
Picture by Editor
# Introduction
Getting labeled knowledge — that’s, knowledge with ground-truth goal labels — is a elementary step for constructing most supervised machine studying fashions like random forests, logistic regression, or neural network-based classifiers. Although one main issue in lots of real-world functions lies in acquiring a enough quantity of labeled knowledge, there are occasions when, even after having checked that field, there may nonetheless be yet another necessary problem: class imbalance.
Class imbalance happens when a labeled dataset comprises courses with very disparate numbers of observations, normally with a number of courses vastly underrepresented. This concern usually provides rise to issues when constructing a machine studying mannequin. Put one other method, coaching a predictive mannequin like a classifier on imbalanced knowledge yields points like biased choice boundaries, poor recall on the minority class, and misleadingly excessive accuracy, which in observe means the mannequin performs effectively “on paper” however, as soon as deployed, fails in vital circumstances we care about most — fraud detection in financial institution transactions is a transparent instance of this, with transaction datasets being extraordinarily imbalanced attributable to about 99% of transactions being authentic.
Artificial Minority Over-sampling Method (SMOTE) is a data-focused resampling method to sort out this concern by synthetically producing new samples belonging to the minority class, e.g. fraudulent transactions, through interpolation methods between present actual cases.
This text briefly introduces SMOTE and subsequently places the lens on explaining how you can apply it accurately, why it’s usually used incorrectly, and how you can keep away from these conditions.
# What SMOTE is and The way it Works
SMOTE is an information augmentation method for addressing class imbalance issues in machine studying, particularly in supervised fashions like classifiers. In classification, when a minimum of one class is considerably under-represented in comparison with others, the mannequin can simply change into biased towards the bulk class, resulting in poor efficiency, particularly relating to predicting the uncommon class.
To deal with this problem, SMOTE creates artificial knowledge examples for the minority class, not by simply replicating present cases as they’re, however by interpolating between a pattern from the minority class and its nearest neighbors within the area of obtainable options: this course of is, in essence, like successfully “filling in” gaps in areas round which present minority cases transfer, thus serving to stability the dataset in consequence.
SMOTE iterates over every minority instance, identifies its ( ok ) nearest neighbors, after which generates a brand new artificial level alongside the “line” between the pattern and a randomly chosen neighbor. The results of making use of these easy steps iteratively is a brand new set of minority class examples, in order that the method to coach the mannequin is finished based mostly on a richer illustration of the minority class(es) within the dataset, and leading to a simpler, much less biased mannequin.
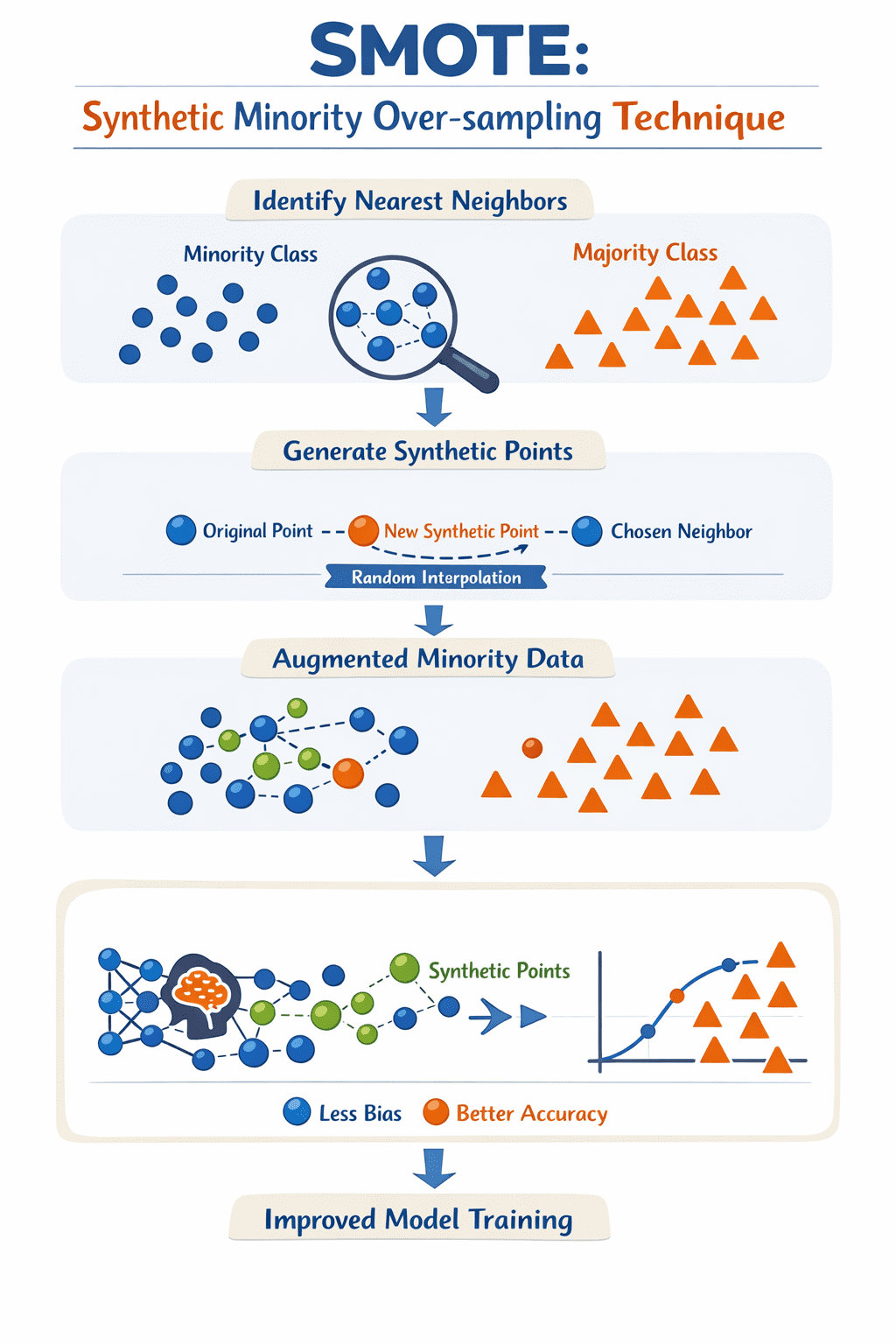
How SMOTE works | Picture by Writer
# Implementing SMOTE Appropriately in Python
To keep away from the info leakage points talked about beforehand, it’s best to make use of a pipeline. The imbalanced-learn library offers a pipeline object that ensures SMOTE is barely utilized to the coaching knowledge throughout every fold of a cross-validation or throughout a easy hold-out break up, leaving the take a look at set untouched and consultant of real-world knowledge.
The next instance demonstrates how you can combine SMOTE right into a machine studying workflow utilizing scikit-learn and imblearn:
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Cut up knowledge into coaching and testing units first
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Outline the pipeline: Resampling then modeling
# The imblearn Pipeline solely applies SMOTE to the coaching knowledge
pipeline = Pipeline([
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(random_state=42))
])
# Match the pipeline on coaching knowledge
pipeline.match(X_train, y_train)
# Consider on the untouched take a look at knowledge
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))
Through the use of the Pipeline, you make sure that the transformation occurs throughout the coaching context solely. This prevents artificial info from “bleeding” into your analysis set, offering a way more trustworthy evaluation of how your mannequin will deal with imbalanced courses in manufacturing.
# Frequent Misuses of SMOTE
Let us take a look at three widespread methods SMOTE is misused in machine studying workflows, and how you can keep away from these fallacious makes use of:
- Making use of SMOTE earlier than partitioning the dataset into coaching and take a look at units: It is a quite common error that inexperienced knowledge scientists might often (and typically by accident) incur. SMOTE generates new artificial examples based mostly on all of the accessible knowledge, and injecting artificial factors in what’s going to later be each the coaching and take a look at partitions is the “not-so-perfect” recipe to artificially inflate mannequin analysis metrics unrealistically. The fitting method is easy: break up the info first, then apply SMOTE solely on the coaching set. Considering of making use of k-fold cross-validation as effectively? Even higher.
- Over-balancing: Blindly resampling till there may be a precise match amongst class proportions is one other widespread error. In lots of circumstances, reaching that excellent stability just isn’t solely pointless however will also be counterproductive and unrealistic given the area or class construction. That is notably true in multiclass datasets with a number of sparse minority courses, the place SMOTE might find yourself creating artificial examples that cross the boundaries or lie in areas the place no actual knowledge examples are discovered: in different phrases, noise could also be inadvertently launched, with doable undesired penalties like mannequin overfitting. The overall method is to behave gently and take a look at coaching your mannequin with refined, incremental rises in minority class proportions.
- Ignoring the context round metrics and fashions: The general accuracy metric of a mannequin is a simple and interpretable metric to acquire, however it will also be a deceptive and “hole metric” that doesn’t replicate your mannequin’s incapacity to detect circumstances of the minority class. It is a vital concern in high-stakes domains like banking and healthcare, with eventualities just like the detection of uncommon illnesses. In the meantime, SMOTE will help enhance the reliance on metrics like recall, however it will probably lower its counterpart, precision, by introducing noisy artificial samples that will misalign with enterprise objectives. To correctly consider not solely your mannequin, but in addition SMOTE’s effectiveness in its efficiency, collectively deal with metrics like recall, F1-score, Matthews correlation coefficient (MCC, a “abstract” of a complete confusion matrix), or precision-recall space underneath the curve (PR-AUC). Likewise, take into account different methods like class weighting or threshold tuning as a part of the appliance of SMOTE to additional improve effectiveness.
# Concluding Remarks
This text revolved round SMOTE: a generally used method to deal with class imbalance in constructing some machine studying classifiers based mostly on real-world datasets. We recognized some widespread misuses of this system and sensible recommendation to strive avoiding them.
Iván Palomares Carrascosa is a pacesetter, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the actual world.