
AWS AppSync Occasions will help you create safer, scalable Websocket APIs. Along with broadcasting real-time occasions to thousands and thousands of Websocket subscribers, it helps an important person expertise requirement of your AI Gateway: low-latency propagation of occasions out of your chosen generative AI fashions to particular person customers.
On this put up, we talk about tips on how to use AppSync Occasions as the muse of a succesful, serverless, AI gateway structure. We discover the way it integrates with AWS companies for complete protection of the capabilities provided in AI gateway architectures. Lastly, we get you began in your journey with pattern code you possibly can launch in your account and start constructing.
Overview of AI Gateway
AI Gateway is an architectural middleware sample that helps improve the provision, safety, and observability of huge language fashions (LLMs). It helps the pursuits of a number of totally different personas. For instance, customers need low latency and pleasant experiences. Builders need versatile and extensible architectures. Safety employees want governance to guard info and availability. System engineers want monitoring and observability options that assist them assist the person expertise. Product managers want details about how properly their merchandise carry out with customers. Price range managers want value controls. The wants of those totally different folks throughout your group are essential concerns for internet hosting generative AI purposes.
Resolution overview
The answer we share on this put up provides the next capabilities:
- Id – Authenticate and authorize customers from the built-in person listing, out of your enterprise listing, and from client id suppliers like Amazon, Google, and Fb
- APIs – Present customers and purposes low-latency entry to your generative AI purposes
- Authorization – Decide what sources your customers have entry to in your utility
- Price limiting and metering – Mitigate bot site visitors, block entry, and handle mannequin consumption to handle value
- Various mannequin entry – Supply entry to main basis fashions (FMs), brokers, and safeguards to maintain customers protected
- Logging – Observe, troubleshoot, and analyze utility conduct
- Analytics – Extract worth out of your logs to construct, uncover, and share significant insights
- Monitoring – Observe key datapoints that assist employees react shortly to occasions
- Caching – Scale back prices by detecting widespread queries to your fashions and returned predetermined responses
Within the following sections, we dive into the core structure and discover how one can construct these capabilities into the answer.
Id and APIs
The next diagram illustrates an structure utilizing the AppSync Occasions API to offer an interface between an AI assistant utility and LLMs by Amazon Bedrock utilizing AWS Lambda.
The workflow consists of the next steps:
- The shopper utility retrieves the person id and authorization to entry APIs utilizing Amazon Cognito.
- The shopper utility subscribes to the AppSync Occasions channel, from which it’s going to obtain occasions like streaming responses from the LLMs in Amazon Bedrock.
- The
SubscribeHandlerLambda perform connected to the Outbound Messages namespace verifies that this person is allowed to entry the channel. - The shopper utility publishes a message to the Inbound Message channel, comparable to a query posed to the LLM.
- The
ChatHandlerLambda perform receives the message and verifies the person is allowed to publish messages on that channel. - The
ChatHandlerperform calls the Amazon Bedrock ConverseStream API and waits for the response stream from the Converse API to emit response occasions. - The
ChatHandlerperform relays the response messages from the Converse API to the Outbound Message channel for the present person, which passes the occasions to the WebSocket on which the shopper utility is ready for messages.
AppSync Occasions namespaces and channels are the constructing blocks of your communications structure in your AI Gateway. Within the instance, namespaces are used to connect totally different behaviors to our inbound and outbound messages. Every namespace can have totally different publish and subscribe integration to every namespace. Furthermore, every namespace is split into channels. Our channel construction design offers every person a non-public inbound and outbound channel, serving as one-to-one communications with the server aspect:
Inbound-Messages / ${sub}Outbound-Messages / ${sub}
The topic, or sub attribute, arrives in our Lambda features as context from Amazon Cognito. It’s an unchangeable, distinctive person identifier inside every person pool. This makes it helpful for segments of our channel names and is particularly helpful for authorization.
Authorization
Id is established utilizing Amazon Cognito, however we nonetheless must implement authorization. One-to-one communication between a person and an AI assistant in our instance needs to be non-public—we don’t need customers with the data of one other person’s sub attribute to have the ability to subscribe to or publish to a different person’s inbound or outbound channel.
Because of this we use sub in our naming scheme for channels. This allows the Lambda features connected to the namespaces as information sources to confirm {that a} person is allowed to publish and subscribe.
The next code pattern is our SubscribeHandler Lambda perform:
The perform workflow consists of the next steps:
- The title of the channel arrives within the occasion.
- The person’s topic subject,
sub, is a part of the context. - If the channel title and person id don’t match, it doesn’t authorize the subscription and returns an error message.
- Returning
Nonesignifies no errors and that the subscription is allowed.
The ChatHandler Lambda perform makes use of the identical logic to verify customers are solely approved to publish to their very own inbound channel. The channel arrives within the occasion and the context carries the person id.
Though our instance is easy, it demonstrates how one can implement complicated authorization guidelines utilizing a Lambda perform to authorize entry to channels in AppSync Occasions.We’ve got lined entry management to a person’s inbound and outbound channels. Many enterprise fashions round entry to LLMs contain controlling what number of tokens a person is allowed to make use of inside some time period. We talk about this functionality within the following part.
Price limiting and metering
Understanding and controlling the variety of tokens consumed by customers of an AI Gateway is essential to many purchasers. Enter and output tokens are the first pricing mechanism for text-based LLMs in Amazon Bedrock. In our instance, we use the Amazon Bedrock Converse API to entry LLMs. The Converse API offers a constant interface that works with the fashions that assist messages. You possibly can write code one time and use it with totally different fashions.
A part of the constant interface is the stream metadata occasion. This occasion is emitted on the finish of every stream and offers the variety of tokens consumed by the stream. The next is an instance JSON construction:
We’ve got enter tokens, output tokens, complete tokens, and a latency metric. To create a management with this information, we first think about the varieties of limits we need to implement. One method is a month-to-month token restrict that resets each month—a static window. One other is a each day restrict based mostly on a rolling window on 10-minute intervals. When a person exceeds their month-to-month restrict, they have to wait till the following month. After a person exceeds their each day rolling window restrict, they have to wait 10 minutes for extra tokens to turn into accessible.
We want a solution to preserve atomic counters to trace the token consumption, with quick real-time entry to the counters with the person’s sub, and to delete previous counters as they turn into irrelevant.
Amazon DynamoDB is a serverless, absolutely managed, distributed NoSQL database with single-digit millisecond efficiency at many scales. With DynamoDB, we will preserve atomic counters, present entry to the counters keyed by the sub, and roll off previous information utilizing its time to dwell function. The next diagram exhibits a subset of our structure from earlier on this put up that now features a DynamoDB desk to trace token utilization.
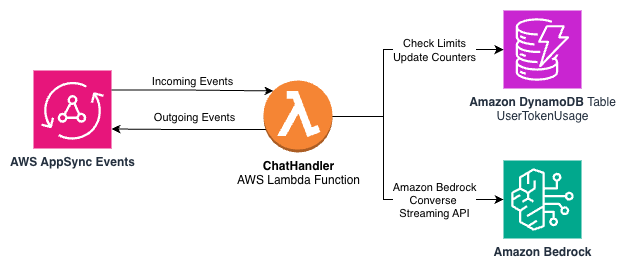
We will use a single DynamoDB desk with the next partition and type keys:
- Partition key –
user_id(String), the distinctive identifier for the person - Type key –
period_id(String), a composite key that identifies the time interval
The user_id will obtain the sub attribute from the JWT supplied by Amazon Cognito. The period_id could have strings that kind lexicographically that point out which era interval the counter is for in addition to the timeframe. The next are some instance kind keys:
10min or month-to-month point out the kind of counter. The timestamp is ready to the final 10-minute window (for instance, (minute // 10) * 10).
With every file, we preserve the next attributes:
input_tokens– Counter for enter tokens used on this 10-minute windowoutput_tokens– Counter for output tokens used on this 10-minute windowtimestamp– Unix timestamp when the file was created or final up to datettl– Time to dwell worth (Unix timestamp), set to 24 hours from creation
The 2 token columns are incremented with the DynamoDB atomic ADD operation with every metadata occasion from the Amazon Bedrock Converse API. The ttl and timestamp columns are up to date to point when the file is robotically faraway from the desk.
When a person sends a message, we test whether or not they have exceeded their each day or month-to-month limits.
To calculate each day utilization, the meter.py module completes the next steps:
- Calculates the beginning and finish keys for the 24-hour window.
- Queries information with the partition key
user_idand type key between the beginning and finish keys. - Sums up the
input_tokensandoutput_tokensvalues from the matching information. - Compares the sums towards the each day limits.
See the next instance code:
This vary question takes benefit of the naturally sorted keys to effectively retrieve solely the information from the final 24 hours, with out filtering within the utility code.The month-to-month utilization calculation on the static window is way less complicated. To test month-to-month utilization, the system completes the next steps:
- Will get the particular file with the partition key
user_idand type keymonth-to-month:YYYY-MMfor the present month. - Compares the
input_tokensandoutput_tokensvalues towards the month-to-month limits.
See the next code:
With a further Python module and DynamoDB, now we have a metering and charge limiting answer that works for each static and rolling home windows.
Various mannequin entry
Our pattern code makes use of the Amazon Bedrock Converse API. Not each mannequin is included within the pattern code, however many fashions are included so that you can quickly discover potentialities.The innovation on this space doesn’t cease at fashions on AWS. There are quite a few methods to develop generative AI options at each stage of abstraction. You possibly can construct on high of the layer that most accurately fits your use case.
Swami Sivasubramanian not too long ago wrote on how AWS is enabling clients to ship production-ready AI brokers at scale. He discusses Strands Brokers, an open supply AI brokers SDK, in addition to Amazon Bedrock AgentCore, a complete set of enterprise-grade companies that assist builders shortly and extra securely deploy and function AI brokers at scale utilizing a framework and mannequin, hosted on Amazon Bedrock or elsewhere.
To study extra about architectures for AI brokers, seek advice from Strands Brokers SDK: A technical deep dive into agent architectures and observability. The put up discusses the Strands Brokers SDK and its core options, the way it integrates with AWS environments for safer, scalable deployments, and the way it offers wealthy observability for manufacturing use. It additionally offers sensible use circumstances and a step-by-step instance.
Logging
A lot of our AI Gateway stakeholders are fascinated about logs. Builders need to perceive how their purposes perform. System engineers want to know operational considerations like monitoring availability and capability planning. Enterprise house owners need analytics and tendencies in order that they will make higher selections.
With Amazon CloudWatch Logs, you possibly can centralize the logs out of your totally different techniques, purposes, and AWS companies that you just use in a single, extremely scalable service. You possibly can then seamlessly view them, search them for particular error codes or patterns, filter them based mostly on particular fields, or archive them securely for future evaluation. CloudWatch Logs makes it potential to see your logs, no matter their supply, as a single and constant movement of occasions ordered by time.
Within the pattern AI Gateway structure, CloudWatch Logs is built-in at a number of ranges to offer complete visibility. The next structure diagram depicts the combination factors between AppSync Occasions, Lambda, and CloudWatch Logs within the pattern utility.
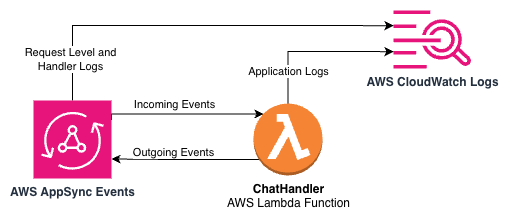
AppSync Occasions API logging
Our AppSync Occasions API is configured with ERROR-level logging to seize API-level points. This configuration helps determine points with API requests, authentication failures, and different essential API-level issues.The logging configuration is utilized in the course of the infrastructure deployment:
This offers visibility into API operations.
Lambda perform structured logging
The Lambda features use AWS Lambda Powertools for structured logging. The ChatHandler Lambda perform implements a MessageTracker class that gives context for every dialog:
Key info logged contains:
- Person identifiers
- Dialog identifiers for request tracing
- Mannequin identifiers to trace which AI fashions are getting used
- Token consumption metrics (enter and output counts)
- Message previews
- Detailed timestamps for time-series evaluation
Every Lambda perform units a correlation ID for request tracing, making it easy to observe a single request by the system:
Operational insights
CloudWatch Logs Insights allows SQL-like queries throughout log information, serving to you carry out the next actions:
- Observe token utilization patterns by mannequin or person
- Monitor response instances and determine efficiency bottlenecks
- Detect error patterns and troubleshoot points
- Create customized metrics and alarms based mostly on log information
By implementing complete logging all through the pattern AI Gateway structure, we offer the visibility wanted for efficient troubleshooting, efficiency optimization, and operational monitoring. This logging infrastructure serves as the muse for each operational monitoring and the analytics capabilities we talk about within the following part.
Analytics
CloudWatch Logs offers operational visibility, however for extracting enterprise intelligence from logs, AWS provides many analytics companies. With our pattern AI Gateway structure, you need to use these companies to rework information out of your AI Gateway with out requiring devoted infrastructure or complicated information pipelines.
The next structure diagram exhibits the movement of knowledge between the Lambda perform, Amazon Information Firehose, Amazon Easy Storage Service (Amazon S3), the AWS Glue Information Catalog, and Amazon Athena.
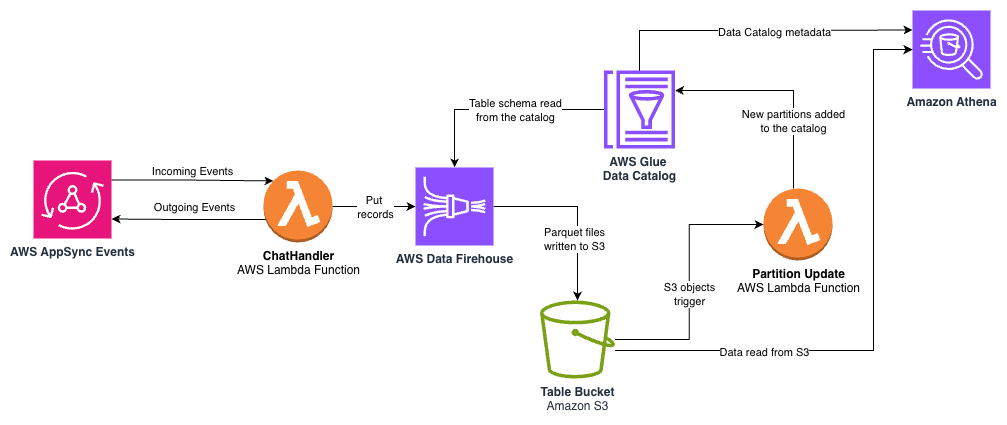
The important thing parts embrace:
- Information Firehose – The
ChatHandlerLambda perform streams structured log information to a Firehose supply stream on the finish of every accomplished person response. Information Firehose offers a totally managed service that robotically scales together with your information throughput, assuaging the necessity to provision or handle infrastructure. The next code illustrates how the API name that integrates theChatHandlerLambda perform with the supply stream:
- Amazon S3 with Parquet format – Firehose robotically converts the JSON log information to columnar Parquet format earlier than storing it in Amazon S3. Parquet improves question efficiency and reduces storage prices in comparison with uncooked JSON logs. The info is partitioned by yr, month, and day, enabling environment friendly querying of particular time ranges whereas minimizing the quantity of knowledge scanned throughout queries.
- AWS Glue Information Catalog – An AWS Glue database and desk are created within the AWS Cloud Growth Equipment (AWS CDK) utility to outline the schema for our analytics information, together with
user_id,conversation_id,model_id, token counts, and timestamps. Desk partitions are added as new S3 objects are saved by Information Firehose. - Athena for SQL-based evaluation – With the desk within the Information Catalog, enterprise analysts can use acquainted SQL by Athena to extract insights. Athena is serverless and priced per question based mostly on the quantity of knowledge scanned, making it an economical answer for one-time evaluation with out requiring database infrastructure. The next is an instance question:
This serverless analytics pipeline transforms the occasions flowing by AppSync Occasions into structured, queryable tables with minimal operational overhead. The pay-as-you-go pricing mannequin of those companies facilitates cost-efficiency, and their managed nature alleviates the necessity for infrastructure provisioning and upkeep. Moreover, together with your information cataloged in AWS Glue, you need to use the complete suite of analytics and machine studying companies on AWS comparable to Amazon Fast Sight and Amazon SageMaker Unified Studio together with your information.
Monitoring
AppSync Occasions and Lambda features ship metrics to CloudWatch so you possibly can monitor efficiency, troubleshoot points, and optimize your AWS AppSync API operations successfully. For an AI Gateway, you would possibly want extra info in your monitoring system to trace essential metrics comparable to token consumption out of your fashions.
The pattern utility features a name to CloudWatch metrics to file the token consumption and LLM latency on the finish of every dialog flip so operators have visibility into this information in actual time. This allows metrics to be included in dashboards and alerts. Furthermore, the metric information contains the LLM mannequin identifier as a dimension so you possibly can monitor token consumption and latency by mannequin. Metrics are only one part of what we will find out about our utility at runtime with CloudWatch. As a result of our log messages are formatted as JSON, we will carry out analytics on our log information for monitoring utilizing CloudWatch Logs Insights. The next structure diagram illustrates the logs and metrics made accessible by AppSync Occasions and Lambda by CloudWatch and CloudWatch Logs Insights.
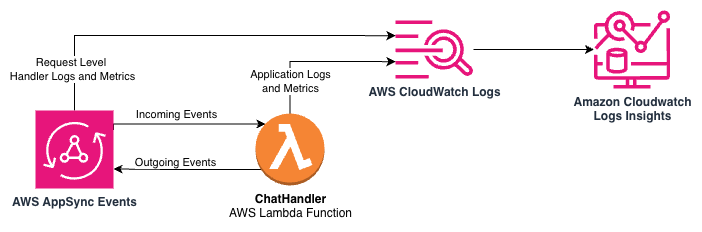
For instance, the next question towards the pattern utility’s log teams exhibits us the customers with essentially the most conversations inside a given time window:
@timestamp and @message are commonplace fields for Lambda logs. On line 3, we compute the variety of distinctive dialog identifiers for every person. Due to the JSON formatting of the messages, we don’t want to offer parsing directions to learn these fields. The Message full log message is present in packages/eventhandlers/eventhandlers/messages.py within the pattern utility.
The next question instance exhibits the variety of distinctive customers utilizing the system for a given window:
Once more, we filter for Message full, compute distinctive statistics on the user_id subject from our JSON messages, after which emit the information as a time collection with 5-minute intervals with the bin perform.
Caching (ready responses)
Many AI Gateways present a cache mechanism for assistant messages. This may be acceptable in conditions the place massive numbers of customers ask precisely the identical questions and want the identical actual solutions. This might be a substantial value financial savings for a busy utility in the precise state of affairs. A superb candidate for caching is perhaps concerning the climate. For instance, with the query “Is it going to rain in NYC as we speak?”, everybody ought to see the identical response. A nasty candidate for caching could be one the place the person would possibly ask the identical factor however would obtain non-public info in return, comparable to “What number of trip hours do I’ve proper now?” Take care to make use of this concept safely in your space of labor. A fundamental cache implementation is included within the pattern that will help you get began with this mechanism. Caches in conversational AI require loads of care to be taken to verify info doesn’t leak between customers. Given the quantity of context an LLM can use to tailor a response, caches needs to be used judiciously.
The next structure diagram exhibits the usage of DynamoDB as a storage mechanism for ready responses within the pattern utility.
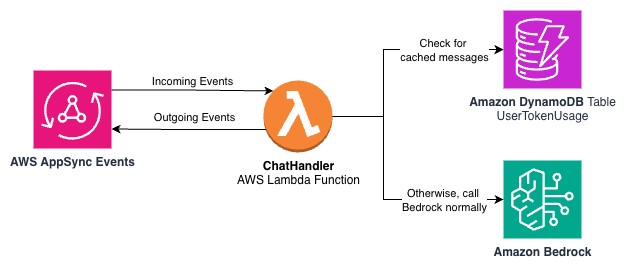
The pattern utility computes a hash on the person message to question a DynamoDB desk with saved messages. If there’s a message accessible for a hash key, the appliance returns the textual content to the person, the customized metrics file a cache hit in CloudWatch, and an occasion is handed again to AppSync Occasions to inform the appliance the response is full. This encapsulates the cache conduct fully throughout the occasion construction the appliance understands.
Set up the pattern utility
Discuss with the README file on GitHub for directions to put in the pattern utility. Each set up and uninstall are pushed by a single command to deploy or un-deploy the AWS CDK utility.
Pattern pricing
The next desk estimates month-to-month prices of the pattern utility with gentle utilization in a improvement surroundings. Precise value will differ by how you utilize the companies on your use case.
The month-to-month value of the pattern utility, assuming gentle improvement use, is anticipated to be between $35–55 per 30 days.
Pattern UI
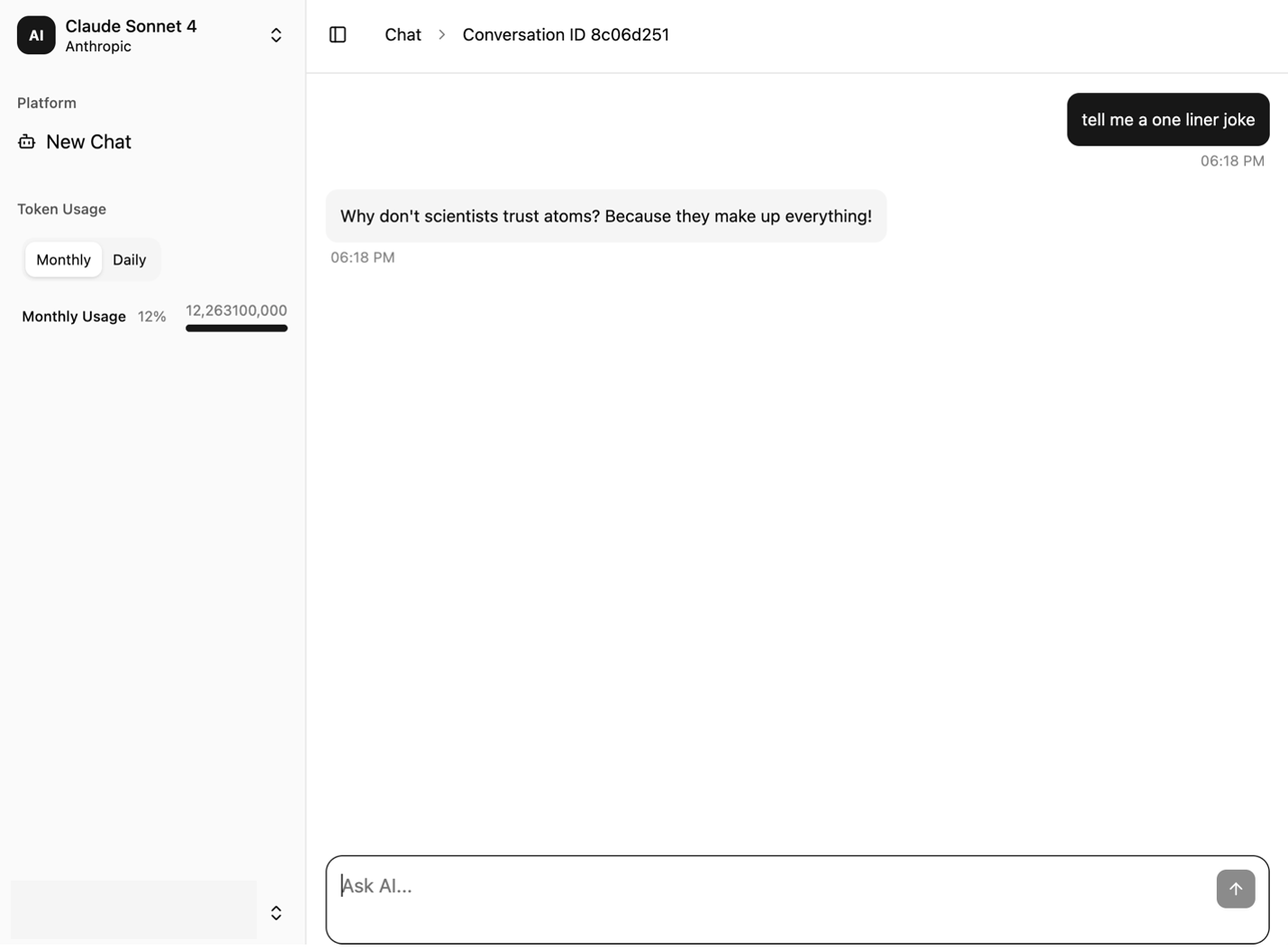
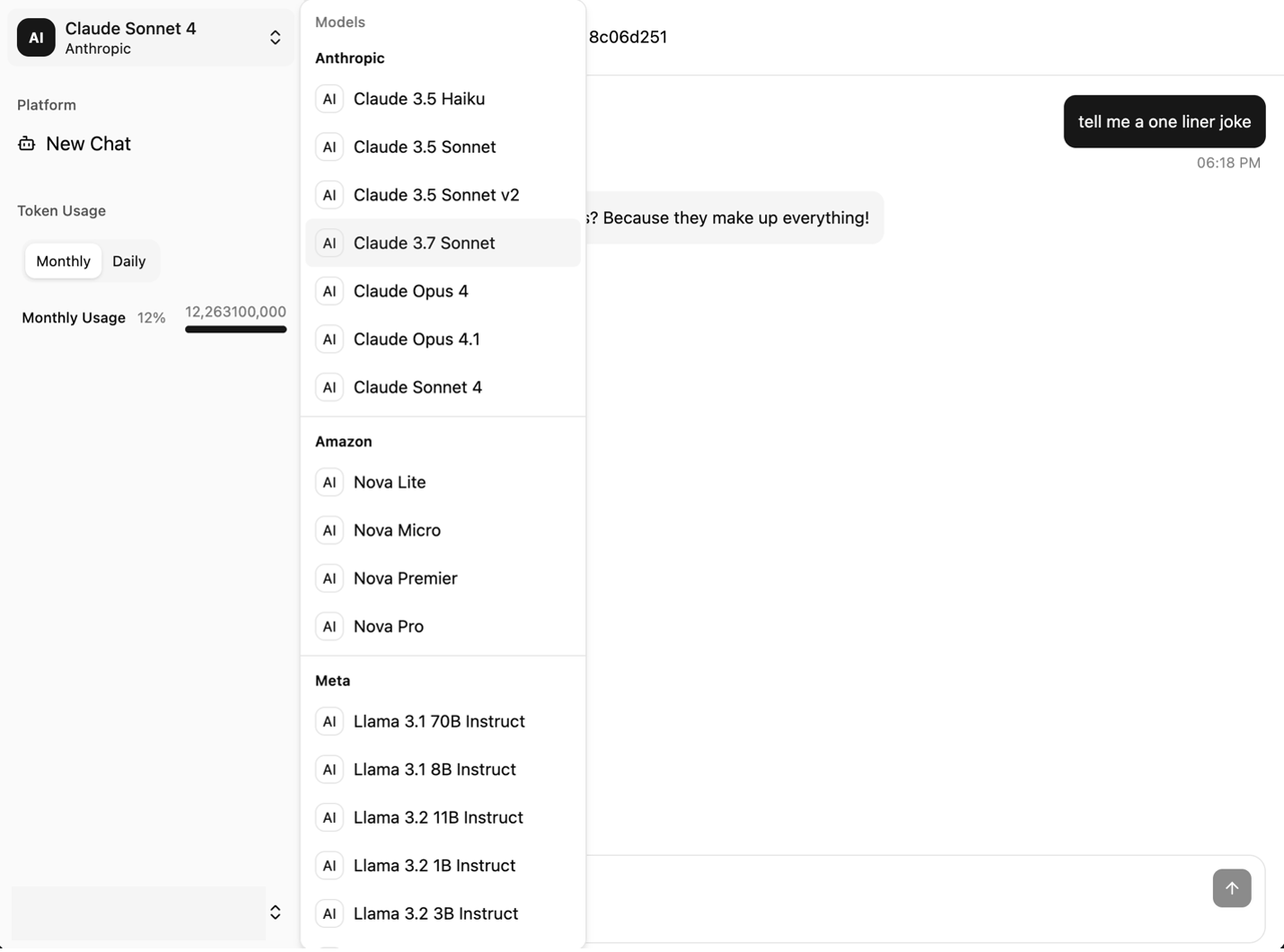
The next screenshots showcase the pattern UI. It offers a dialog window on the precise and a navigation bar on the left. The UI options the next key parts:
- A Token Utilization part is displayed and up to date with every flip of the dialog
- The New Chat possibility clears the messages from the chat interface so the person can begin a brand new session

- The mannequin selector dropdown menu exhibits the accessible fashions
The next screenshot exhibits the chat interface of the pattern utility.
The next screenshot exhibits the mannequin choice menu.
Conclusion
Because the AI panorama evolves, you want an infrastructure that adapts as shortly because the fashions themselves. By centering your structure round AppSync Occasions and the serverless patterns we’ve lined—together with Amazon Cognito based mostly id authentication, DynamoDB powered metering, CloudWatch observability, and Athena analytics—you possibly can construct a basis that grows together with your wants. The pattern utility introduced on this put up offers you a place to begin that demonstrates real-world patterns, serving to builders discover AI integration, architects design enterprise options, and technical leaders consider approaches.
The whole supply code and deployment directions can be found within the GitHub repo. To get began, deploy the pattern utility and discover the 9 architectures in motion. You possibly can customise the authorization logic to match your group’s necessities and lengthen the mannequin choice to incorporate your most well-liked fashions on Amazon Bedrock. Share your implementation insights together with your group, and go away your suggestions and questions within the feedback.
Concerning the authors

Archie Cowan is a Senior Prototype Developer on the AWS Industries Prototyping and Cloud Engineering group. He joined AWS in 2022 and has developed software program for corporations in Automotive, Power, Know-how, and Life Sciences industries. Earlier than AWS, he led the structure group at ITHAKA, the place he made contributions to the search engine on jstor.org and a manufacturing deployment velocity improve from 12 to 10,000 releases per yr over the course of his tenure there. You’ll find extra of his writing on subjects comparable to coding with ai at fnjoin.com and x.com/archiecowan.