
Giant language fashions (LLMs) have quickly developed, changing into integral to purposes starting from conversational AI to complicated reasoning duties. Nevertheless, as fashions develop in measurement and functionality, successfully evaluating their efficiency has change into more and more difficult. Conventional benchmarking metrics like perplexity and BLEU scores usually fail to seize the nuances of real-world interactions, making human-aligned analysis frameworks essential. Understanding how LLMs are assessed can result in extra dependable deployments and truthful comparisons throughout totally different fashions.
On this put up, we discover automated and human-aligned judging strategies based mostly on LLM-as-a-judge. LLM-as-a-judge refers to utilizing a extra highly effective LLM to judge and rank responses generated by different LLMs based mostly on predefined standards comparable to correctness, coherence, helpfulness, or reasoning depth. This method has change into more and more well-liked as a result of scalability, consistency, sooner iteration, and cost-efficiency in comparison with solely counting on human judges. We focus on totally different LLM-as-a-judge analysis eventualities, together with pairwise comparisons, the place two fashions or responses are judged towards one another, and single-response scoring, the place particular person outputs are rated based mostly on predefined standards. To offer concrete insights, we use MT-Bench and Enviornment-Exhausting, two extensively used analysis frameworks. MT-Bench affords a structured, multi-turn analysis method tailor-made for chatbot-like interactions, whereas Enviornment-Exhausting focuses on rating LLMs by way of head-to-head response battles in difficult reasoning and instruction-following duties. These frameworks purpose to bridge the hole between automated and human judgment, ensuring that LLMs aren’t evaluated solely based mostly on artificial benchmarks but in addition on sensible use circumstances.
The repositories for MT-Bench and Enviornment-Exhausting have been initially developed utilizing OpenAI’s GPT API, primarily using GPT-4 because the decide. Our workforce has expanded its performance by integrating it with the Amazon Bedrock API to allow utilizing Anthropic’s Claude Sonnet on Amazon as decide. On this put up, we use each MT-Bench and Enviornment-Exhausting to benchmark Amazon Nova fashions by evaluating them to different main LLMs accessible by way of Amazon Bedrock.
Amazon Nova fashions and Amazon Bedrock
Our examine evaluated all 4 fashions from the Amazon Nova household, together with Amazon Nova Premier, which is the latest addition to the household. Launched at AWS re:Invent in December 2024, Amazon Nova fashions are designed to supply frontier-level intelligence with main price-performance ratios. These fashions rank among the many quickest and most economical choices of their respective intelligence classes and are particularly optimized for powering enterprise generative AI purposes in a cheap, safe, and dependable method.
The understanding mannequin household contains 4 distinct tiers: Amazon Nova Micro (text-only, designed for ultra-efficient edge deployment), Amazon Nova Lite (multimodal, optimized for versatility), Amazon Nova Professional (multimodal, providing a perfect stability between intelligence and pace for many enterprise purposes), and Amazon Nova Premier (multimodal, representing essentially the most superior Nova mannequin for complicated duties and serving as a instructor for mannequin distillation). Amazon Nova fashions assist a variety of purposes, together with coding, reasoning, and structured textual content technology.
Moreover, by way of Amazon Bedrock Mannequin Distillation, clients can switch the intelligence capabilities of Nova Premier to sooner, less expensive fashions comparable to Nova Professional or Nova Lite, tailor-made to particular domains or use circumstances. This performance is accessible by way of each the Amazon Bedrock console and APIs, together with the Converse API and Invoke API.
MT-Bench evaluation
MT-Bench is a unified framework that makes use of LLM-as-a-judge, based mostly on a set of predefined questions. The analysis questions are a set of difficult multi-turn open-ended questions designed to judge chat assistants. Customers even have the flexibleness to outline their very own query and reply pairs in a method that fits their wants. The framework presents fashions with difficult multi-turn questions throughout eight key domains:
- Writing
- Roleplay
- Reasoning
- Arithmetic
- Coding
- Information Extraction
- STEM
- Humanities
The LLMs are evaluated utilizing two varieties of analysis:
- Single-answer grading – This mode asks the LLM decide to grade and provides a rating to a mannequin’s reply immediately with out pairwise comparability. For every flip, the LLM decide provides a rating on a scale of 0–10. Then the common rating is computed on all turns.
- Win-rate based mostly grading – This mode makes use of two metrics:
- pairwise-baseline – Run a pairwise comparability towards a baseline mannequin.
- pairwise-all – Run a pairwise comparability between all mannequin pairs on all questions.
Analysis setup
On this examine, we employed Anthropic’s Claude 3.7 Sonnet as our LLM decide, given its place as one of the superior language fashions accessible on the time of our examine. We centered completely on single-answer grading, whereby the LLM decide immediately evaluates and scores model-generated responses with out conducting pairwise comparisons.
The eight domains coated in our examine will be broadly categorized into two teams: these with definitive floor fact and people with out. Particularly, Reasoning, Arithmetic, Coding, and Information Extraction fall into the previous class as a result of they usually have reference solutions towards which responses will be objectively evaluated. Conversely, Writing, Roleplay, STEM, and Humanities usually lack such clear-cut floor fact. Right here we offer an instance query from the Writing and Math classes:
To account for this distinction, MT-Bench employs totally different judging prompts for every class (consult with the next GitHub repo), tailoring the analysis course of to the character of the duty at hand. As proven within the following analysis immediate, for questions with out a reference reply, MT-Bench adopts the single-v1 immediate, solely passing the query and model-generated reply. When evaluating questions with a reference reply, it solely passes the reference_answer, as proven within the single-math-v1 immediate.
General efficiency evaluation throughout Amazon Nova Fashions
In our analysis utilizing Anthropic’s Claude 3.7 Sonnet as an LLM-as-a-judge framework, we noticed a transparent efficiency hierarchy amongst Amazon Nova fashions. The scores ranged from 8.0 to eight.6, with Amazon Nova Premier attaining the very best median rating of 8.6, adopted carefully by Amazon Nova Professional at 8.5. Each Amazon Nova Lite and Nova Micro achieved respectable median scores of 8.0.
What distinguishes these fashions past their median scores is their efficiency consistency. Nova Premier demonstrated essentially the most steady efficiency throughout analysis classes with a slim min-max margin of 1.5 (starting from 7.94 to 9.47). As compared, Nova Professional confirmed larger variability with a min-max margin of two.7 (from 6.44 to 9.13). Equally, Nova Lite exhibited extra constant efficiency than Nova Micro, as evidenced by their respective min-max margins. For enterprise deployments the place response time is essential, Nova Lite and Nova Micro excel with lower than 6-second common latencies for single question-answer technology. This efficiency attribute makes them notably appropriate for edge deployment eventualities and purposes with strict latency necessities. When factoring of their decrease price, these fashions current compelling choices for a lot of sensible use circumstances the place the slight discount in efficiency rating is a suitable trade-off.
Apparently, our evaluation revealed that Amazon Nova Premier, regardless of being the most important mannequin, demonstrates superior token effectivity. It generates extra concise responses that eat as much as 190 fewer tokens for single question-answer technology than comparable fashions. This commentary aligns with analysis indicating that extra subtle fashions are usually more practical at filtering irrelevant info and structuring responses effectively.
The slim 0.6-point differential between the very best and lowest performing fashions suggests that each one Amazon Nova variants show robust capabilities. Though bigger fashions comparable to Nova Premier supply marginally higher efficiency with larger consistency, smaller fashions present compelling alternate options when latency and price are prioritized. This efficiency profile provides builders flexibility to pick out the suitable mannequin based mostly on their particular utility necessities.
The next graph summarizes the general efficiency scores and latency for all 4 fashions.
The next desk reveals token consumption and price evaluation for Amazon Nova Fashions.
| Mannequin | Avg. whole tokens per question | Value per 1k enter tokens | Avg. price per question (cents) |
| Amazon Nova Premier | 2154 | $0.0025 | $5.4 |
| Amazon Nova Professional | 2236 | $0.0008 | $1.8 |
| Amazon Nova Lite | 2343 | $0.00006 | $0.14 |
| Amazon Nova Micro | 2313 | $0.000035 | $0.08 |
Class-specific mannequin comparability
The next radar plot compares the Amazon Nova fashions throughout all eight domains.

The radar plot reveals distinct efficiency patterns throughout the Amazon Nova mannequin household, with a transparent stratification throughout domains. Nova Premier persistently outperforms its counterparts, displaying specific strengths in Math, Reasoning, Humanities, and Extraction, the place it achieves scores approaching or exceeding 9. Nova Professional follows carefully behind Premier in most classes, sustaining aggressive efficiency particularly in Writing and Coding, whereas displaying extra pronounced gaps in Humanities, Reasoning, and Math. Each Nova Lite and Micro show related efficiency profiles to one another, with their strongest displaying in Roleplay, and their most vital limitations in Humanities and Math, the place the differential between Premier and the smaller fashions is most pronounced (roughly 1.5–3 factors).
The constant efficiency hierarchy throughout all domains (Premier > Professional > Lite ≈ Micro) aligns with mannequin measurement and computational sources, although the magnitude of those variations varies considerably by class. Math and reasoning emerge among the many most discriminating domains for mannequin functionality evaluation and counsel substantial profit from the extra scale of Amazon Nova Premier. Nevertheless, workloads centered on inventive content material (Roleplay, Writing) present essentially the most constant efficiency throughout the Nova household and counsel smaller fashions as compelling choices given their latency and price advantages. This domain-specific evaluation affords practitioners priceless steering when choosing the suitable Nova mannequin based mostly on their utility’s main information necessities.
On this examine, we adopted Anthropic’s Claude 3.7 Sonnet as the one LLM decide. Nevertheless, though Anthropic’s Claude 3.7 Sonnet is a well-liked selection for LLM judging on account of its capabilities, research have proven that it does exhibit sure bias (for instance, it prefers longer responses). If permitted by time and sources, take into account adopting a multi-LLM decide analysis framework to successfully cut back biases intrinsic to particular person LLM judges and enhance analysis reliability.
Enviornment-Exhausting-Auto evaluation
Enviornment-Exhausting-Auto is a benchmark that makes use of 500 difficult prompts as a dataset to judge totally different LLMs utilizing LLM-as-a-judge. The dataset is curated by way of an automatic pipeline referred to as BenchBuilder, which makes use of LLMs to robotically cluster, grade, and filter open-ended prompts from giant, crowd-sourced datasets comparable to Chatbot-Enviornment to allow steady benchmarking with out a human within the loop. The paper stories that the brand new analysis metrics present 3 times increased separation of mannequin performances in comparison with MT-Bench and obtain a 98.6% correlation with human desire rankings.
Take a look at framework and methodology
The Enviornment-Exhausting-Auto benchmarking framework evaluates totally different LLMs utilizing a pairwise comparability. Every mannequin’s efficiency is quantified by evaluating it towards a robust baseline mannequin, utilizing a structured, rigorous setup to generate dependable and detailed judgments. We use the next parts for the analysis:
- Pairwise comparability setup – As a substitute of evaluating fashions in isolation, they’re in contrast immediately with a robust baseline mannequin. This baseline gives a set commonplace, making it easy to grasp how the fashions carry out relative to an already high-performing mannequin.
- Choose mannequin with fine-grained classes – A strong mannequin (Anthropic’s Claude 3.7 Sonnet) is used as a decide. This decide doesn’t merely determine which mannequin is healthier, it additionally categorizes the comparability into 5 detailed desire labels. By utilizing this nuanced scale, giant efficiency gaps are penalized extra closely than small ones, which helps separate fashions extra successfully based mostly on efficiency variations:
A >> B(A is considerably higher than B)A > B(A is healthier than B)A ~= B(A and B are related)B > A(B is healthier than A)B >> A(B is considerably higher than A)
- Chain-of-thought (CoT) prompting – CoT prompting encourages the decide mannequin to elucidate its reasoning earlier than giving a ultimate judgment. This course of can result in extra considerate and dependable evaluations by serving to the mannequin analyze every response in depth slightly than making a snap determination.
- Two-game setup to keep away from place bias – To attenuate bias which may come up from a mannequin persistently being offered first or second, every mannequin pair is evaluated twice, swapping the order of the fashions. This fashion, if there’s a desire for fashions in sure positions, the setup controls for it. The full variety of judgments is doubled (for instance, 500 queries x 2 positions = 1,000 judgments).
- Bradley-Terry mannequin for scoring – After the comparisons are made, the Bradley-Terry mannequin is utilized to calculate every mannequin’s ultimate rating. This mannequin makes use of pairwise comparability information to estimate the relative power of every mannequin in a method that displays not solely the variety of wins but in addition the power of wins. This scoring methodology is extra sturdy than merely calculating win-rate as a result of it accounts for pairwise outcomes throughout the fashions.
- Bootstrapping for statistical stability – By repeatedly sampling the comparability outcomes (bootstrapping), the analysis turns into statistically steady. This stability is useful as a result of it makes certain the mannequin rankings are dependable and fewer delicate to random variations within the information.
- Model management – Sure model options like response size and markdown formatting are separated from content material high quality, utilizing model controls, to supply a clearer evaluation of every mannequin’s intrinsic capabilities.
The unique work focuses on pairwise comparability solely. For our benchmarking, we additionally included our personal implementation of single-score judgment, taking inspiration from MT-Bench. We once more use Anthropic’s Claude 3.7 Sonnet because the decide and use the next immediate for judging with out a reference mannequin:
Efficiency comparability
We evaluated 5 fashions, together with Amazon Nova Premier, Amazon Nova Professional, Amazon Nova Lite, Amazon Nova Micro, DeepSeek-R1, and a robust reference mannequin. The Enviornment-Exhausting benchmark generates confidence intervals by bootstrapping, as defined earlier than. The 95% confidence interval reveals the uncertainty of the fashions and is indicative of mannequin efficiency. From the next plot, we will see that each one the Amazon Nova fashions get a excessive pairwise Bradley-Terry rating. It needs to be famous that the Bradley-Terry rating for the reference mannequin is 5; it is because Bradley-Terry scores are computed by pairwise comparisons the place the reference mannequin is likely one of the fashions within the pair. So, for the reference mannequin, the rating shall be 50%, and since the full rating is normalized between 0 and 10, the reference mannequin has a rating of 5.
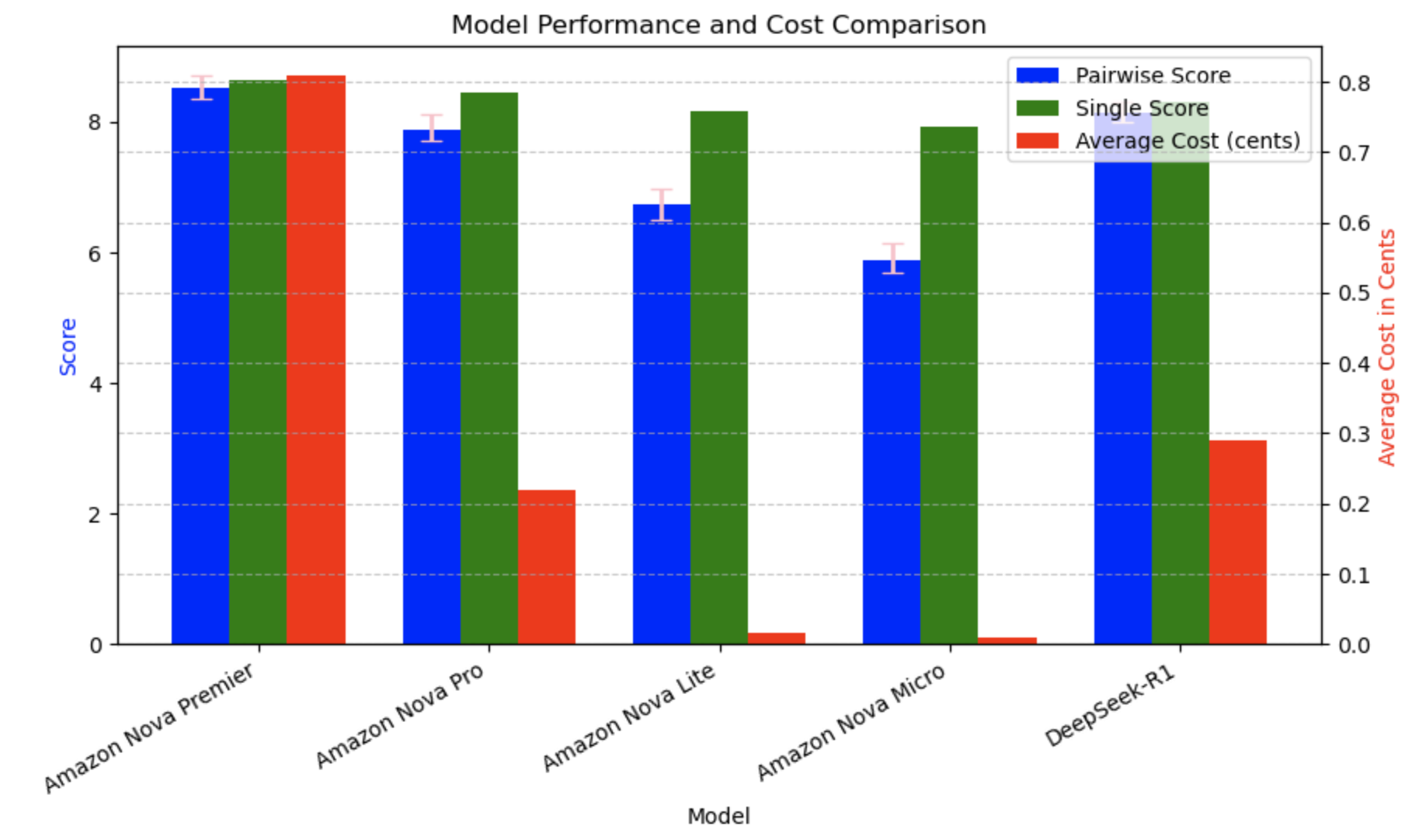
The boldness interval evaluation, as proven within the following desk, was finished to statistically consider the Amazon Nova mannequin household alongside DeepSeek-R1, offering deeper insights past uncooked scores. Nova Premier leads the pack (8.36–8.72), with DeepSeek-R1 (7.99–8.30) and Nova Professional (7.72–8.12) following carefully. The overlapping confidence intervals amongst these prime performers point out statistically comparable capabilities. Nova Premier demonstrates robust efficiency consistency with a decent confidence interval (−0.16, +0.20), whereas sustaining the very best general scores. A transparent statistical separation exists between these main fashions and the purpose-built Nova Lite (6.51–6.98) and Nova Micro (5.68–6.14), that are designed for various use circumstances. This complete evaluation confirms the place of Nova Premier as a prime performer, with the complete Nova household providing choices throughout the efficiency spectrum to fulfill assorted buyer necessities and useful resource constraints.
| Mannequin | Pairwise rating twenty fifth quartile | Pairwise rating seventy fifth quartile | Confidence interval |
| Amazon Nova Premier | 8.36 | 8.72 | (−0.16, +0.20) |
| Amazon Nova Professional | 7.72 | 8.12 | (−0.18, +0.23) |
| Amazon Nova Lite | 6.51 | 6.98 | (−0.22, +0.25) |
| Amazon Nova Micro | 5.68 | 6.14 | (−0.21, +0.25) |
| DeepSeek-R1 | 7.99 | 8.30 | (−0.15, +0.16) |
Price per output token is likely one of the contributors to the general price of the LLM mannequin and impacts the utilization. The associated fee was computed based mostly on the common output tokens over the five hundred responses. Though Amazon Nova Premier leads in efficiency (85.22), Nova Mild and Nova Micro supply compelling worth regardless of their wider confidence intervals. Nova Micro delivers 69% of the efficiency of Nova Premier at 89 occasions cheaper price, whereas Nova Mild achieves 79% of the capabilities of Nova Premier, at 52 occasions lower cost. These dramatic price efficiencies make the extra inexpensive Nova fashions engaging choices for a lot of purposes the place absolute prime efficiency isn’t important, highlighting the efficient performance-cost tradeoffs throughout the Amazon Nova household.
Conclusion
On this put up, we explored using LLM-as-a-judge by way of MT-Bench and Enviornment-Exhausting benchmarks to judge mannequin efficiency rigorously. We then in contrast Amazon Nova fashions towards a number one reasoning mannequin, that’s, DeepSeek-R1 hosted on Amazon Bedrock, analyzing their capabilities throughout varied duties. Our findings point out that Amazon Nova fashions ship robust efficiency, particularly in Extraction, Humanities, STEM, and Roleplay, whereas sustaining decrease operational prices, making them a aggressive selection for enterprises seeking to optimize effectivity with out compromising on high quality. These insights spotlight the significance of benchmarking methodologies in guiding mannequin choice and deployment selections in real-world purposes.
For extra info on Amazon Bedrock and the newest Amazon Nova fashions, consult with the Amazon Bedrock Person Information and Amazon Nova Person Information. The AWS Generative AI Innovation Middle has a gaggle of AWS science and technique consultants with complete experience spanning the generative AI journey, serving to clients prioritize use circumstances, construct a roadmap, and transfer options into manufacturing. Take a look at Generative AI Innovation Middle for our newest work and buyer success tales.
In regards to the authors
 Mengdie (Flora) Wang is a Information Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization strategies and agent-based AI programs, serving to organizations harness the complete potential of generative AI know-how. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
Mengdie (Flora) Wang is a Information Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization strategies and agent-based AI programs, serving to organizations harness the complete potential of generative AI know-how. Previous to AWS, Flora earned her Grasp’s diploma in Pc Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
 Baishali Chaudhury is an Utilized Scientist on the Generative AI Innovation Middle at AWS, the place she focuses on advancing Generative AI options for real-world purposes. She has a robust background in pc imaginative and prescient, machine studying, and AI for healthcare. Baishali holds a PhD in Pc Science from College of South Florida and PostDoc from Moffitt Most cancers Centre.
Baishali Chaudhury is an Utilized Scientist on the Generative AI Innovation Middle at AWS, the place she focuses on advancing Generative AI options for real-world purposes. She has a robust background in pc imaginative and prescient, machine studying, and AI for healthcare. Baishali holds a PhD in Pc Science from College of South Florida and PostDoc from Moffitt Most cancers Centre.
 Rahul Ghosh is an Utilized Scientist at Amazon’s Generative AI Innovation Middle, the place he works with AWS clients throughout totally different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Pc Science from the College of Minnesota.
Rahul Ghosh is an Utilized Scientist at Amazon’s Generative AI Innovation Middle, the place he works with AWS clients throughout totally different verticals to expedite their use of Generative AI. Rahul holds a Ph.D. in Pc Science from the College of Minnesota.
 Jae Oh Woo is a Senior Utilized Scientist on the AWS Generative AI Innovation Middle, the place he focuses on creating customized options and mannequin customization for a various vary of use circumstances. He has a robust ardour for interdisciplinary analysis that connects theoretical foundations with sensible purposes within the quickly evolving area of generative AI. Previous to becoming a member of Amazon, Jae Oh was a Simons Postdoctoral Fellow on the College of Texas at Austin. He holds a Ph.D. in Utilized Arithmetic from Yale College.
Jae Oh Woo is a Senior Utilized Scientist on the AWS Generative AI Innovation Middle, the place he focuses on creating customized options and mannequin customization for a various vary of use circumstances. He has a robust ardour for interdisciplinary analysis that connects theoretical foundations with sensible purposes within the quickly evolving area of generative AI. Previous to becoming a member of Amazon, Jae Oh was a Simons Postdoctoral Fellow on the College of Texas at Austin. He holds a Ph.D. in Utilized Arithmetic from Yale College.
 Jamal Saboune is an Utilized Science Supervisor with AWS Generative AI Innovation Middle. He’s at present main a workforce centered on supporting AWS clients construct revolutionary and scalable Generative AI merchandise throughout a number of industries. Jamal holds a PhD in AI and Pc Imaginative and prescient from the INRIA Lab in France, and has a protracted R&D expertise designing and constructing AI options that add worth to customers.
Jamal Saboune is an Utilized Science Supervisor with AWS Generative AI Innovation Middle. He’s at present main a workforce centered on supporting AWS clients construct revolutionary and scalable Generative AI merchandise throughout a number of industries. Jamal holds a PhD in AI and Pc Imaginative and prescient from the INRIA Lab in France, and has a protracted R&D expertise designing and constructing AI options that add worth to customers.
 Wan Chen is an Utilized Science Supervisor on the Generative AI Innovation Middle. As a ML/AI veteran in tech business, she has big selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence, and may be very passionate to push the boundary of AI analysis and utility to reinforce human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia, and had labored as postdoctoral fellow in Oxford College.
Wan Chen is an Utilized Science Supervisor on the Generative AI Innovation Middle. As a ML/AI veteran in tech business, she has big selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence, and may be very passionate to push the boundary of AI analysis and utility to reinforce human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia, and had labored as postdoctoral fellow in Oxford College.
 Anila Joshi has greater than a decade of expertise constructing AI options. As a AWSI Geo Chief at AWS Generative AI Innovation Middle, Anila pioneers revolutionary purposes of AI that push the boundaries of chance and speed up the adoption of AWS companies with clients by serving to clients ideate, establish, and implement safe generative AI options.
Anila Joshi has greater than a decade of expertise constructing AI options. As a AWSI Geo Chief at AWS Generative AI Innovation Middle, Anila pioneers revolutionary purposes of AI that push the boundaries of chance and speed up the adoption of AWS companies with clients by serving to clients ideate, establish, and implement safe generative AI options.