
This submit is co-written with Mark Ross from Atos.
Organizations pursuing AI transformation can face a well-known problem: methods to upskill their workforce at scale in a manner that modifications how groups construct, deploy, and use AI. Conventional AI coaching approaches—on-line programs, certification applications, and classroom-based instruction—are mandatory, however usually inadequate. Whereas they construct foundational information, many organizations battle with low engagement, restricted hands-on observe, and a niche between theoretical understanding and real-world utility. Consequently, groups could earn certifications with out gaining the boldness or expertise required to use AI meaningfully to enterprise issues.
By means of Atos’ partnership with AWS, we’ve lengthy acknowledged that hands-on studying is the lacking ingredient in efficient AI enablement. When mixed with structured e-learning and certification pathways, experiential studying helps translate information into affect. At this time, Atos staff maintain over 5,800 AWS Certifications and 11 Golden Jackets, reflecting our robust basis in cloud and AI expertise. However with a dedication to attaining a 100% AI-fluent workforce by 2026, we knew we wanted a studying mannequin that would scale engagement, speed up sensible expertise, and inspire engineers to use AI in lifelike situations.
To handle this, Atos partnered with AWS to ship a hands-on, gamified studying expertise via the AWS AI League—designed to maneuver past passive studying and immerse individuals in actual AI challenges. On this submit, we’ll discover how Atos used the AWS AI League to assist speed up AI schooling throughout 400+ individuals, spotlight the tangible advantages of gamified, experiential studying, and share actionable insights you’ll be able to apply to your individual AI enablement applications.
AI enablement via the AWS AI League
Whereas e-learning programs and certifications are a necessary basis, many organizations battle to translate that information into hands-on expertise, sustained engagement, and actual enterprise affect—significantly at scale.
The AWS AI League was designed to deal with this hole. Relatively than focusing solely on conceptual studying, this system combines hands-on experimentation with structured competitors, so builders can work instantly with generative AI instruments utilized in real-world environments. For Atos, this strategy supplied a strategy to speed up utilized AI expertise throughout the group whereas sustaining engagement, collaboration, and measurable outcomes.
The AWS AI League helps builders stage up their AI expertise by abstracting away deep infrastructure complexity whereas preserving the core mechanics of mannequin customization and analysis. Contributors work with Amazon SageMaker and Amazon SageMaker JumpStart to fine-tune giant language fashions (LLMs), gaining sensible expertise with methods which might be more and more central to enterprise AI adoption.
Why fine-tuning issues for enterprise use circumstances
Superb-tuning a big language mannequin is a type of switch studying—a machine studying approach the place a pre-trained mannequin is customized utilizing a smaller, domain-specific dataset reasonably than being educated from scratch. For enterprise groups, this strategy affords a realistic path to customization: it helps cut back coaching time and computational value whereas permitting fashions to replicate specialised information, terminology, and choice logic.
In observe, organizations that use fine-tuning can adapt general-purpose fashions to particular domains the place accuracy, reasoning, and explainability are essential. For Atos, this meant tailoring fashions to the insurance coverage underwriting area, the place understanding danger profiles, coverage situations, exclusions, and premium calculations requires greater than generic language fluency. The AWS AI League demonstrates that, with the proper construction and tooling, groups throughout roles—together with options architects, builders, consultants, and enterprise analysts—can fine-tune and deploy fashions with out requiring deep machine studying specialization. This makes fine-tuning a sensible functionality for accomplice organizations centered on delivering customer-ready AI options.
How the AWS AI League works
The AWS AI League follows a three-stage construction designed to construct hands-on, production-oriented AI expertise whereas sustaining momentum and engagement.This system begins with an immersive workshop that introduces the basics of fine-tuning utilizing SageMaker JumpStart. SageMaker JumpStart offers entry to pre-trained basis fashions via a guided interface, permitting individuals to concentrate on mannequin conduct and outcomes reasonably than infrastructure setup.Contributors then transfer into an intensive mannequin growth section. Throughout this stage, groups iterate throughout a number of fine-tuning methods, experimenting with dataset composition, augmentation methods, and hyperparameter settings. Mannequin submissions are evaluated on a dynamic leaderboard powered by an AI-based analysis system, which benchmarks efficiency throughout a constant set of standards. This construction encourages fast experimentation and makes progress seen, permitting groups to match their custom-made fashions in opposition to bigger baseline fashions.This system culminates in a reside, interactive finale. High-performing groups reveal their fashions via real-time challenges, with outputs evaluated utilizing a multi-dimensional scoring system. Technical judges assess depth and correctness, an AI benchmark measures goal efficiency, and viewers voting introduces a sensible, user-oriented perspective. Collectively, these dimensions reinforce the League’s purpose: turning hands-on studying into fashions that carry out effectively in real-world situations.
Atos’s use case – Clever Insurance coverage Underwriter
With this basis in place, Atos chosen a use case that intently displays actual buyer wants: the Clever Insurance coverage Underwriter. Developed via an AWS AI League occasion, the purpose was to fine-tune a big language mannequin able to analyzing advanced insurance coverage situations and offering expert-level underwriting steering. The mannequin was designed to evaluate danger, advocate applicable coverage situations or deductibles, counsel premium changes, and clearly clarify the reasoning behind every choice — all whereas aligning with skilled trade requirements.This use case was chosen not as a theoretical train, however as a practical instance of how generative AI can help underwriting professionals by bettering consistency and effectivity throughout insurance coverage product strains. Constructed on cost-effective, fine-tuned open supply fashions and powered by Amazon SageMaker, SageMaker Unified Studio, and Amazon S3, the answer incorporates a information base alongside reasoning and advice modules educated on proprietary underwriting information. The result’s an inexpensive, custom-made assistant that enhances crew productiveness, sharpens danger evaluation accuracy, and integrates seamlessly with the genuine trade experience underwriters already depend on.
Superb-tuning with Amazon SageMaker Studio and Amazon SageMaker JumpStart
AWS AI League individuals do their mannequin fine-tuning inside Amazon SageMaker Studio—a totally built-in, web-based growth atmosphere for machine studying. SageMaker Studio offers a low-code/no-code (LCNC) interface to construct, fine-tune, deploy, and monitor generative AI fashions end-to-end. By following this strategy, Atos individuals might concentrate on experimentation and innovation reasonably than infrastructure administration, serving to speed up time-to-value. AI League now additionally affords customization of Amazon Nova fashions via serverless SageMaker mannequin customization and agentic challenges constructed on prime of Amazon Bedrock AgentCore.
Customers comply with a streamlined sequence of steps inside Amazon SageMaker Studio:
- Choose a mannequin – SageMaker JumpStart affords a catalog of pre-trained, publicly obtainable basis fashions for duties reminiscent of textual content technology, summarization, and picture creation. Contributors can seamlessly browse and choose fashions from main suppliers, that are pre-integrated for personalization. For this competitors, individuals have been required to fine-tune the Meta Llama 3.2 3B Instruct mannequin, which is achieved in a no-code manner using Amazon SageMaker Jumpstart.
- Present a coaching dataset – Datasets saved in Amazon Easy Storage Service (Amazon S3) are related on to SageMaker, leveraging its nearly limitless storage capability for fine-tuning duties.
- Carry out fine-tuning – Customers can configure hyperparameters reminiscent of studying price, epochs, and batch dimension earlier than launching the fine-tuning job. SageMaker then manages the coaching course of, together with provisioning compute sources and logging progress.
- Deploy the mannequin – As soon as coaching is full, individuals can deploy their fashions instantly from SageMaker Studio for inference or import them into Amazon Bedrock, which offers a totally managed atmosphere for scalable manufacturing deployment.
- Consider and iterate – In the course of the AWS AI League, analysis was carried out utilizing LLM-as-a-Decide, an inner judging system that robotically scored fashions on high quality, accuracy, and responsiveness.
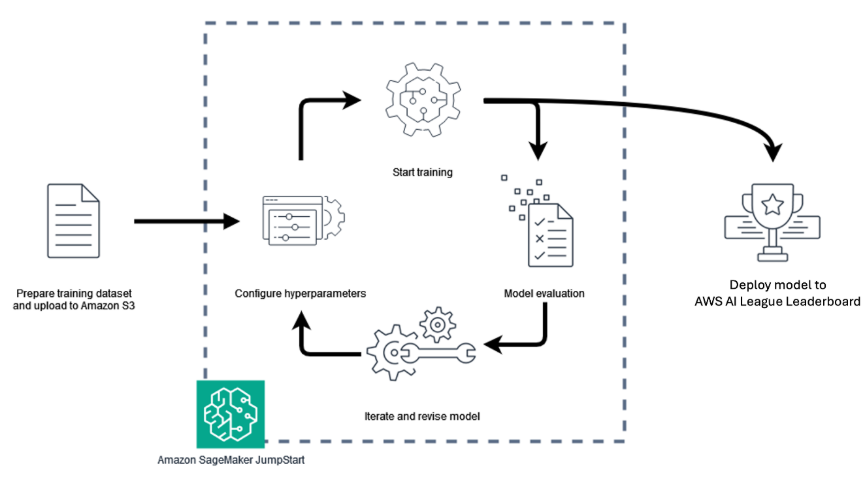
This simplified workflow, depicted above, reveals the AWS AI League mannequin growth lifecycle and the way it helps cut back the complexity of creating and operationalizing specialised AI fashions, whereas preserving efficiency, transparency, and cost-efficiency. For Atos, this hands-on course of offers a sensible, production-ready basis for extending generative AI capabilities into customer-facing options. Contributors have been required to generate insurance coverage use case datasets in JSON Traces (JSONL) format. Every file consisted of two fields:
- Instruction – the immediate or query for the Clever Insurance coverage Underwriter to contemplate.
- Response – an instance of the best reply the fine-tuned mannequin ought to produce.
These datasets shaped the muse for the mannequin fine-tuned section.
To simplify dataset creation, individuals got entry to an AWS offered PartyRock utility which supplied an simple-to-use interface for producing and exporting information. As soon as full, the datasets have been uploaded to Amazon Easy Storage Service (Amazon S3), the place they served because the enter for mannequin fine-tuning.
Throughout fine-tuning, individuals might regulate a spread of hyperparameters to affect the fine-tuning together with, however not restricted, to the next:
- Epochs – The variety of occasions the fine-tuning course of will cross over the dataset .
- Studying price – The weighting utilized to the updates the mannequin makes every time it passes over the info.
After fine-tuning, individuals deployed their custom-made language fashions in Amazon SageMaker and used the endpoints to carry out inference. This allowed them to look at how the fine-tuned fashions responded to pattern insurance coverage queries and assessed the standard of their outputs
Outcomes various throughout individuals. Some fine-tuned fashions delivered robust, contextually related solutions, whereas others displayed indicators of overfitting — a situation the place a mannequin learns the coaching information too exactly, resulting in repetitive or irrelevant responses when uncovered to new inputs. Overtrained fashions, as an example, are likely to echo phrases from the dataset reasonably than generalizing to unseen situations. Armed with these insights, individuals evaluated their fashions’ efficiency and decided which variations to undergo the AWS AI League leaderboard and which to refine or discard. This iterative course of emphasised experimentation, information high quality, and parameter tuning as key success elements in attaining high-performing generative AI fashions.
Gamification ignites participation.
Palms-on labs and workshops are a good way to supply individuals with a chance to study by doing however offering a gamified strategy the place you’re competing with different individuals takes it to a different stage. Atos noticed this with the AWS AI League. Following an preliminary kick-off workshop, Atos individuals created and submitted preliminary fashions, earlier than turning their strategy to maximizing their scores on the leaderboard by iteratively creating or bettering their datasets and tuning their hyperparameters over a two-week digital league. By the completion of the digital spherical, Atos had their finest stage of engagement for a gamified competitors, with 409 individuals on the leaderboard, with over 4,100 fine-tuned fashions having been created.

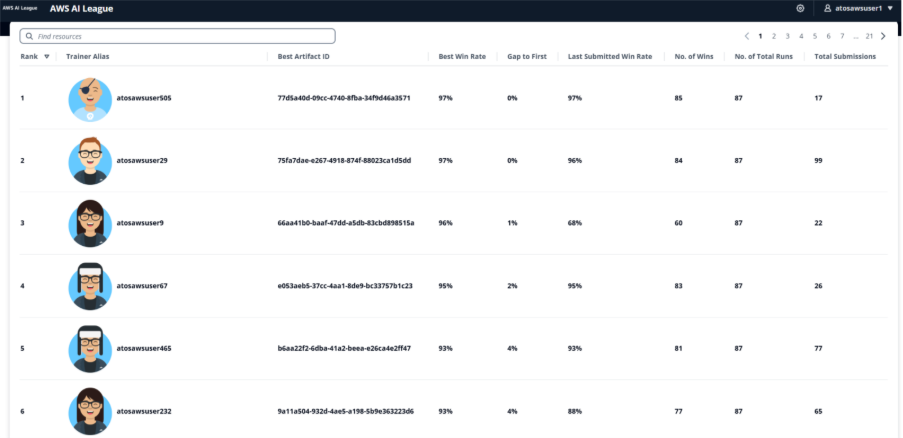
Regardless of the gamified nature of the competitors, communication channels and workplace hours have been full of individuals balancing sharing data with one another while avoiding giving all the things away. It was a terrific stability which made positive people who needed to participate and enhance have been supported sufficient, while additionally having to determine some issues out for themselves. The pleasant competitors was extremely fierce on the similar time, and to make the highest 5 a participant’s fine-tuned mannequin was required to attain at the very least a 93%-win price in opposition to the solutions offered by a a lot bigger mannequin, exhibiting the facility of fine-tuning for area particular information. The digital stage of the competitors was absolutely automated with a Llama 3.2 90B LLM as a decide offering the scoring. Upon completion of the digital spherical, the highest 5 individuals have been taken ahead to a reside gameshow finale, competing for a spot within the AWS finals throughout AWS re:Invent Las Vegas in December.
To rank the highest 5, the reside finale launched extra scoring strategies, in addition to offering the finalists with a chance to affect their mannequin’s response. Finale scoring was cut up between 40% for LLM-as-a-Decide, 40% between our 5 human professional judges from Atos, and 20% for viewers voting. 5 rounds of questions offered an ample likelihood to take a look at the mannequin’s efficiency, and through every query the finalists have been in a position to affect mannequin output with some system prompting, and hyperparameter tuning for inference (temperature and prime p to manage the randomness and creativity of the reply). Finalists solely had 90 seconds to tune their inference and submit their ultimate solutions, so it was a tense and shut competitors.
Tricks to fine-tune your strategy to success
The fine-tuning competitors comes down to 2 key parts – the individuals’ means to generate a great dataset for the topic of the competitors, and a capability to search out the optimum hyperparameters to make use of for fine-tuning with the dataset.
While AWS offered a PartyRock utility to generate a dataset, among the Atos individuals took inspiration from the offered utility and remixed their very own. The concept of this utility was to a) generate extra information and b) generate numerous and distinctive information, each enhancements over the AWS offered utility. Some individuals selected to make use of various generative AI instruments they’d entry to, to generate their very own responses, however this required them to create system prompts that the PartyRock utility took care of to confirm information was offered in the proper format, for instance.
Bigger datasets didn’t essentially result in higher outcomes, so there was additionally a requirement to evaluation the datasets that had been generated and work out methods to enhance them. Profitable individuals additionally used generative AI for this, with basic suggestions on methods to enhance (e.g. for the Atos use case areas of insurance coverage that will have been lacking from the dataset), in addition to extra particular suggestions and actions being taken on the dataset, for instance eradicating objects within the dataset that have been too related. This resulted in a new PartyRock utility being created and shared amongst individuals to supply enchancment ideas.
Contributors had management over a number of essential hyperparameters that considerably influenced fine-tuning outcomes. Epochs decide what number of occasions the coaching course of passes over your complete dataset—too few epochs lead to underfitting the place the mannequin hasn’t discovered sufficient, whereas too many could cause overfitting the place the mannequin memorizes coaching information reasonably than generalizing. Studying price controls the magnitude of updates the mannequin makes throughout every coaching step; a excessive studying price allows sooner coaching however dangers overshooting optimum values, whereas a low studying price offers extra exact changes however requires longer coaching time.
Extra parameters included batch dimension, which impacts coaching stability and reminiscence utilization, and Low-Rank Adaptation (LoRA) parameters reminiscent of lora_r and lora_alpha, which management the effectivity of the fine-tuning course of. Profitable individuals approached hyperparameter tuning systematically, both altering single values at a time to isolate their results or adjusting associated parameters collectively whereas rigorously logging outcomes to establish patterns
Understanding mannequin efficiency and overfitting
This discrepancy highlights an vital facet of mannequin conduct. Throughout fine-tuning, the mannequin regularly turns into higher at answering questions derived from the coaching and analysis datasets, that are subsets of the identical underlying information. Nonetheless, the leaderboard evaluated every mannequin utilizing 87 unseen questions — examples that have been not included within the coaching information.
Throughout fine-tuning, individuals might additionally monitor metrics reminiscent of analysis loss (eval-loss) and perplexity (ppl), which assist point out how effectively a mannequin suits the coaching information. Decrease eval-loss and perplexity usually counsel the mannequin is studying the dataset successfully, whereas giant gaps between coaching and analysis metrics can sign overfitting and diminished means to generalize. Analysis loss is the loss worth calculated on the validation or analysis dataset throughout coaching. It measures how effectively the mannequin predicts the proper subsequent tokens for examples it has in a roundabout way educated on in that step. Perplexity is a generally used metric for language fashions that represents how “shocked” the mannequin is by the analysis information. Decrease perplexity signifies the mannequin is best in a position to predict the proper subsequent tokens, suggesting it has discovered the underlying patterns within the dataset extra successfully.
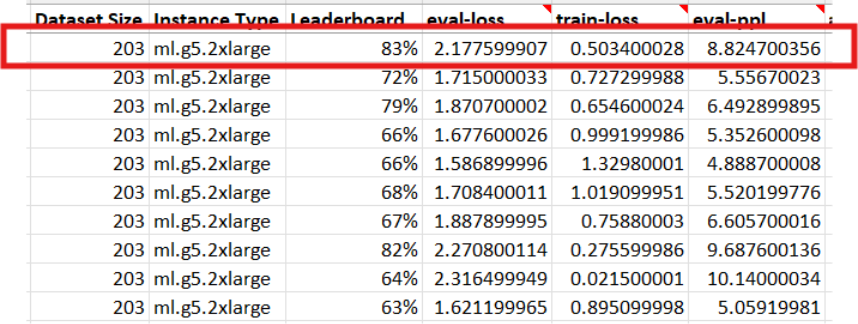
Consequently, some fashions turned overfitted, which means they carried out extraordinarily effectively on the info they’d seen however struggled to generalize to new questions. This sample may very well be noticed by deploying the mannequin to an inference endpoint and interacting with it instantly: overfitted fashions usually produced irrelevant or repetitive responses, a transparent signal that they’d memorized patterns from the coaching set reasonably than studying to motive extra broadly.
Upskilling ambitions achieved
By means of the AWS AI League Atos’ ambition was to place generative AI tech into individuals’ fingers and permit them to really feel extra assured speaking about and utilizing it after the occasion, while having some enjoyable and crew constructing alongside the way in which. Contributors discovered how a smaller 3 billion parameter mannequin (Llama 3.2 3B Instruct) might outperform a a lot bigger 90 billion parameter mannequin via fine-tuning with related area information, on this occasion turning into a real digital insurance coverage underwriter assistant in a position to reply advanced circumstances with applicable suggestions on danger areas and applicable ranges of deductibles and so forth. As generative AI and agentic AI develop, we see extra use circumstances for particular information inside AI brokers. Superb tuning a mannequin to supply this particular information can lead to a a lot smaller mannequin which might present sooner inference at a decrease value than bigger fashions, one thing that shall be essential as we enter the age of agentic AI. As you progress towards agentic AI architectures the place a number of specialised AI brokers collaborate to unravel advanced issues, having cost-effective, domain-specific fashions turns into essential. Superb-tuned fashions can function specialised brokers inside bigger agentic techniques, every dealing with particular domains whereas sustaining quick response occasions and manageable prices.
Conclusion
As you proceed to discover generative AI implementations, the flexibility to effectively construct, customise, and deploy specialised fashions turns into more and more essential. The AWS AI League offers a structured pathway for companions like Atos to deepen their AI capabilities—whether or not enhancing current choices or creating fully new, AI-driven providers that tackle real-world buyer wants. The AWS AI League program demonstrates how gamified studying can speed up companions’ AI innovation whereas driving measurable enterprise outcomes. The AWS AI League delivered measurable outcomes for Atos past participant engagement. This system confirmed that fine-tuned 3B parameter fashions might obtain win charges exceeding 93% in opposition to a lot bigger 90B parameter fashions for domain-specific duties, demonstrating the cost-efficiency of specialised mannequin growth. From a useful resource perspective, the fine-tuned fashions required much less computational infrastructure—operating on ml.g5.4xlarge situations in comparison with the ml.g5.48xlarge situations wanted for bigger base fashions—translating to value financial savings for inference at scale. The compressed studying timeline was significantly invaluable, with individuals with the ability to develop sensible AI expertise in simply two weeks that may sometimes require months of conventional coaching. The 409 energetic individuals and 4,100+ fine-tuned fashions created in the course of the occasion represented an acceleration in Atos’s journey towards their 2026 purpose of 100% AI fluency throughout their workforce. Publish-event surveys indicated that 85% of individuals felt extra assured discussing and implementing generative AI options with prospects, instantly supporting Atos’s enterprise goals
If you happen to’re fascinated about constructing AI capabilities via hands-on, gamified studying, you’ll be able to study extra about internet hosting their very own AWS AI League occasion on the official website.
To study extra about implementing AI options:
You can too go to the AWS Synthetic Intelligence weblog for extra tales about companions and prospects implementing generative AI options throughout numerous industries.
Concerning the authors