
Choosing a doc AI mannequin is difficult. Each vendor claims 95%+ accuracy. Common-purpose benchmarks take a look at reasoning and code, not whether or not a mannequin can extract a fancy desk from a scanned bill.
So we constructed the Clever Doc Processing (IDP) Leaderboard.
3 open benchmarks. 16+ fashions. 9,000+ actual paperwork. The duties that matter: OCR, desk extraction, key data extraction, visible QA, and lengthy doc understanding.
The purpose is not to provide you one quantity and declare a winner. It is to allow you to dig into the specifics. See the place every mannequin is powerful, the place it breaks, and determine for your self which one matches your paperwork.
The outcomes shocked us. The #7 mannequin scores greater than #1 on one benchmark. Sonnet beats Opus. Nanonets OCR2+ matches frontier fashions at lower than half of the associated fee.
Why 3 benchmarks?
Each benchmark measures one thing totally different. Use one and also you solely see one dimension. So we used three.
OlmOCR Bench: Are you able to reliably parse a messy web page? Dense LaTeX, degraded scans, tiny-font textual content, multi-column studying order. Fashions that excel at one usually fail at one other. This dataset contains various set of pdfs.
OmniDocBench: Does the mannequin perceive the doc’s construction? Formulation, tables, studying order. Structure comprehension, not simply character recognition.
IDP Core: Are you able to extract what a enterprise really wants? This one is ours. Invoices, handwritten textual content, ChartQA, DocVQA, 20+ web page paperwork, six sorts of tables. The stuff that breaks manufacturing pipelines. These are extra reasoning heavy duties than the opposite two benchmarks.
Every mannequin will get a functionality profile throughout six sub-tasks: textual content extraction, system dealing with, desk understanding, visible QA, structure ordering, and key data extraction.
Discover every mannequin’s functionality profile at: idp leaderboard
What the leaderboard really helps you to do?
Most leaderboards provide you with a desk. You have a look at it. You choose the highest mannequin. You progress on. It looks like being a by-stander and never hands-on.

We wished one thing extra clear and hands-on than that.
For that we created the Outcomes Explorer that allows you to see precise predictions and examine fashions on actual paperwork. For any doc within the benchmark, you see the bottom reality subsequent to each mannequin’s uncooked output. This makes you see and examine the use-cases that is related to you.
That is highly effective because it additionally makes you query the bottom reality and offers you the complete image of what is going on behind the scenes of every benchmark process.
You’ll be able to see precisely the place it hallucinated a desk cell or missed a handwritten phrase. Here is an instance exhibiting how fashions deal with advanced system extraction.

1v1 Evaluate places two fashions facet by facet throughout all six functionality dimensions.
How did we run it?
We wished anybody to have the ability to run all three benchmarks. So we made setup as near zero as we may.
Every little thing pulls from HuggingFace. We pre-rendered all PDFs to PNGs and hosted them at shhdwi/olmocr-pre-rendered so you do not want a conversion pipeline. IDP Core embeds photographs immediately within the dataset. Nothing to clone your self or unzip.
The runner works with any mannequin that has an API. Failed runs choose up the place they left off.
Here is the Github repo hyperlink to attempt it your self: IDP Benchmarking repo
Here is what stood out.
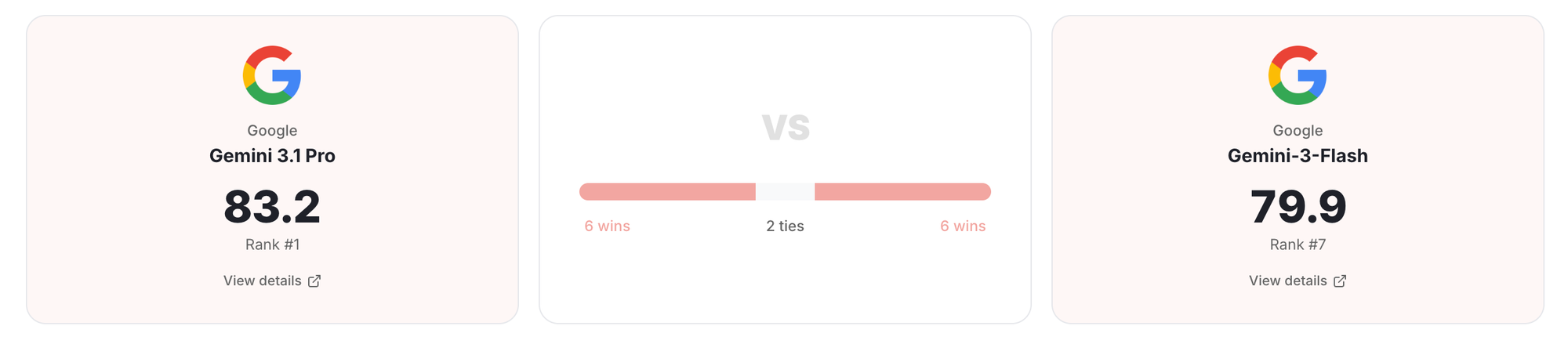
Gemini 3.1 Professional dominates VQA duties
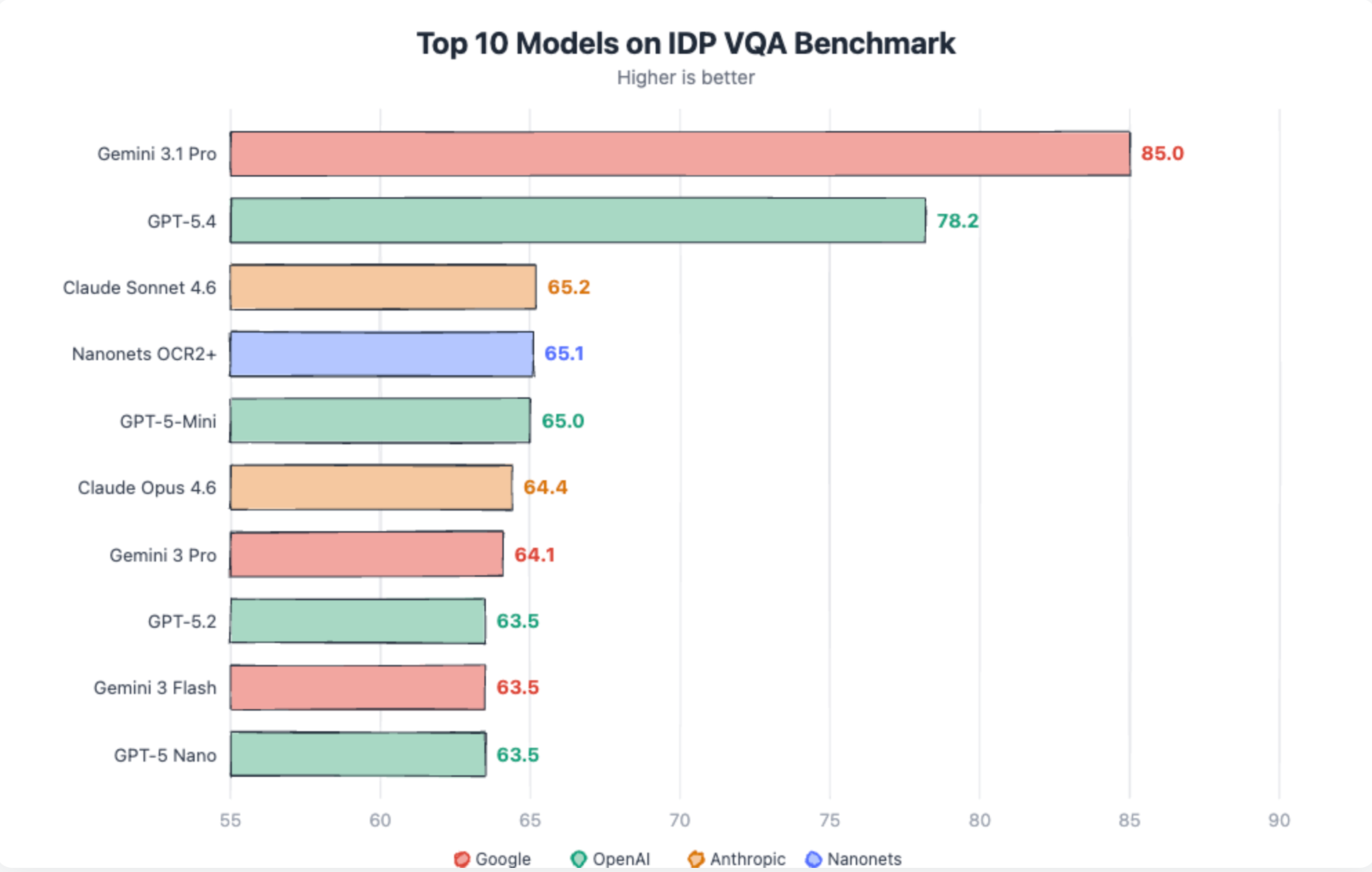
Gemini 3.1 scores 85 in VQA, properly above every other mannequin. Closest to it’s GPT-5.4 at 78.2. Relaxation all fashions are in 60’s.
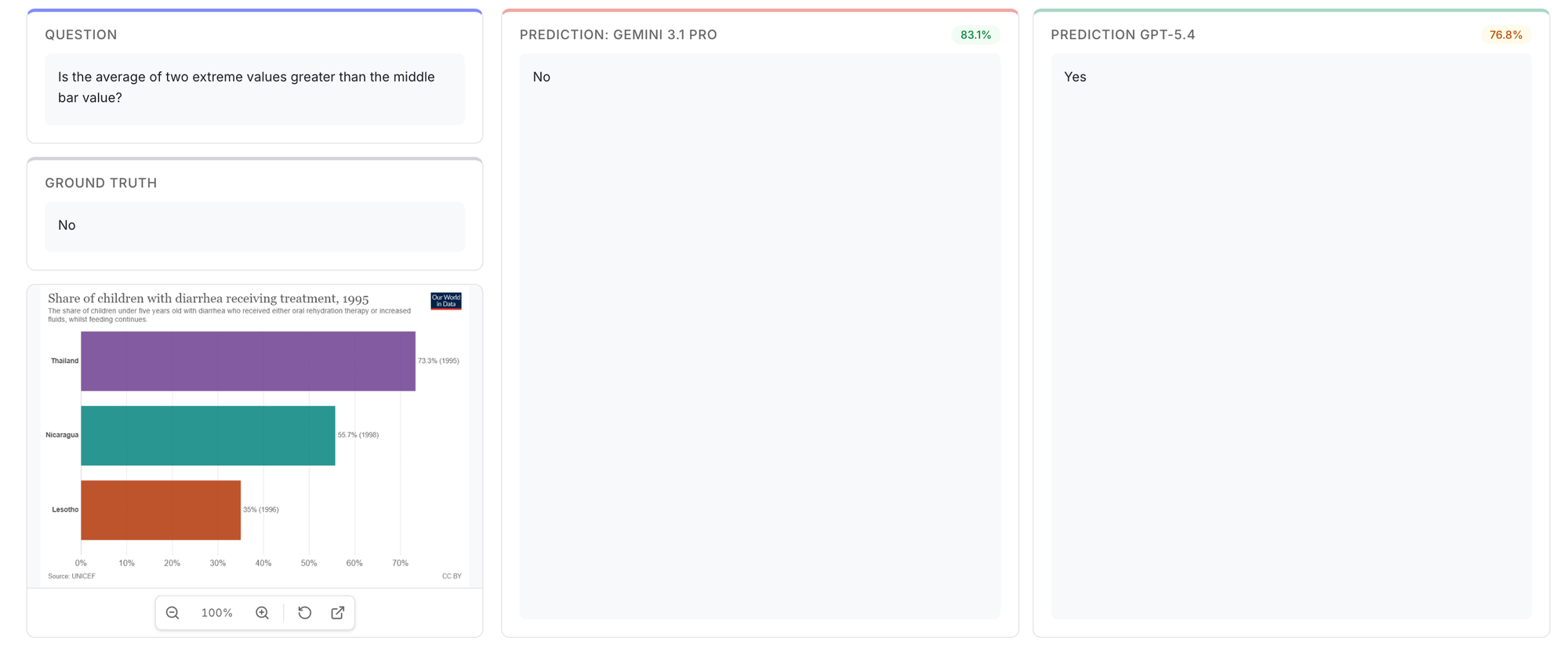
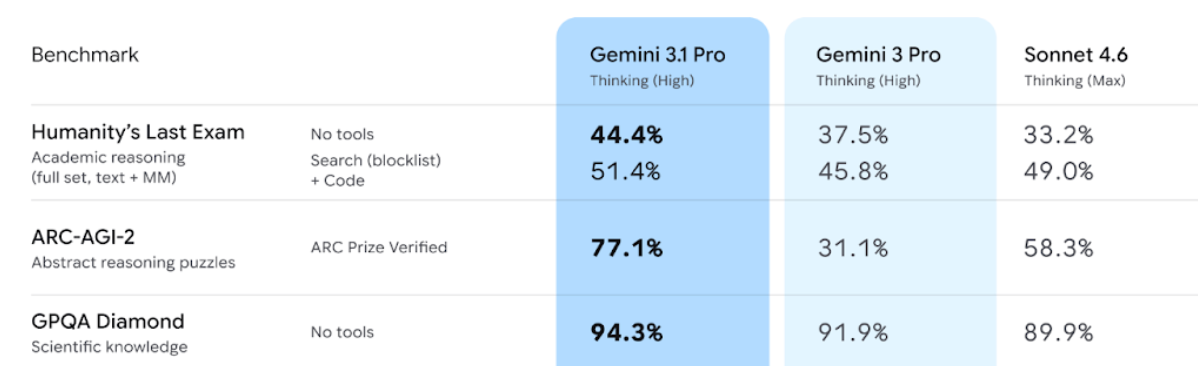
That is additionally seen within the newest benchmarks launched by Google. Gemini 3.1 professional is healthier at reasoning duties. Identical holds true for Doc VQA duties as properly.
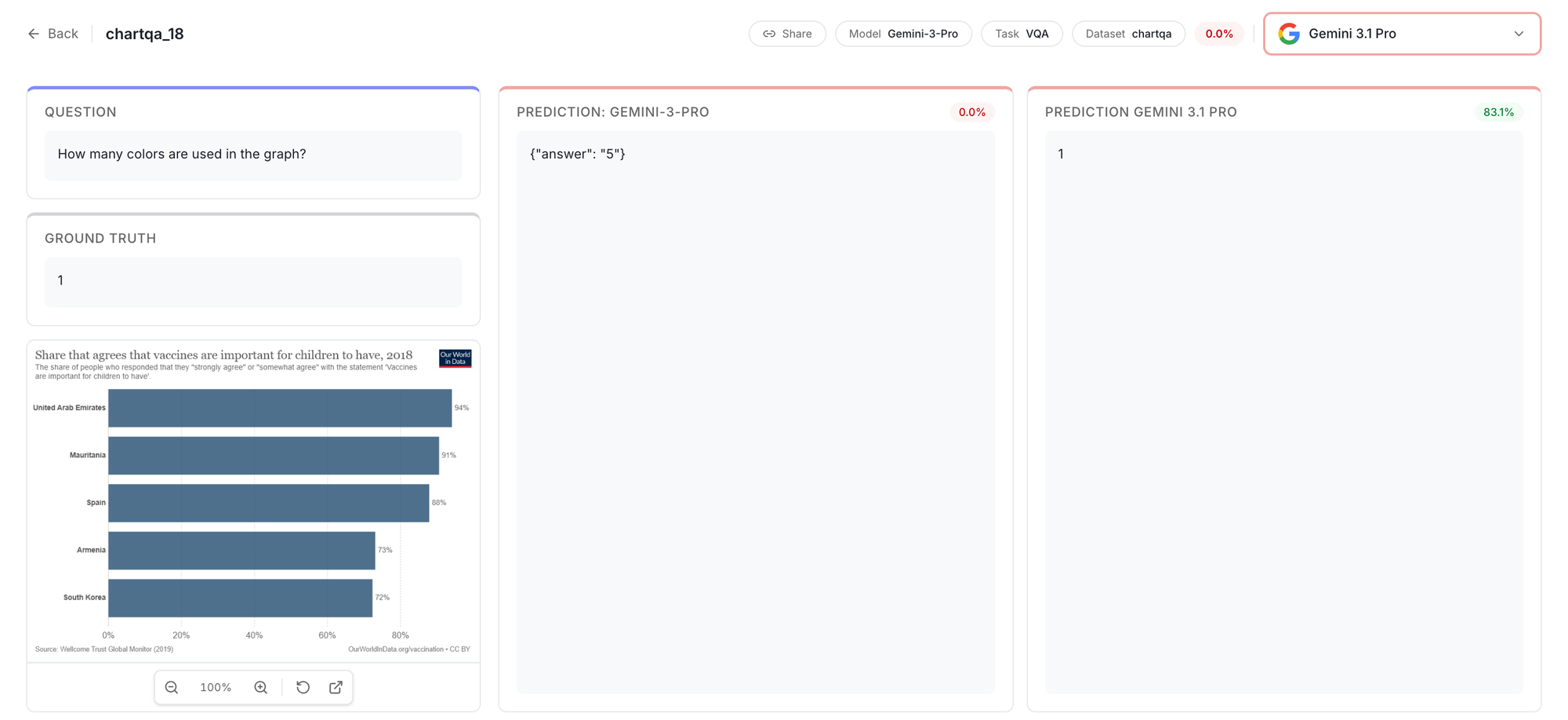
Cheaper fashions are surprisingly good
This saved developing.
- Sonnet 4.6 (80.8) is nearly as good as Claude 4.6 (80.3)
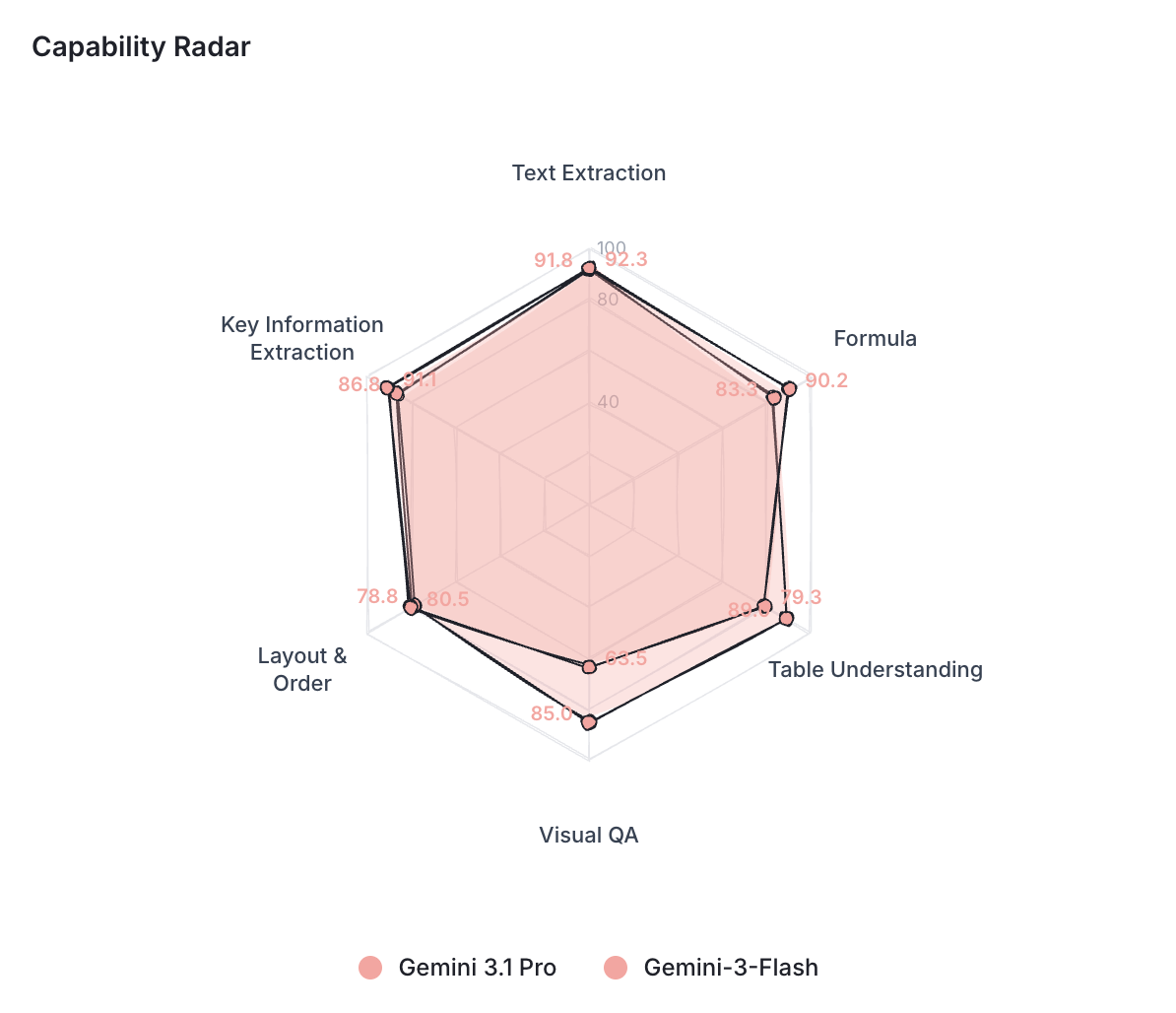
- Gemini-3 flash matches Gemini-3 professional and generally even higher (in Omnidoc bench)
This might level to one thing fascinating. Cheaper fashions match costly ones on extraction. Textual content, tables, structure, formulation. They appear to be studying paperwork the identical manner beneath the hood. The hole solely seems whenever you ask them to motive about what they learn. That is the place larger fashions pull forward, and that is the place Gemini 3.1 Professional’s lead really comes from.
Identical is confirmed beneath by the aptitude radar between Gemini 3.1-pro and Gemini 3-flash:
Price adjustments the maths
Here is the half that issues should you’re processing paperwork at any actual quantity.
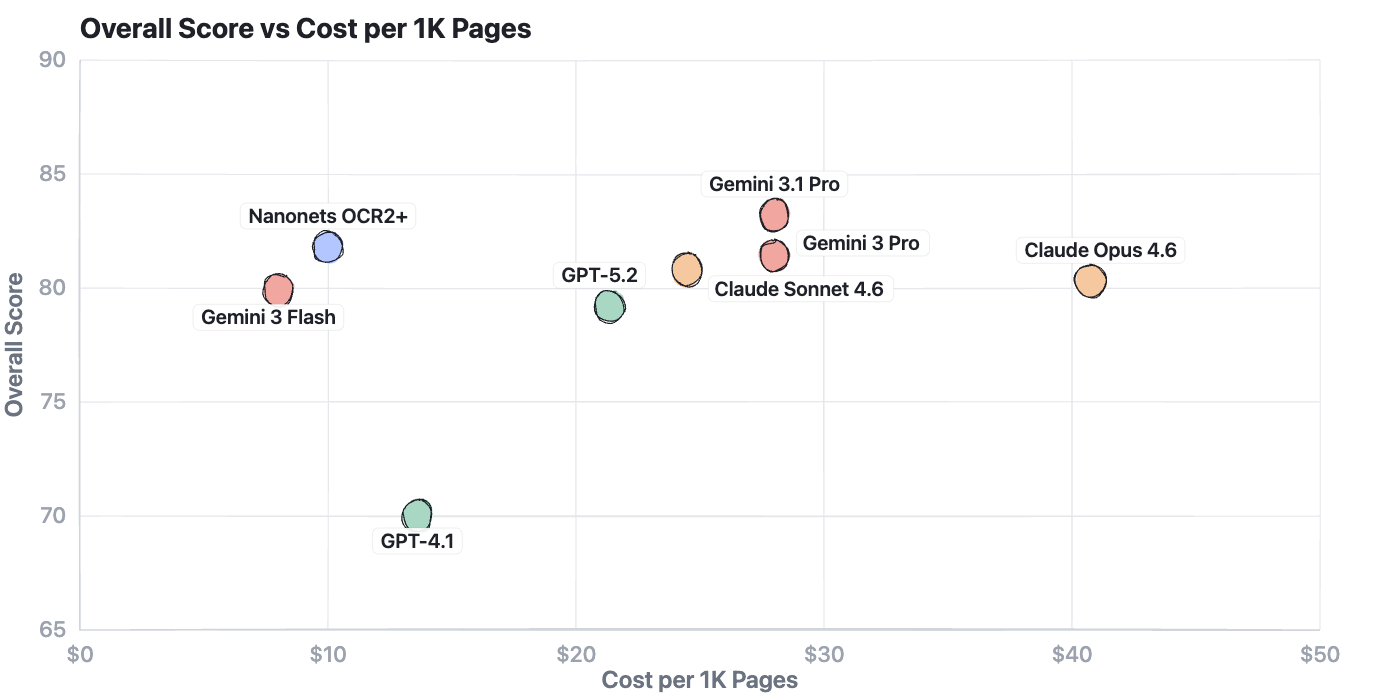
The Nanonets OCR2+ mannequin is a superb stability for each accuracy and price relating to scale. Click on right here for the mannequin’s full profile
The place issues nonetheless break!
Sparse, unstructured tables stay the toughest extraction process.
Most fashions land beneath 55%. These are tables the place cells are scattered, many are empty, and there aren’t any gridlines to information the mannequin. Solely Gemini 3.1 Professional and GPT-5.4 constantly deal with them at 94% and 87% respectively, nonetheless properly beneath their 96%+ on dense structured tables
Click on Right here to test the Gemini 3.1-pro outputs on lengthy sparse docs

Handwriting OCR hasn’t crossed 76%. The very best mannequin is Gemini 3.1 Professional at 75.5%. Digital printed OCR is 98%+ for frontier fashions. Handwriting is a essentially totally different drawback and no mannequin has cracked it.
Chart query answering is unreliable. Nanonets OCR2+ leads at 87%, Claude Sonnet follows at 85%, GPT-5.4 drops to 77%.
The failures are particular: axis values misinterpret by orders of magnitude, the unsuitable bar chosen, off-by-one errors on intently spaced information factors.

Handwritten type extraction hallucinates on clean fields. Each mannequin clusters between 80-84% on this process. The failure mode is constant: fashions fill in values for fields which are clean on the shape. A reputation, a date, a standing that does not exist within the doc.
Gemini > Claude = OpenAI
The pecking order was settled. Gemini led, Claude adopted, OpenAI trailed. GPT-4.1 scored 70.0. No one was selecting OpenAI for doc work.
For GPT-5.4 Desk extraction went from 73.1 to 94.8. DocVQA went from 42.1% to 91.1%. GPT-5.4 obtained higher at understanding paperwork and reasoning.
The general scores at the moment are 83.2, 81.0, 80.8. Shut sufficient that the rating issues lower than the form. Claude leads on formulation. GPT-5.4 leads on tables and QA. Gemini leads on OCR and VQA.

One factor price noting: Claude fashions had stricter content material moderation that affected sure paperwork. Previous newspaper scans, textbook pages, and historic paperwork generally triggered filters. This harm Claude’s scores (solely in OmniDoc and OlmOCR).
Now, Which Mannequin Must you choose?
Each vendor will inform you their mannequin is 95%+ correct. On structured tables and printed textual content, they may be proper. On sparse tables, handwritten types, and 20-page contracts, most fashions battle.
Working a high-volume OCR pipeline? Nanonets OCR2+ provides you top-tier accuracy at $10 per thousand pages.
Processing advanced tables or want excessive accuracy on reasoning over paperwork? Gemini 3.1 Professional is well worth the premium at $28/1K pages.
Constructing a easy extraction workflow on a price range? Sonnet and Flash match their costly siblings on extraction duties. Nanonets OCR2+ matches right here too, sturdy accuracy with out the frontier price ticket.
However do not take our phrase for it. The leaderboard has the scores. The Outcomes Explorer has the precise predictions. Choose a process that matches your workload. Take a look at what they output on actual paperwork. Then determine.
What’s subsequent
We will likely be including extra open-source fashions and doc processing pipeline libraries to the leaderboard quickly. If you’d like a particular mannequin evaluated, request it on GitHub.
We’ll hold refreshing datasets too. Benchmarks that by no means change change into targets for overfitting.
The leaderboard is at idp-leaderboard.org. The Outcomes are open. The code is open. Go have a look at what these fashions really do together with your sorts of paperwork. The numbers inform one story. The Outcomes Explorer tells a extra trustworthy one.