88. When can one-hot encoding be an issue?
A. One-hot encoding generally is a drawback in sure conditions as a result of it may possibly create a lot of new columns within the dataset, which might make the info harder to work with and doubtlessly result in overfitting.
One-hot encoding creates a brand new binary column for every class in a categorical variable. In case you have a categorical variable with many classes, this may end up in a really giant variety of new columns.
One other drawback with one-hot encoding is that it may possibly result in overfitting. Especifically if in case you have a small dataset and a lot of classes. While you create many new columns for every class, you might be successfully rising the variety of options within the dataset. This will result in overfitting, as a result of the mannequin could possibly memorize the coaching knowledge, but it surely won’t generalize effectively to new knowledge.
Lastly, one-hot encoding can be an issue if you want to add new classes to the dataset sooner or later. In case you have already one-hot encoded the prevailing classes. Guarantee new classes are added clearly to keep away from confusion or sudden outcomes.
Q89. What might be an acceptable encoding method when you’ve tons of of categorical values in a column?
A. Just a few methods can be utilized when we’ve tons of of columns in a categorical variable.
Frequency encoding: This includes changing every class with the frequency of that class within the dataset. This will work effectively if the classes have a pure ordinal relationship primarily based on their frequency.
Goal encoding: This includes changing every class with the imply of the goal variable for that class. This may be efficient if the classes have a transparent relationship with the goal variable.
Q90. What are the sources of randomness in random forest ?
A. Random forests are an ensemble studying methodology that includes coaching a number of determination bushes on totally different subsets of the info and averaging the predictions of the person bushes to make a closing prediction. There are a number of sources of randomness within the course of of coaching a random forest:
- Bootstrapped samples: When coaching every determination tree, the algorithm creates a bootstrapped pattern of the info by sampling with substitute from the unique coaching set. Because of this some knowledge factors will probably be included within the pattern a number of instances. While others won’t be included in any respect. This creates variation between the coaching units of various bushes.
- Random characteristic choice: When coaching every determination tree, the algorithm selects a random subset of the options to think about at every cut up. Because of this totally different bushes will take into account totally different units of options, resulting in variation within the realized bushes.
- Random threshold choice: When coaching every determination tree, the algorithm selects a random threshold for every characteristic to find out the optimum cut up. Because of this totally different bushes will cut up on totally different thresholds, resulting in variation within the realized bushes.
Q91. How do you resolve which characteristic to separate on at every node of the tree?
A. When coaching a call tree, the algorithm should select the characteristic to separate on at every node of the tree. There are a number of methods that can be utilized to resolve which characteristic to separate on, together with:
- Grasping search: The algorithm selects the characteristic that maximizes a splitting criterion (resembling info achieve or Gini impurity) at every step.
- Random Search: The algorithm selects the characteristic to separate on at random at every step.
- Exhaustive search: The algorithm considers all attainable splits and selects the one which maximizes the splitting criterion.
- Ahead search: The algorithm begins with an empty tree and provides splits one after the other, deciding on the cut up that maximizes the splitting criterion at every step.
- Backward search: The algorithm begins with a completely grown tree and prunes cut up one after the other, deciding on the cut up to take away that ends in the smallest lower within the splitting criterion.
Q92. What’s the significance of C in SVM?
A. Within the help vector machine (SVM) algorithm, the parameter C is a hyperparameter that controls the trade-off between maximizing the margin and minimizing the misclassification error.
C controls the penalty for misclassifying coaching examples. A smaller C means the next penalty. The mannequin tries to categorise all examples accurately, even with a smaller margin. A bigger C means a decrease penalty. The mannequin permits some misclassifications to get a bigger margin.
In observe, you possibly can consider C as controlling the flexibleness of the mannequin. A smaller worth of C will end in a extra inflexible mannequin which may be extra susceptible to underfitting, whereas a bigger worth of C will end in a extra versatile mannequin which may be extra susceptible to overfitting.
Select C fastidiously utilizing cross-validation to steadiness bias-variance and guarantee good efficiency on unseen knowledge.
Q93. How do c and gamma have an effect on overfitting in SVM?
A. In help vector machines (SVMs), the regularization parameter C and the kernel parameter gamma are used to regulate overfitting.
C is the penalty for misclassification. A smaller worth of C means a bigger penalty for misclassification. The mannequin turns into extra conservative. It tries tougher to keep away from errors. This will cut back overfitting. Nevertheless, it might additionally make the mannequin too cautious. In consequence, generalization efficiency would possibly endure.
Gamma is a parameter that controls the complexity of the mannequin. A smaller worth of gamma means a extra advanced mannequin, which might result in overfitting. A bigger worth of gamma means a less complicated mannequin, which might help forestall overfitting however can also end in a mannequin that’s too easy to precisely seize the underlying relationships within the knowledge.
Discovering the perfect values for C and gamma is a steadiness between bias and variance. It normally requires testing totally different values. The mannequin’s efficiency needs to be checked on a validation set. This helps establish the perfect parameter settings.
Q94. How do you select the variety of fashions to make use of in a Boosting or Bagging ensemble?
A. The variety of fashions to make use of in an ensemble is normally decided by the trade-off between efficiency and computational price. As a basic rule of thumb, rising the variety of fashions will enhance the efficiency of the ensemble, however at the price of rising the computational price.
In observe, the variety of fashions is decided by Cross validation which is used to find out the optimum variety of fashions primarily based on the analysis metric chosen.
Q95. Through which situations Boosting and Bagging are most well-liked over single fashions?
A. Each boosting and bagging are used to enhance mannequin efficiency. They assist when particular person fashions have excessive variance or excessive bias. Bagging reduces the variance of a mannequin. Boosting reduces bias and improves generalization error. Each strategies are helpful for fashions which might be delicate to coaching knowledge. Additionally they assist when there’s a excessive threat of overfitting.
Q96. Are you able to clarify the ROC curve and AUC rating and the way they’re used to guage a mannequin’s efficiency?
A. A ROC (Receiver Working Attribute) curve is a graphical illustration of the efficiency of a binary classification mannequin. It plots the true constructive charge (TPR) towards the false constructive charge (FPR) at totally different thresholds. AUC (Space Below the Curve) is the realm beneath the ROC curve. It provides a single quantity that represents the mannequin’s general efficiency. AUC is helpful as a result of it considers all attainable thresholds, not only a single level on the ROC curve.
Q97. How do you method setting the edge in a binary classification drawback while you need to alter precision and recall by your self?
A. When setting the edge in a binary classification drawback, it’s necessary to think about the trade-off between precision and recall. Precision is the ratio of true positives to all predicted positives. Recall is the ratio of true positives to all precise positives. To regulate these metrics, first prepare the mannequin and consider it on a validation set. This set ought to have an identical distribution to the take a look at knowledge. Then, use a confusion matrix to visualise efficiency. It reveals true positives, false positives, true negatives, and false negatives. This helps establish the present prediction threshold.
As soon as you recognize the edge, you possibly can alter it to steadiness precision and recall. Growing the edge boosts precision however lowers recall. Lowering it raises recall however reduces precision. At all times take into account the precise use case. In medical prognosis, excessive recall is important to catch all positives. In fraud detection, excessive precision is vital to keep away from false alarms. The precise steadiness will depend on the price of false positives and false negatives in your situation.
Q98. What’s the distinction between LDA (Linear Discriminant Evaluation) and PCA (Principal Element Evaluation)?
A. The distinction between LDA (Linear Discriminant Evaluation) and PCA (Principal Element Evaluation) are:
| Characteristic | PCA (Principal Element Evaluation) | LDA (Linear Discriminant Evaluation) |
|---|---|---|
| Kind | Unsupervised | Supervised |
| Goal | Discover instructions of most variance within the knowledge | Maximize class separability |
| Use Case | Sample discovery, knowledge compression | Classification duties (e.g., face, iris, fingerprint recognition) |
| Primarily based On | Variance in knowledge | Labels and sophistication distribution |
| Parts | Principal parts (orthogonal instructions of most variance) | Linear discriminants (instructions that finest separate lessons) |
| Knowledge Projection | Tasks knowledge onto instructions of highest variance | Tasks knowledge onto instructions that finest separate the lessons |
| Orthogonality | Parts are mutually orthogonal | Parts should not essentially orthogonal |
| Output | Decrease-dimensional subspace preserving most variance | Decrease-dimensional subspace maximizing class discrimination |
Q99. How does the Naive Bayes algorithm examine to different supervised studying algorithms?
A. Naive Bayes is a straightforward and quick algorithm that works effectively with high-dimensional knowledge and small coaching units. It additionally performs effectively on datasets with categorical variables and lacking knowledge, that are widespread in lots of real-world issues. It’s good for textual content classification, spam filtering, and sentiment evaluation. Nevertheless, as a result of assumption of independence amongst options, it doesn’t carry out good for issues having excessive correlation amongst options. It additionally typically fails to seize the interactions amongst options, which may end up in poor efficiency on some datasets. Due to this fact, it’s typically used as a baseline or place to begin, after which different algorithms like SVM, and Random Forest can be utilized to enhance the efficiency.
Q100. Are you able to clarify the idea of the “kernel trick” and its software in Help Vector Machines (SVMs)?
A. The kernel trick is a method utilized in SVMs. It transforms enter knowledge right into a higher-dimensional characteristic area. This makes the info linearly separable. The trick replaces the usual interior product with a kernel perform. The kernel computes the interior product in a higher-dimensional area. It does this with out calculating the precise coordinates. This helps SVMs deal with non-linearly separable knowledge. Widespread kernel features embrace the polynomial kernel, RBF kernel, and sigmoid kernel.
Listed here are just a few extra sources which will probably be useful so that you can crack your knowledge science interview:
Conclusion
On this article, we coated varied knowledge science interview questions that cowl subjects resembling KNN, linear regression, naive bayes, random forest, and so forth.
Hope you just like the article and get understanding for high 100 knowledge science interview questions. On these knowledge science interview preparation will enable you to with cracking interviews. On this article, knowledge science interview questions for freshers and these interview questions enable you to to crack the info scientist interview questions that can ready that will help you to get knowledge scientist jobs.
The work of knowledge scientists just isn’t simple, however it’s rewarding, and there are numerous open positions. These knowledge science interview questions can get you one step nearer to touchdown your ideally suited job. So, brace your self for the pains of interview questions and maintain present on the basics of knowledge science. If you wish to enhance your knowledge science abilities, then take into account signing up for our Blackbelt program.
Login to proceed studying and revel in expert-curated content material.