
Picture by Editor
# Introduction
Information science tasks normally start as exploratory Python notebooks however have to be moved to manufacturing settings at some stage, which is likely to be difficult if not deliberate rigorously.
QuantumBlack’s framework, Kedro, is an open-source software that bridges the hole between experimental notebooks and production-ready options by translating ideas surrounding challenge construction, scalability, and reproducibility into follow.
This text introduces and explores Kedro’s fundamental options, guiding you thru its core ideas for a greater understanding earlier than diving deeper into this framework for addressing actual knowledge science tasks.
# Getting Began With Kedro
Step one to make use of Kedro is, after all, to put in it in our operating atmosphere, ideally an IDE — Kedro can’t be absolutely leveraged in pocket book environments. Open your favourite Python IDE, for example, VS Code, and kind within the built-in terminal:
Subsequent, we create a brand new Kedro challenge utilizing this command:
If the command works nicely, you will be requested just a few questions, together with a reputation to your challenge. We are going to title it Churn Predictor. If the command would not work, it is likely to be due to a battle associated to having a number of Python variations put in. In that case, the cleanest resolution is to work in a digital atmosphere inside your IDE. These are some fast workaround instructions to create one (ignore them if the earlier command to create a Kedro challenge already labored!):
python3.11 -m venv venv
supply venv/bin/activate
pip set up kedro
kedro --version
Then choose in your IDE the next Python interpreter to work on from now onwards: ./venv/bin/python.
At this level, if every little thing labored nicely, it is best to have on the left-hand aspect (within the ‘EXPLORER’ panel in VS Code) a full challenge construction inside churn-predictor. Within the terminal, let’s navigate to our challenge’s fundamental folder:
Time to get a glimpse of Kedro’s core options by means of our newly created challenge.
# Exploring the Core Parts of Kedro
The primary ingredient we are going to introduce — and create by ourselves — is the knowledge catalog. In Kedro, this ingredient is answerable for isolating knowledge definitions from the principle code.
There’s already an empty file created as a part of the challenge construction that may act as the information catalog. We simply want to search out it and populate it with content material. Within the IDE explorer, contained in the churn-predictor challenge, go to conf/base/catalog.yml and open this file, then add the next:
raw_customers:
sort: pandas.CSVDataset
filepath: knowledge/01_raw/clients.csv
processed_features:
sort: pandas.ParquetDataset
filepath: knowledge/02_intermediate/options.parquet
train_data:
sort: pandas.ParquetDataset
filepath: knowledge/02_intermediate/practice.parquet
test_data:
sort: pandas.ParquetDataset
filepath: knowledge/02_intermediate/check.parquet
trained_model:
sort: pickle.PickleDataset
filepath: knowledge/06_models/churn_model.pkl
In a nutshell, now we have simply outlined (not created but) 5 datasets, each with an accessible key or title: raw_customers, processed_features, and so forth. The principle knowledge pipeline we are going to create later ought to be capable to reference these datasets by their title, therefore abstracting and utterly isolating enter/output operations from the code.
We are going to now want some knowledge that acts as the primary dataset within the above knowledge catalog definitions. For this instance, you possibly can take this pattern of synthetically generated buyer knowledge, obtain it, and combine it into your Kedro challenge.
Subsequent, we navigate to knowledge/01_raw, create a brand new file known as clients.csv, and add the content material of the instance dataset we are going to use. The simplest means is to see the “Uncooked” content material of the dataset file in GitHub, choose all, copy, and paste into your newly created file within the Kedro challenge.
Now we are going to create a Kedro pipeline, which is able to describe the information science workflow that will likely be utilized to our uncooked dataset. Within the terminal, sort:
kedro pipeline create data_processing
This command creates a number of Python recordsdata inside src/churn_predictor/pipelines/data_processing/. Now, we are going to open nodes.py and paste the next code:
import pandas as pd
from typing import Tuple
def engineer_features(raw_df: pd.DataFrame) -> pd.DataFrame:
"""Create derived options for modeling."""
df = raw_df.copy()
df['tenure_months'] = df['account_age_days'] / 30
df['avg_monthly_spend'] = df['total_spend'] / df['tenure_months']
df['calls_per_month'] = df['support_calls'] / df['tenure_months']
return df
def split_data(df: pd.DataFrame, test_fraction: float) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Break up knowledge into practice and check units."""
practice = df.pattern(frac=1-test_fraction, random_state=42)
check = df.drop(practice.index)
return practice, check
The 2 capabilities we simply outlined act as nodes that may apply transformations on a dataset as a part of a reproducible, modular workflow. The primary one applies some easy, illustrative function engineering by creating a number of derived options from the uncooked ones. In the meantime, the second perform defines the partitioning of the dataset into coaching and check units, e.g. for additional downstream machine studying modeling.
There’s one other Python file in the identical subdirectory: pipeline.py. Let’s open it and add the next:
from kedro.pipeline import Pipeline, node
from .nodes import engineer_features, split_data
def create_pipeline(**kwargs) -> Pipeline:
return Pipeline([
node(
func=engineer_features,
inputs="raw_customers",
outputs="processed_features",
name="feature_engineering"
),
node(
func=split_data,
inputs=["processed_features", "params:test_fraction"],
outputs=["train_data", "test_data"],
title="split_dataset"
)
])
A part of the magic takes place right here: discover the names used for inputs and outputs of nodes within the pipeline. Identical to Lego items, right here we will flexibly reference totally different dataset definitions in our knowledge catalog, beginning, after all, with the dataset containing uncooked buyer knowledge we created earlier.
One final couple of configuration steps stay to make every little thing work. The proportion of check knowledge for the partitioning node has been outlined as a parameter that must be handed. In Kedro, we outline these “exterior” parameters to the code by including them to the conf/base/parameters.yml file. Let’s add the next to this presently empty configuration file:
As well as, by default, the Kedro challenge implicitly imports modules from the PySpark library, which we won’t actually need. In settings.py (contained in the “src” subdirectory), we will disable this by commenting out and modifying the primary few current strains of code as follows:
# Instantiated challenge hooks.
# from churn_predictor.hooks import SparkHooks # noqa: E402
# Hooks are executed in a Final-In-First-Out (LIFO) order.
HOOKS = ()
Save all adjustments, guarantee you’ve gotten pandas put in in your operating atmosphere, and prepare to run the challenge from the IDE terminal:
This may increasingly or might not work at first, relying on the model of Kedro put in. If it would not work and also you get a DatasetError, the doubtless resolution is to pip set up kedro-datasets or pip set up pyarrow (or perhaps each!), then attempt to run once more.
Hopefully, you might get a bunch of ‘INFO’ messages informing you concerning the totally different levels of the information workflow happening. That is a very good signal. Within the knowledge/02_intermediate listing, you might discover a number of parquet recordsdata containing the outcomes of the information processing.
To wrap up, you possibly can optionally pip set up kedro-viz and run kedro viz to open up in your browser an interactive graph of your flashy workflow, as proven beneath:
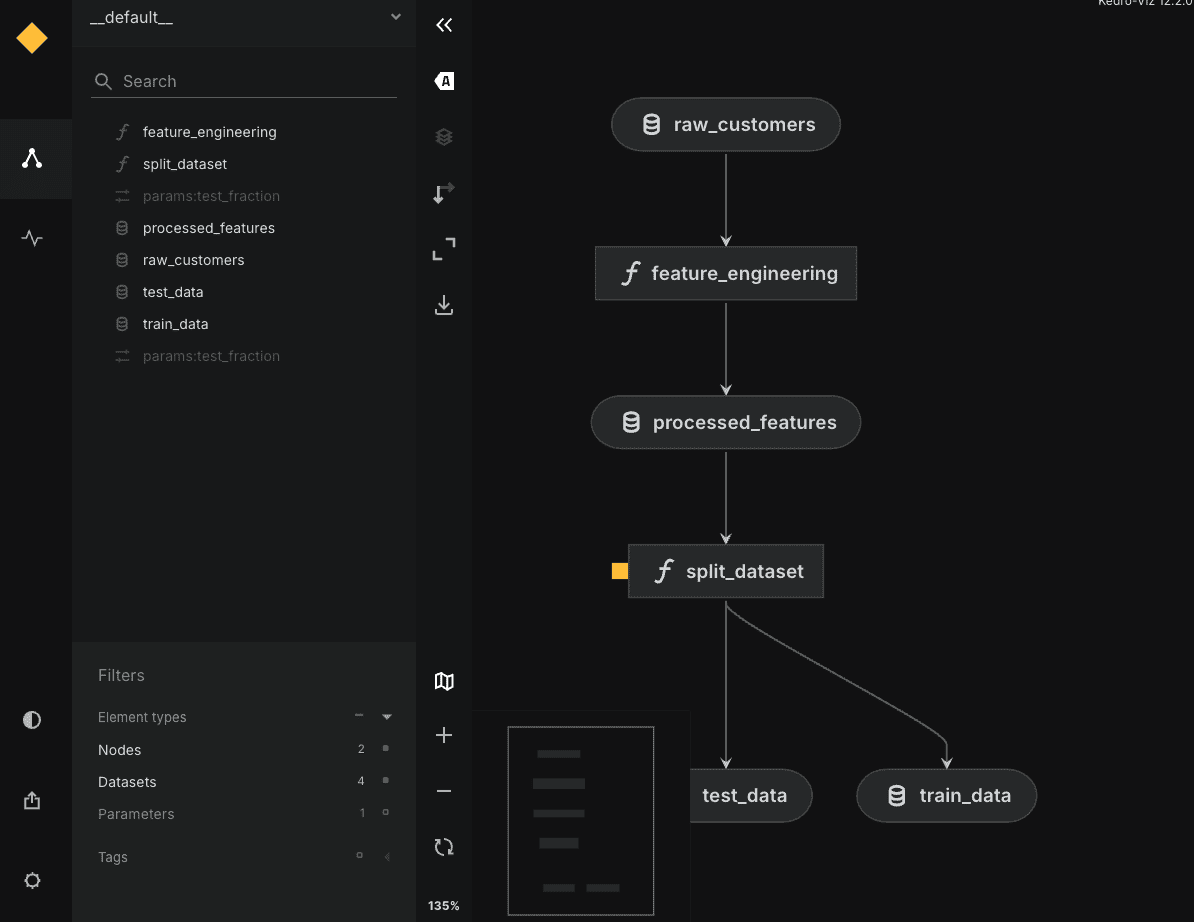
# Wrapping Up
We are going to go away additional exploration of this software for a attainable future article. For those who acquired right here, you had been capable of construct your first Kedro challenge and find out about its core parts and options, understanding how they work together alongside the best way.
Effectively finished!
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.