
Picture by Creator
# Introduction
If you resolve sufficient interview-style knowledge issues, you begin noticing a humorous impact: the dataset “form” quietly dictates your coding model. A time-series desk nudges you towards window capabilities. A star schema pushes you into JOIN chains and GROUP BY. A pandas job with two DataFrames nearly begs for .merge() and isin().
This text makes that instinct measurable. Utilizing a set of consultant SQL and pandas issues, we are going to establish fundamental code-structure traits (frequent desk expression (CTE) utilization, the frequency of window capabilities, frequent pandas methods) and illustrate which components prevail and the explanations behind this.
# Why Information Construction Modifications Your Coding Type
Somewhat than simply logic, knowledge issues are extra like constraints wrapped in tables:
// Rows That Rely On Different Rows (Time, Rank, “Earlier Worth”)
If every row’s reply is dependent upon adjoining rows (e.g. yesterday’s temperature, earlier transaction, operating totals), options naturally lean on window capabilities like LAG(), LEAD(), ROW_NUMBER(), and DENSE_RANK().
Think about, for instance, this interview query’s tables:

Every buyer’s outcome on a given day can’t be decided in an remoted method. After aggregating order prices on the customer-day stage, every row have to be evaluated relative to different clients on the identical date to find out which complete is highest.
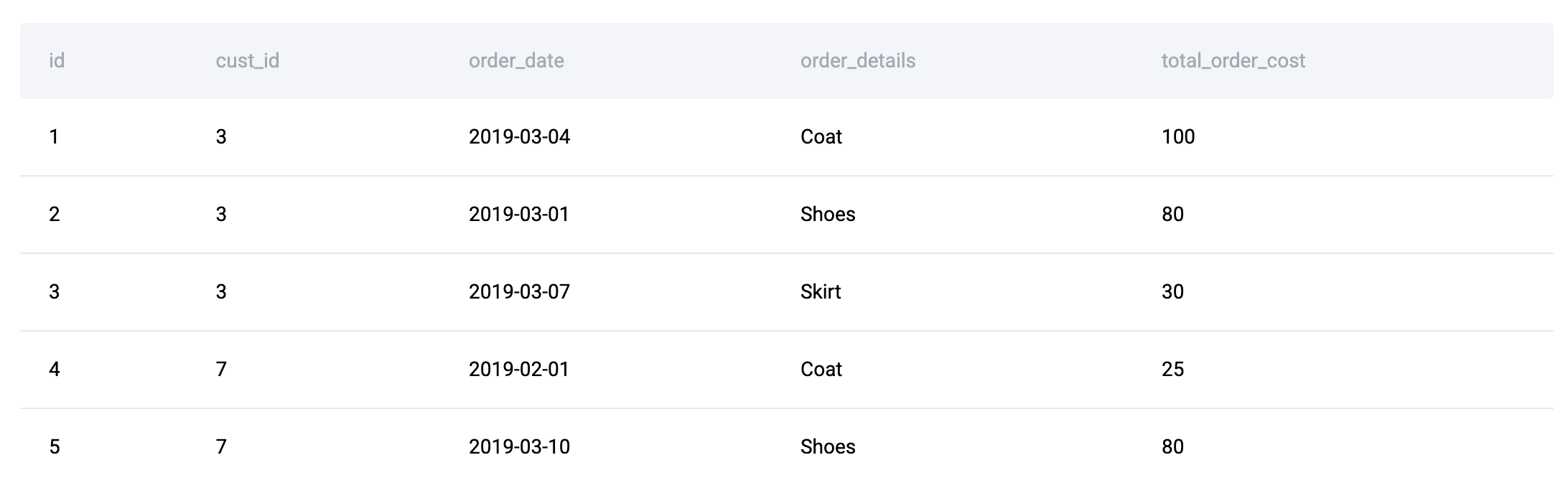
As a result of the reply for one row is dependent upon the way it ranks relative to its friends inside a time partition, this dataset form naturally results in window capabilities similar to RANK() or DENSE_RANK() reasonably than easy aggregation alone.
// A number of Tables With Roles (Dimensions vs Details)
When one desk describes entities, and one other describes occasions, options have a tendency towards JOIN + GROUP BY patterns (SQL) or .merge() + .groupby() patterns (pandas).
For example, on this interview query, the information tables are the next:

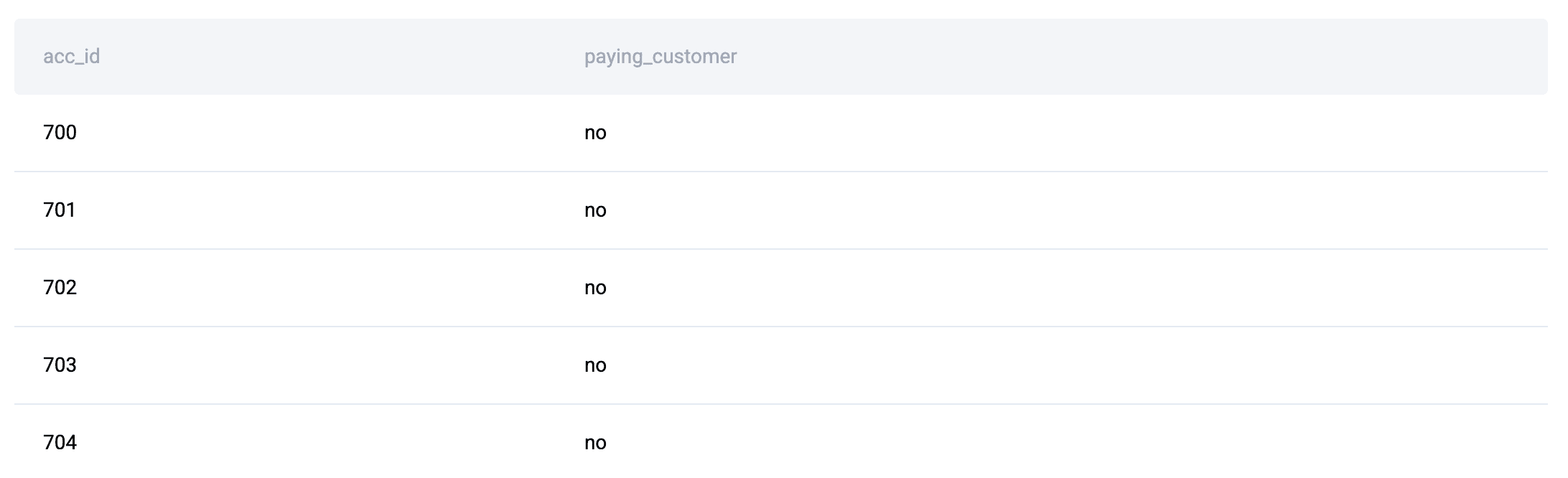
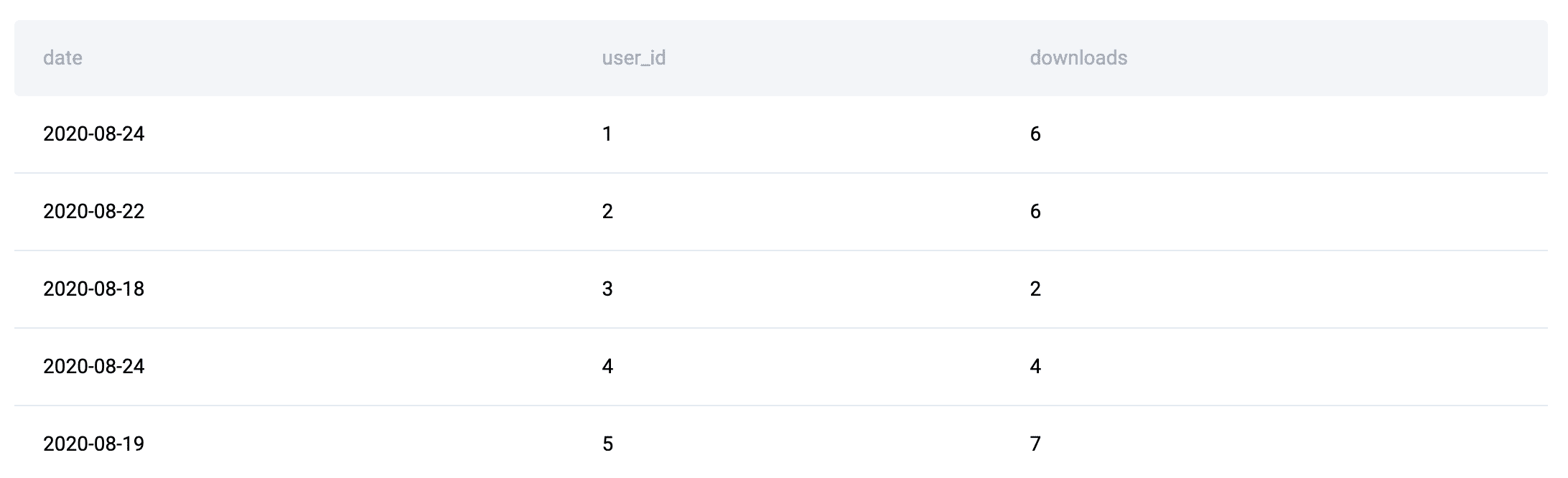
On this instance, since entity attributes (customers and account standing) and occasion knowledge (downloads) are separated, the logic should first recombine them utilizing JOINs earlier than significant aggregation (precisely the dimension) can happen. This truth sample is what creates JOIN + GROUP BY options.
// Small Outputs With Exclusion Logic (Anti-Be a part of Patterns)
Issues asking “who by no means did X” usually turn out to be LEFT JOIN … IS NULL / NOT EXISTS (SQL) or ~df['col'].isin(...) (pandas).
# What We Measure: Code Construction Traits
To check “coding model” throughout completely different options, it’s helpful to establish a restricted set of observable options that may be extracted from SQL textual content and Python code.
Whereas these is probably not flawless indicators of answer high quality (e.g. correctness or effectivity), they will function reliable indicators relating to how analysts interact with a dataset.
// SQL Options We Measure
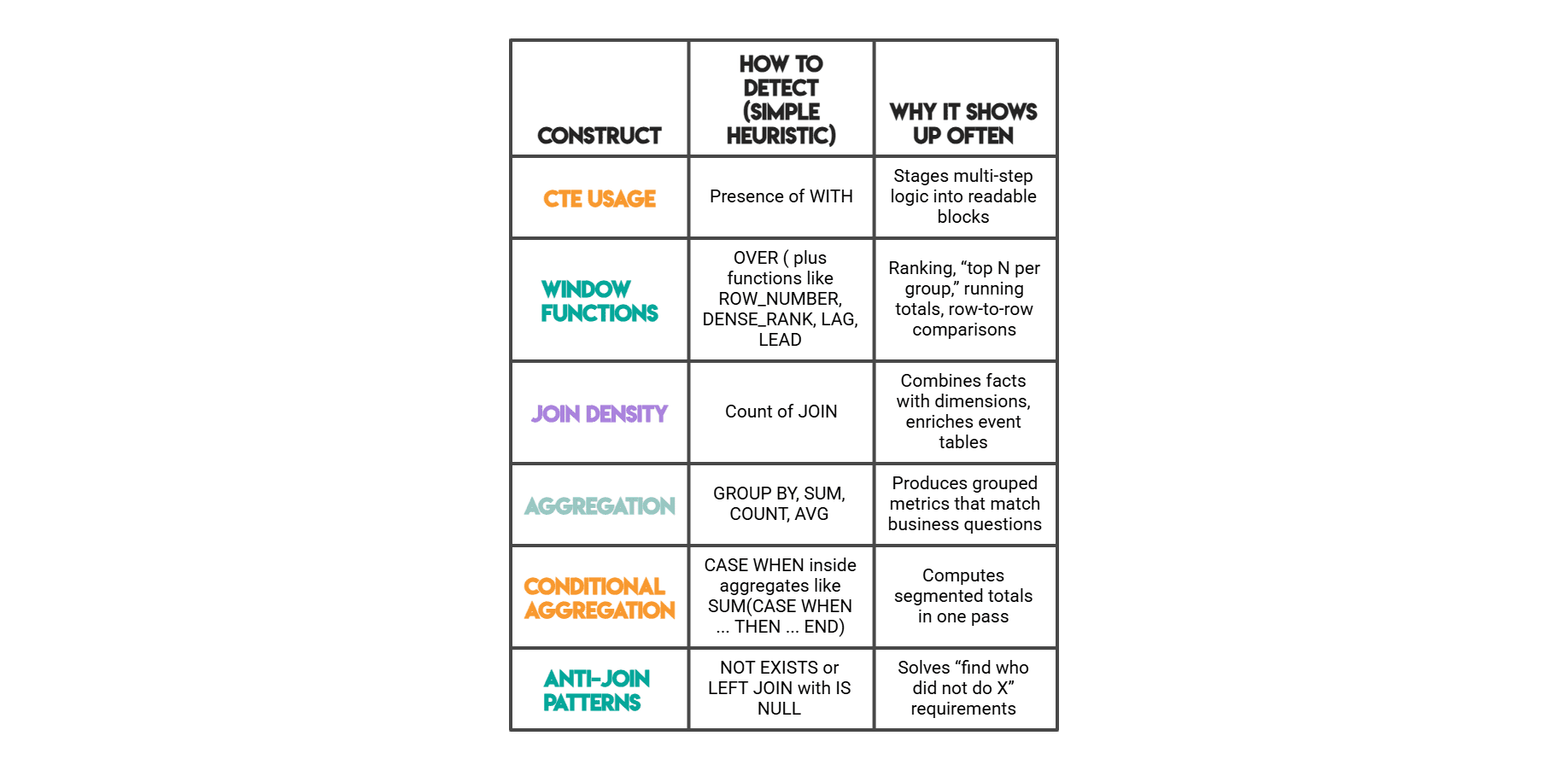
// Pandas Options We Measure
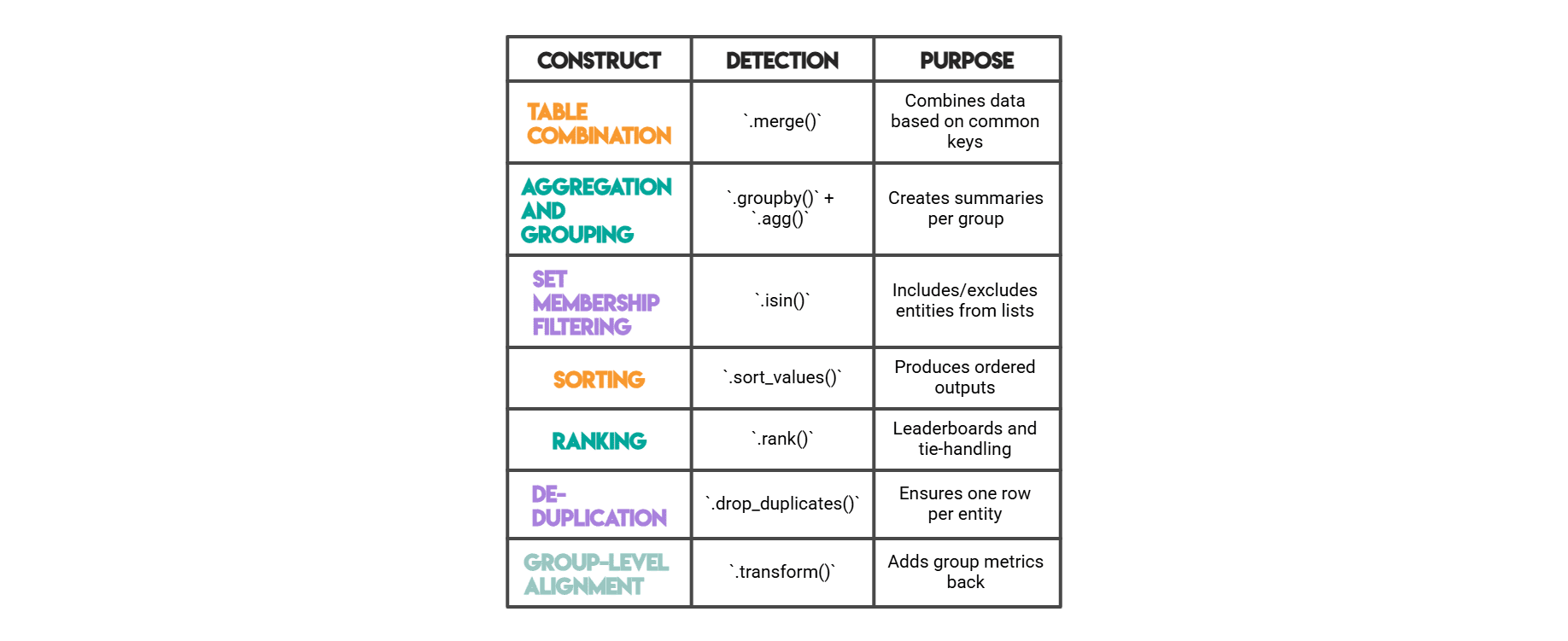
# Which Constructs Are Most Frequent
To maneuver past anecdotal observations and quantify these patterns, you want a extra easy and constant methodology to derive structural indicators instantly from answer code.
As a concrete anchor for this workflow, we used all academic questions on the StrataScratch platform.
Within the outcome proven under, “complete occurrences” is the uncooked depend of occasions a sample seems throughout all code. A single query’s answer might use JOIN 3 occasions, so these 3 all add up. “Questions utilizing” issues what number of distinct questions have a minimum of one incidence of that function (i.e. a binary “used / not used” per query).
This methodology reduces every answer to a restricted set of observable options, enabling us to persistently and reproducibly evaluate coding types throughout issues and to affiliate dataset construction with dominant constructs instantly.
// SQL Options
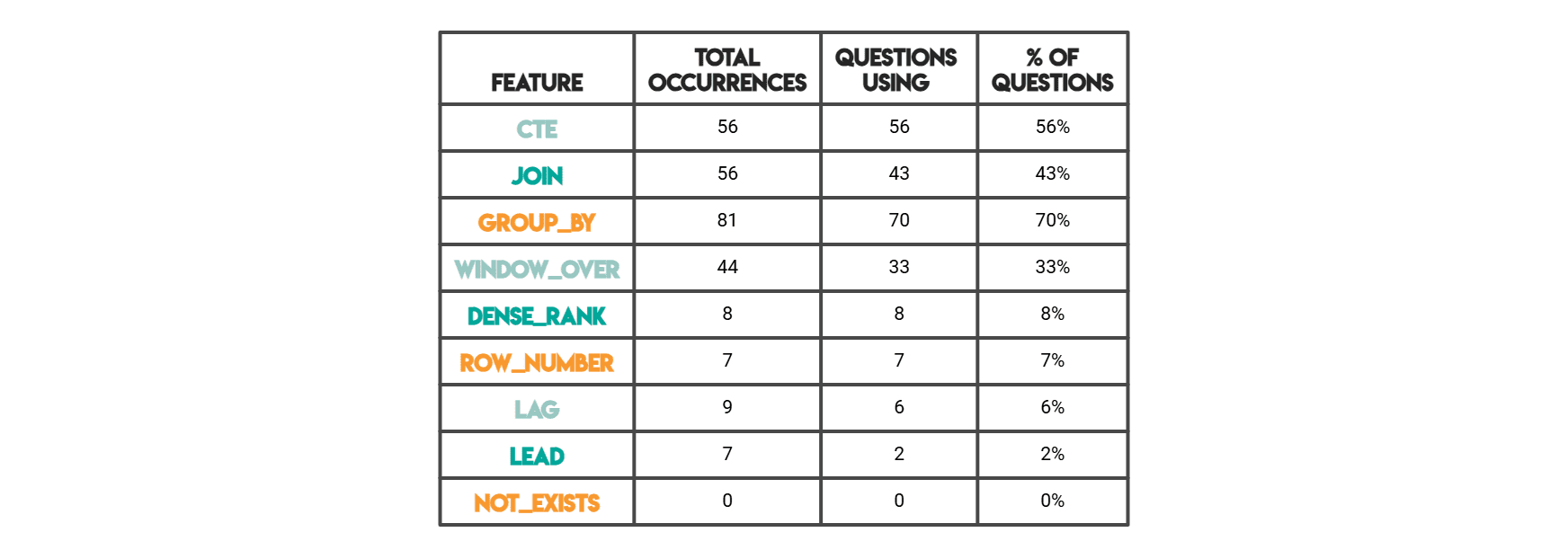
// Pandas Options (Python Options)
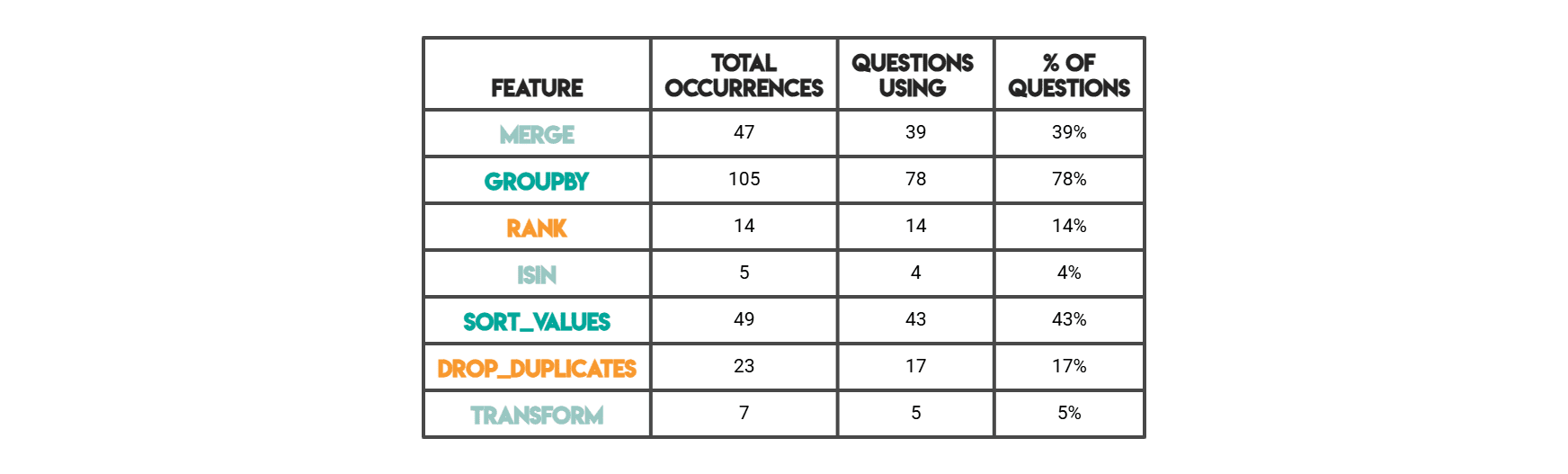
// Function Extraction Code
Under, we current the code snippets used, which you should utilize by yourself options (or rephrase solutions in your individual phrases) and extract options from the code textual content.
// SQL Function Extraction (Instance)
import re
from collections import Counter
sql = # insert code right here
SQL_FEATURES = {
"cte": r"bWITHb",
"be part of": r"bJOINb",
"group_by": r"bGROUPs+BYb",
"window_over": r"bOVERs*(",
"dense_rank": r"bDENSE_RANKb",
"row_number": r"bROW_NUMBERb",
"lag": r"bLAGb",
"lead": r"bLEADb",
"not_exists": r"bNOTs+EXISTSb",
}
def extract_sql_features(sql: str) -> Counter:
sql_u = sql.higher()
return Counter({okay: len(re.findall(p, sql_u)) for okay, p in SQL_FEATURES.gadgets()})
// Pandas Function Extraction (Instance)
import re
from collections import Counter
pandas = # paste code right here
PD_FEATURES = {
"merge": r".merges*(",
"groupby": r".groupbys*(",
"rank": r".ranks*(",
"isin": r".isins*(",
"sort_values": r".sort_valuess*(",
"drop_duplicates": r".drop_duplicatess*(",
"remodel": r".transforms*(",
}
def extract_pd_features(code: str) -> Counter:
return Counter({okay: len(re.findall(p, code)) for okay, p in PD_FEATURES.gadgets()})Let’s now discuss in additional element about patterns we observed.
# SQL Frequency Highlights
// Window Capabilities Surge In “highest Per Day” And Tie-friendly Rating Duties
For instance, on this interview query, we’re requested to compute a each day complete per buyer, then choose the very best outcome for every date, together with ties. It is a requirement that naturally results in window capabilities similar to RANK() or DENSE_RANK(), segmented by day.
The answer is as follows:
WITH customer_daily_totals AS (
SELECT
o.cust_id,
o.order_date,
SUM(o.total_order_cost) AS total_daily_cost
FROM orders o
WHERE o.order_date BETWEEN '2019-02-01' AND '2019-05-01'
GROUP BY o.cust_id, o.order_date
),
ranked_daily_totals AS (
SELECT
cust_id,
order_date,
total_daily_cost,
RANK() OVER (
PARTITION BY order_date
ORDER BY total_daily_cost DESC
) AS rnk
FROM customer_daily_totals
)
SELECT
c.first_name,
rdt.order_date,
rdt.total_daily_cost AS max_cost
FROM ranked_daily_totals rdt
JOIN clients c ON rdt.cust_id = c.id
WHERE rdt.rnk = 1
ORDER BY rdt.order_date;
This two-step method — combination first, then rank inside every date — reveals why window capabilities are perfect for “highest per group” situations the place ties must be maintained, and why fundamental GROUP BY logic is insufficient.
// CTE Utilization Will increase When The Query Has Staged Computation
A typical desk expression (CTE) (or a number of CTEs) retains every step readable and makes it simpler to validate intermediate outcomes.
This construction additionally displays how analysts suppose: separating knowledge preparation from enterprise logic, permitting the question to be easier to know, troubleshoot, and adapt as wants change.
// JOIN Plus Aggregation Turns into The Default In Multi-table Enterprise Metrics
When measures stay in a single desk and dimensions in one other, you usually can’t keep away from JOIN clauses. As soon as joined, GROUP BY and conditional totals (SUM(CASE WHEN ... THEN ... END)) are normally the shortest path.
# Pandas Technique Highlights
// .merge() Seems Every time The Reply Relies upon On Extra Than One Desk
This interview query is an effective instance of the pandas sample. When rides and fee or low cost logic span columns and tables, you usually first mix the information, then depend or evaluate.
import pandas as pd
orders_payments = lyft_orders.merge(lyft_payments, on='order_id')
orders_payments = orders_payments[(orders_payments['order_date'].dt.to_period('M') == '2021-08') & (orders_payments['promo_code'] == False)]
grouped_df = orders_payments.groupby('metropolis').measurement().rename('n_orders').reset_index()
outcome = grouped_df[grouped_df['n_orders'] == grouped_df['n_orders'].max()]['city']
As soon as the tables are merged, the rest of the answer reduces to a well-known .groupby() and comparability step, underscoring how preliminary desk merging can simplify downstream logic in pandas.
# Why These Patterns Maintain Showing
// Time-based Tables Usually Name For Window Logic
When an issue refers to totals “per day,” comparisons between days, or deciding on the very best worth for every date, ordered logic is often required. For that reason, rating capabilities with OVER are frequent, particularly when ties have to be preserved.
// Multi-step Enterprise Guidelines Profit From Staging
Some issues combine filtering guidelines, joins, and computed metrics. It’s attainable to jot down every little thing in a single question, however this will increase the problem of studying and debugging. CTEs assist with this by separating enrichment from aggregation in a method that’s simpler to validate, aligning with the Premium vs Freemium mannequin.
// Multi-table Questions Naturally Improve Be a part of Density
If a metric is dependent upon attributes saved in a special desk, becoming a member of is required. As soon as tables are mixed, grouped summaries are the pure subsequent step. That general form reveals up repeatedly in StrataScratch questions that blend occasion knowledge with entity profiles.
# Sensible Takeaways For Sooner, Cleaner Options
- If the output is dependent upon ordered rows, count on window capabilities like
ROW_NUMBER()orDENSE_RANK() - If the query reads like “compute A, then compute B from A,” a WITH block normally improves readability.
- If the dataset is cut up throughout a number of entities, plan for JOIN early and determine your grouping keys earlier than writing the ultimate choose.
- In pandas, deal with
.merge()because the default when the logic spans a number of DataFrames, then construct the metric with.groupby()and clear filtering.
# Conclusion
Coding model follows construction: time-based and “highest per group” questions have a tendency to supply window capabilities. Multi-step enterprise guidelines have a tendency to supply CTEs.
Multi-table metrics improve JOIN density, and pandas mirrors these identical strikes by .merge() and .groupby().
Extra importantly, recognizing these structural patterns early on can considerably alter your method to a brand new drawback. As a substitute of ranging from syntax or memorized tips, you may motive from the dataset itself: Is that this a per-group most? A staged enterprise rule? A multi-table metric?
This variation in mindset permits you to anticipate the principle framework previous to writing any code. Ultimately, this leads to faster answer drafting, easier validation, and extra consistency throughout SQL and pandas, since you are responding to the information construction, not simply the query textual content.
When you be taught to acknowledge the dataset form, you may predict the dominant assemble early. That makes options sooner to jot down, simpler to debug, and extra constant throughout new issues.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from prime firms. Nate writes on the most recent traits within the profession market, offers interview recommendation, shares knowledge science initiatives, and covers every little thing SQL.