
This put up was co-written with Andrew Browning, Anthony Doolan, Jerome Ronquillo, Jeff Burke, Chiheb Boussema, and Naisha Agarwal from UCLA.
The College of California, Los Angeles (UCLA) is house to 16 Nobel Laureates and has been ranked the #1 public college in the US for 8 consecutive years. The Workplace of Superior Analysis Computing (OARC) at UCLA is the know-how growth accomplice to the analysis enterprise, offering each mental and technical know-how to show analysis into actuality. The UCLA Heart for Analysis and Engineering in Media and Efficiency (REMAP) approached OARC to construct a set of AI microservices to help an immersive manufacturing of the musical, Xanadu.
REMAP’s manufacturing of Xanadu, in collaboration with the UCLA Division of Theater’s Ray Bolger Musical Theater program, was designed to be an immersive, participatory efficiency throughout which the viewers collaboratively created media through the use of cell phone gestures to attract photographs on 13 x 9 foot LED screens, referred to as shrines, supplied by 4Wall Leisure and positionally tracked utilizing Mo-Sys StarTrackers. Their drawings have been then run by means of the AWS microservices for inference with the ensuing media re-projected again to the shrines as AI generated 2D photographs and 3D meshes within the present’s digital surroundings (in Unreal Engine on {hardware} by Boxx). OARC efficiently designed and applied an answer for 7 performances, in addition to the various playtests and rehearsals main as much as them. The performances ran between Might 15 and Might 23, 2025 with about 500 complete viewers members, as much as 65 at a time co-creating media throughout the efficiency.
On this put up, we’ll stroll by means of the efficiency constraints and design decisions by OARC and REMAP, together with how AWS serverless infrastructure, AWS Managed Companies, and generative AI companies supported the speedy design and deployment of our answer. We can even describe our use of Amazon SageMaker AI and the way it may be used reliably in immersive dwell experiences. We are going to define the fashions used and describe how they contributed to the viewers co-created media. We can even assessment the mechanisms we used to manage price over the length of each rehearsals and performances. Lastly, we’ll current classes discovered and enhancements we plan to make for section 2 of this undertaking.
OARC’s answer was designed to allow close to real-time (NRT) inferencing throughout a dwell efficiency and included the next high-level necessities:
- The microservices had a strict minimal concurrency requirement of 80 cell phone customers for every efficiency (accommodating 65 viewers members plus 12 performers)
- The imply round-trip time (MRTT) from cell phone sketches to media presentation needed to be below 2 minutes to be prepared because the efficiency was occurring and supply optimum viewers expertise
- The AWS GPU sources needed to be fault tolerant and extremely obtainable throughout rehearsals and performances, swish degradation was not an possibility
- A human-in-the-loop dashboard was required to supply handbook management over the infrastructure sources if human intervention was required
- The structure needed to be versatile sufficient to deal with show-to-show modifications as builders discovered new methods to unravel points
With the above constraints in thoughts, we designed the system with a serverless-first structure strategy for many of the workload. We deployed HuggingFace fashions on Amazon SageMaker AI and used obtainable fashions in Amazon Bedrock, making a complete inference pipeline that used the flexibleness and strengths of each companies. Amazon Bedrock supplied simplified and managed entry to basis fashions equivalent to Anthropic Claude, Amazon Nova, Secure Diffusion and Amazon SageMaker AI supplied full machine studying lifecycle management for open supply fashions from HuggingFace.
The next structure diagram exhibits a high-level view of interactions between the cell phone sketch creation and OARC’s AWS microservice.
The OARC microservice software design used a serverless-first strategy, offering the muse for an event-driven structure. Consumer sketches have been handed to the microservice utilizing a low-latency Firebase orchestration layer and the work was coordinated by means of a sequence of processing steps reworking person sketches into 2D photographs and 3D meshes. A number of on-premises MacOS workstations on the left of the diagram have been liable for initiating workflows, looking forward to job completions, human within the loop assessment, and for sending completed belongings again to the efficiency media servers.
Inbound viewers sketches and metadata messages have been despatched to Amazon SQS from the on-premises MacOS workstations, the place they have been sorted into sub queues by an AWS Lambda helper perform. Every queue was liable for beginning a pipeline primarily based on the kind of inference processing that the person sketch required (for instance, 2D-image, 3D-mesh). The sorting mechanism let the appliance exactly management its processing charge, so busy pipelines didn’t block new messages in different pipelines utilizing open sources.
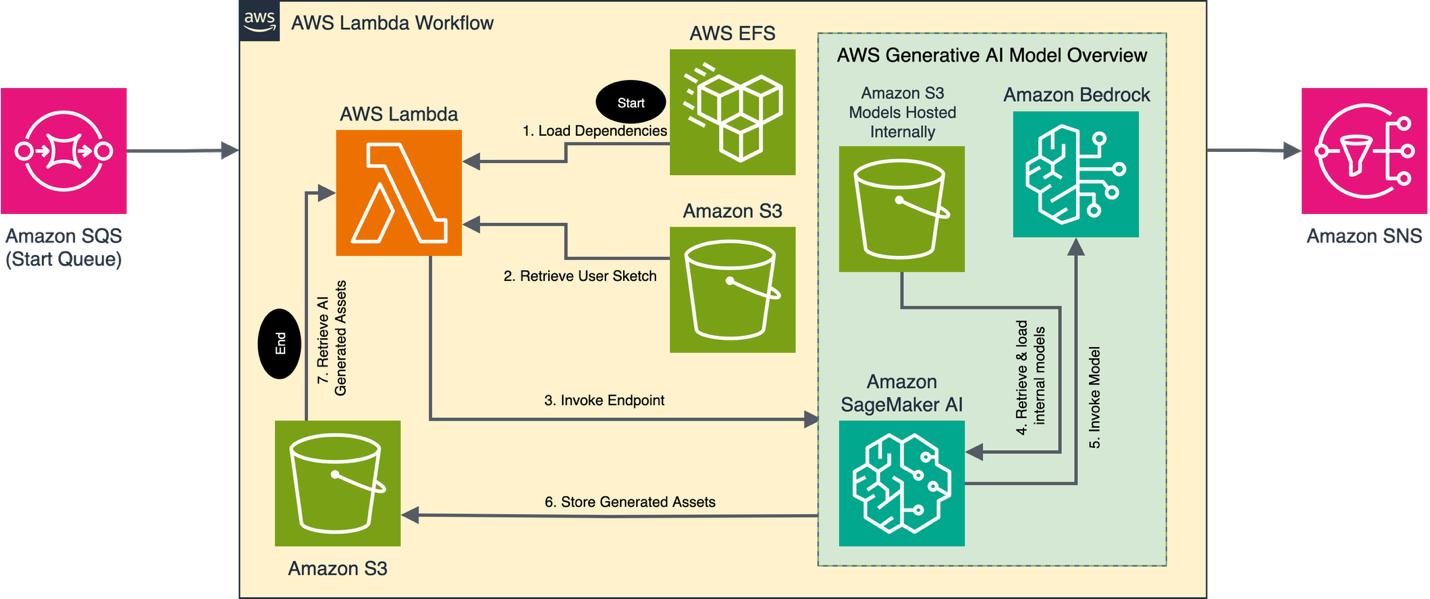
A second extra advanced Lambda perform listened for messages from the sorted sub queues and supplied the logic to organize person sketches for inferencing. This perform did the validation, error/success messaging, concurrency dealing with, and orchestration of the pre-processing inference and post-processing steps. This design took a modular strategy permitting builders to quickly combine new options whereas holding merge conflicts to a minimal. Since there was a human-in-the-loop, we didn’t carry out automated post-processing on the photographs. We might safely belief that points could be caught earlier than they have been despatched to the shrines. Sooner or later, we glance to validate belongings returned by fashions in SageMaker AI endpoints utilizing guardrails in Amazon Bedrock and different object detection strategies together with human-in-the-loop assessment.
Our processing steps required giant Python dependencies together with PyTorch. Rising as much as 5GB in dimension, these dependencies have been too giant to slot in Lambda layers. We used Amazon EFS to host the dependencies in a separate quantity mounted to the Lambda perform at run time. The scale of the dependencies elevated the time it took the service to begin, however after preliminary instantiation, future message processing was performant. The elevated latency throughout startup was a super use case to handle with the Lambda chilly begins and latency enchancment suggestions. Nevertheless, we didn’t implement it as a result of it required some changes to our improvement course of late within the undertaking.
Inference requests have been dealt with by 24 SageMaker AI Endpoints, with 8 endpoints liable for dealing with the three pipelines. We used the Amazon EC2 G6 occasion household to host the fashions, utilizing 8 g6.12xlarge and 16 g6.4xlarge cases. Every pipeline contained a custom-made workflow particular to the kind of request wanted for the manufacturing. Every SageMaker AI endpoint leveraged each internally loaded fashions and huge LLMs hosted on Amazon Bedrock to finish every request (the complete workflow is detailed within the following AI workflow part). Common processing occasions, measured from Amazon SageMaker AI job initiation to the return of generated belongings to AWS Lambda, ranged from 40-60 seconds on the g6.4xlarge cases, and 20-30 seconds on the g6.12xlarge cases.
After inferencing, the Lambda perform despatched the message to an Amazon SNS matter liable for sending success emails, publishing to Amazon SQS, and updating an Amazon DynamoDB desk for future analytics. The on-premises MacOS workstations polled the ultimate queue to retrieve new belongings as they completed.
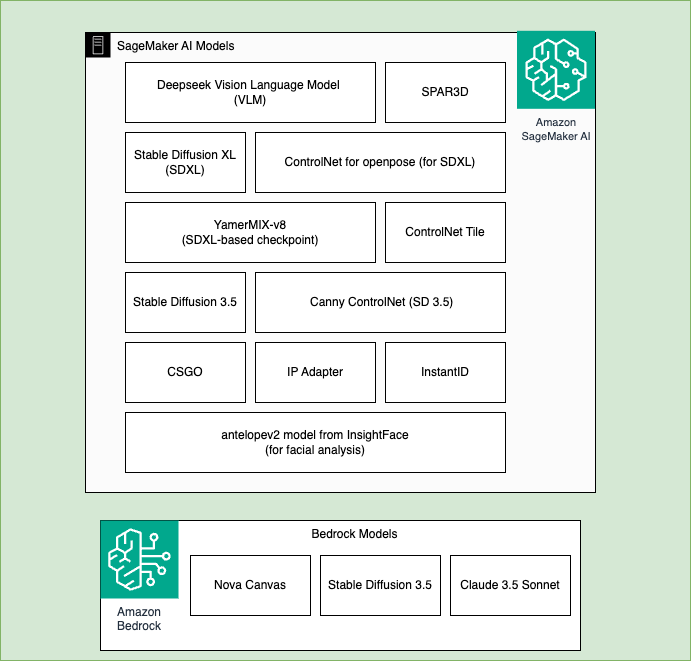
The next picture illustrates the fashions utilized by each Amazon SageMaker AI and Amazon Bedrock in our answer. Fashions for Amazon SageMaker AI embrace: DeepSeek VLM, SDXL, Secure Diffusion 3.5, SPAR3D, ControlNet for openpose, Yamix-8, ControlNet Tile, ControlNet for canny edges, CSGO, IP Adapter, InstantID, antelopev2 mannequin from InsightFace. Fashions utilized by Amazon Bedrock embrace: Nova Canvas, Secure Diffusion 3.5, and Claude 3.5 Sonnet.
The answer leveraged AWS for 3 distinct inference cycles, referred to as modules. Every module incorporates a tailor-made AI workflow, using a subset of small and huge AI fashions, to generate 2D photographs and 3D mesh objects for presentation. Each module begins with an viewers immediate, wherein individuals are requested to attract a sketch for a particular job, equivalent to making a background, rendering a 2D illustration of a 3D object, or inserting muses in customized poses and clothes. The AI workflow processes these photographs in keeping with the necessities of every module.
Every module started by producing textual representations of the person’s sketch and any accompanying predesigned reference photographs. To perform this, we used both a DeepSeek VLM loaded onto an Amazon SageMaker AI endpoint or Anthropic’s Claude 3.5 Sonnet mannequin by means of Amazon Bedrock. The predesigned photographs included numerous theatrical poses, designer clothes, and useful belongings supposed to information mannequin outputs. Subsequent, these descriptions, person sketches, and supplemental belongings have been supplied as inputs to a neighborhood diffusion mannequin paired with a ControlNet or related framework to generate the specified picture. In two of the modules, lower-resolution photographs have been generated to cut back inference time. These lower-quality photographs have been handed into both Nova Canvas in Amazon Bedrock or Secure Diffusion 3.5 to quickly generate higher-quality photographs, relying on the module. For instance, with Nova Canvas, we used the IMAGE_VARIATION job sort to generate a 2048 x 512-pixel picture from the low-resolution background sketches created by the DeepSeek VLM. This strategy offloaded a part of the inference workload, enabling us to run smaller Amazon SageMaker AI occasion sorts with out sacrificing high quality or velocity.
The workflow then proceeded with the ultimate processing routines particular to every output sort. For background photographs, a solid member was overlaid at a various location close to the underside fringe of the picture. The customized poses have been transformed into texture objects, and object sketches have been remodeled into 3D mesh objects through the image-to-3D mannequin. Lastly, Amazon SageMaker AI saved the picture belongings in an Amazon S3 bucket, the place the principle AWS Lambda perform might retrieve them.
The next picture is an instance of belongings used and produced by one of many modules. Consumer sketch is on the left, actor photograph is on prime, reference background picture is on the underside, and the AI generated picture on the precise.

Deployment of code to the Lambda perform was dealt with by AWS CodeBuild. The job was liable for listening for pull request merges on GitHub, updating the Python dependencies in EFS, and deploying the updates to the principle Lambda perform. This code deployment technique supported constant and dependable updates throughout our improvement, staging, and manufacturing environments and obviated the necessity for handbook code deployments and updates, decreasing the chance that entails.
SageMaker AI endpoints have been managed by a customized internet interface that allowed directors to deploy “known-good” endpoint configurations, permitting for fast deployments of infrastructure, speedy redeploys, and easy shutdowns. The dashboard additionally contained metrics on jobs operating in Amazon SQS and Amazon CloudWatch Logs in order that the crew might purge messages from the pipeline.
After working by means of the performances and with the advantage of hindsight, we’ve got some suggestions and issues that may be helpful for future iterations. We advocate utilizing AWS CloudFormation or related instrument to cut back handbook deployments and updates of companies used within the software. Many builders comply with a improvement, staging, manufacturing pipeline to make modifications and enhancements, so automating the configuration of companies will cut back errors created in comparison with a handbook deployment.
By utilizing a modular, serverless, event-driven strategy we created a dependable and straightforward to keep up cloud structure. By utilizing AWS Managed Companies builders and directors can concentrate on the system design somewhat than system upkeep. Total, we discovered that AWS Managed Companies carried out exceptionally nicely and supplied a way to develop advanced technological architectures to help real-time picture inferencing in a high-stakes setting.
The character of this undertaking created a singular use case. We wanted a approach to deal with a sudden inflow of inference requests coming in all at one time. This surge of requests solely lasted quarter-hour, so we would have liked to create an answer that was each dependable and ephemeral. We reviewed each Amazon EC2 and Amazon SageMaker AI as our foremost choices for deploying 20+ cases on demand. To resolve on the most effective system, we evaluated the next: On-demand request reliability, upkeep burden, complexity, deployment, and cargo balancing. Amazon EC2 is greater than able to dealing with these necessities, nonetheless acquiring the mandatory on-demand cases was difficult, and sustaining that many hosts created an extreme upkeep burden. Amazon SageMaker AI met all our standards, with easy configuration, easy and dependable deployment, and an built-in load balancing service. Finally, we opted to host most of our fashions on SageMaker AI with Amazon Bedrock offering managed serverless entry to fashions equivalent to Nova Canvas, Secure Diffusion 3.5, and Claude 3.5 Sonnet. Amazon EKS is another choice which will have met our necessities. It’s nice at fast deployments and seamlessly scalable, nonetheless, we felt that Amazon SageMaker AI was the precise selection for this undertaking as a result of it was quick to configure.
Whereas SageMaker AI proved dependable for real-time inference throughout dwell performances, it additionally represented the biggest share of our undertaking prices—roughly 40% of complete cloud spend. Throughout rehearsals and improvement, we noticed that idle or unused SageMaker AI endpoints could possibly be a significant supply of price escalation. To mitigate this, we applied a nightly automated shutdown course of utilizing Amazon EventBridge scheduler and AWS Lambda. This easy automation step stopped sources from being left operating unintentionally, serving to us keep price predictability with out sacrificing efficiency. We’re additionally taking a look at different price discount methods for section 2.
By making a aware design selection to make use of AWS generative AI companies and AWS Managed Companies for REMAP’s immersive manufacturing of the musical Xanadu, we have been in a position to exhibit that it’s doable to help new and dynamic types of leisure with AWS.
We confirmed that serverless event-driven structure was a quick and low-cost methodology for constructing out such companies, and we confirmed how each Amazon Bedrock and Amazon SageMaker AI can work collectively to make the most of all the array of obtainable generative AI fashions. We described our message pipeline and the message processing that went on inside it. We mentioned the generative AI fashions used and their perform and implementation. Lastly, we’ve got proven the potential for continued improvement of immersive musical theatre on this method.
Xanadu Guide by Douglas Carter Beane. Music & Lyrics by Jeff Lynne & John Farrar. Directed by Mira Winick & Corey Wright.
Concerning the authors
 Andrew Browning is the Analysis Knowledge and Net Platforms Supervisor for the Workplace of Superior Analysis Computing on the College of California Los Angeles (UCLA). He’s desirous about using AI within the fields of Superior Manufacturing, Medical and Dental Self- Care, and Immersive Efficiency. He’s additionally desirous about creating re-usable PaaS functions to handle widespread issues in these fields.
Andrew Browning is the Analysis Knowledge and Net Platforms Supervisor for the Workplace of Superior Analysis Computing on the College of California Los Angeles (UCLA). He’s desirous about using AI within the fields of Superior Manufacturing, Medical and Dental Self- Care, and Immersive Efficiency. He’s additionally desirous about creating re-usable PaaS functions to handle widespread issues in these fields.
 Anthony Doolan is Utility Programmer and AV Specialist at Analysis Knowledge and Net Platforms | Infrastructure Assist Companies at OARC, UCLA. Anthony Doolan is a Full Stack Net Developer and AV Specialist for UCLA’s Workplace of Superior Analysis Computing. He develops and maintains full stack internet functions, each on premises and cloud-based, and gives audiovisual techniques integration and programming experience.
Anthony Doolan is Utility Programmer and AV Specialist at Analysis Knowledge and Net Platforms | Infrastructure Assist Companies at OARC, UCLA. Anthony Doolan is a Full Stack Net Developer and AV Specialist for UCLA’s Workplace of Superior Analysis Computing. He develops and maintains full stack internet functions, each on premises and cloud-based, and gives audiovisual techniques integration and programming experience.
 Jerome Ronquillo is Net Developer & Cloud Architect at Analysis Knowledge and Net Platforms at OARC, UCLA. He makes a speciality of designing and implementing scalable, cloud-native options that mix innovation with real-world software.
Jerome Ronquillo is Net Developer & Cloud Architect at Analysis Knowledge and Net Platforms at OARC, UCLA. He makes a speciality of designing and implementing scalable, cloud-native options that mix innovation with real-world software.
 Lakshmi Dasari Lakshmi is a Sr. Options Architect supporting Public Sector Increased Schooling clients in Los Angeles. With in depth expertise in Enterprise IT structure, engineering and administration, she now helps AWS clients notice the worth of cloud with migration and modernization pathways. In her prior position as an AWS Associate Options Architect, she accelerated buyer’s AWS adoption with AWS SI and ISV companions. She is keen about inclusion in tech and is actively concerned in hiring and mentoring to advertise a various expertise pool on the office.
Lakshmi Dasari Lakshmi is a Sr. Options Architect supporting Public Sector Increased Schooling clients in Los Angeles. With in depth expertise in Enterprise IT structure, engineering and administration, she now helps AWS clients notice the worth of cloud with migration and modernization pathways. In her prior position as an AWS Associate Options Architect, she accelerated buyer’s AWS adoption with AWS SI and ISV companions. She is keen about inclusion in tech and is actively concerned in hiring and mentoring to advertise a various expertise pool on the office.
 Aditya Singh Aditya Singh is an AI/ML Specialist Options Architect at AWS who focuses on serving to increased training establishments and state/native authorities organizations speed up their AI adoption journey utilizing cutting-edge generative AI and machine studying techniques. He makes a speciality of Generative AI functions, pure language processing, and MLOps that handle distinctive challenges within the training and public sector.
Aditya Singh Aditya Singh is an AI/ML Specialist Options Architect at AWS who focuses on serving to increased training establishments and state/native authorities organizations speed up their AI adoption journey utilizing cutting-edge generative AI and machine studying techniques. He makes a speciality of Generative AI functions, pure language processing, and MLOps that handle distinctive challenges within the training and public sector.
 Jeff Burke is Professor and Chair of the Division of Theater and Affiliate Dean, Analysis and Artistic Know-how within the UCLA Faculty of Theater, Movie and Tv, the place he co-directs the Heart for Analysis in Engineering, Media, and Efficiency (REMAP). Burke’s analysis and artistic work explores the intersections of rising know-how and artistic expression. He’s presently the principal investigator of the Innovation, Tradition, and Creativity undertaking funded by the Nationwide Science Basis to discover alternatives nationwide for innovation on the intersection of the inventive and know-how sectors. He developed and produced Xanadu in collaboration with college students from throughout campus.
Jeff Burke is Professor and Chair of the Division of Theater and Affiliate Dean, Analysis and Artistic Know-how within the UCLA Faculty of Theater, Movie and Tv, the place he co-directs the Heart for Analysis in Engineering, Media, and Efficiency (REMAP). Burke’s analysis and artistic work explores the intersections of rising know-how and artistic expression. He’s presently the principal investigator of the Innovation, Tradition, and Creativity undertaking funded by the Nationwide Science Basis to discover alternatives nationwide for innovation on the intersection of the inventive and know-how sectors. He developed and produced Xanadu in collaboration with college students from throughout campus.
 Chiheb Boussema is an Utilized AI Scientist at REMAP, UCLA the place he develops AI options for inventive functions. His pursuits presently embrace scalability and edge deployment of diffusion fashions, movement management and synthesis for animation, and reminiscence and human-AI interplay modeling and management.
Chiheb Boussema is an Utilized AI Scientist at REMAP, UCLA the place he develops AI options for inventive functions. His pursuits presently embrace scalability and edge deployment of diffusion fashions, movement management and synthesis for animation, and reminiscence and human-AI interplay modeling and management.
 Naisha Agarwal is a rising senior at UCLA majoring in pc science. She was the generative AI co-lead for Xanadu the place she labored on designing the Generative AI workflows that powered numerous viewers interactions within the present, combining her ardour for know-how and the humanities. She interned at Microsoft Analysis, engaged on designing user- authored immersive experiences, augmenting bodily areas with digital worlds. She has additionally interned at Kumo the place she developed a customized AI chatbot which was later deployed on Snowflake. Moreover, she has printed a paper on recommender techniques on the KDD convention. She is keen about utilizing pc science to unravel actual world issues.
Naisha Agarwal is a rising senior at UCLA majoring in pc science. She was the generative AI co-lead for Xanadu the place she labored on designing the Generative AI workflows that powered numerous viewers interactions within the present, combining her ardour for know-how and the humanities. She interned at Microsoft Analysis, engaged on designing user- authored immersive experiences, augmenting bodily areas with digital worlds. She has additionally interned at Kumo the place she developed a customized AI chatbot which was later deployed on Snowflake. Moreover, she has printed a paper on recommender techniques on the KDD convention. She is keen about utilizing pc science to unravel actual world issues.