
Though cautious immediate crafting can yield good outcomes, attaining professional-grade visible consistency typically requires adapting the underlying mannequin itself. Constructing on the immediate engineering and character growth strategy coated in Half 1 of this two-part sequence, we now push the consistency degree for particular characters by fine-tuning an Amazon Nova Canvas basis mannequin (FM). By means of fine-tuning strategies, creators can instruct the mannequin to take care of exact management over character appearances, expressions, and stylistic components throughout a number of scenes.
On this put up, we take an animated quick movie, Picchu, produced by FuzzyPixel from Amazon Internet Providers (AWS), put together coaching information by extracting key character frames, and fine-tune a character-consistent mannequin for the principle character Mayu and her mom, so we are able to rapidly generate storyboard ideas for brand new sequels like the next pictures.
Resolution overview
To implement an automatic workflow, we suggest the next complete resolution structure that makes use of AWS providers for an end-to-end implementation.
The workflow consists of the next steps:
- The consumer uploads a video asset to an Amazon Easy Storage Service (Amazon S3) bucket.
- Amazon Elastic Container Service (Amazon ECS) is triggered to course of the video asset.
- Amazon ECS downsamples the frames, selects these containing the character, after which center-crops them to supply the ultimate character pictures.
- Amazon ECS invokes an Amazon Nova mannequin (Amazon Nova Professional) from Amazon Bedrock to create captions from the photographs.
- Amazon ECS writes the picture captions and metadata to the S3 bucket.
- The consumer makes use of a pocket book surroundings in Amazon SageMaker AI to invoke the mannequin coaching job.
- The consumer fine-tunes a {custom} Amazon Nova Canvas mannequin by invoking Amazon Bedrock
create_model_customization_jobandcreate_model_provisioned_throughputAPI calls to create a {custom} mannequin out there for inference.
This workflow is structured in two distinct phases. The preliminary section, in Steps 1–5, focuses on making ready the coaching information. On this put up, we stroll by way of an automatic pipeline to extract pictures from an enter video after which generate labeled coaching information. The second section, in Steps 6–7, focuses on fine-tuning the Amazon Nova Canvas mannequin and performing check inference utilizing the custom-trained mannequin. For these latter steps, we offer the preprocessed picture information and complete instance code within the following GitHub repository to information you thru the method.
Put together the coaching information
Let’s start with the primary section of our workflow. In our instance, we construct an automatic video object/character extraction pipeline to extract high-resolution pictures with correct caption labels utilizing the next steps.
Inventive character extraction
We suggest first sampling video frames at fastened intervals (for instance, 1 body per second). Then, apply Amazon Rekognition label detection and face assortment search to determine frames and characters of curiosity. Label detection can determine over 2,000 distinctive labels and find their positions inside frames, making it excellent for preliminary detection of common character classes or non-human characters. To tell apart between completely different characters, we then use the Amazon Rekognition characteristic to search faces in a set. This characteristic identifies and tracks characters by matching their faces towards a pre-populated face assortment. If these two approaches aren’t exact sufficient, we are able to use Amazon Rekognition Customized Labels to coach a {custom} mannequin for detecting particular characters. The next diagram illustrates this workflow.
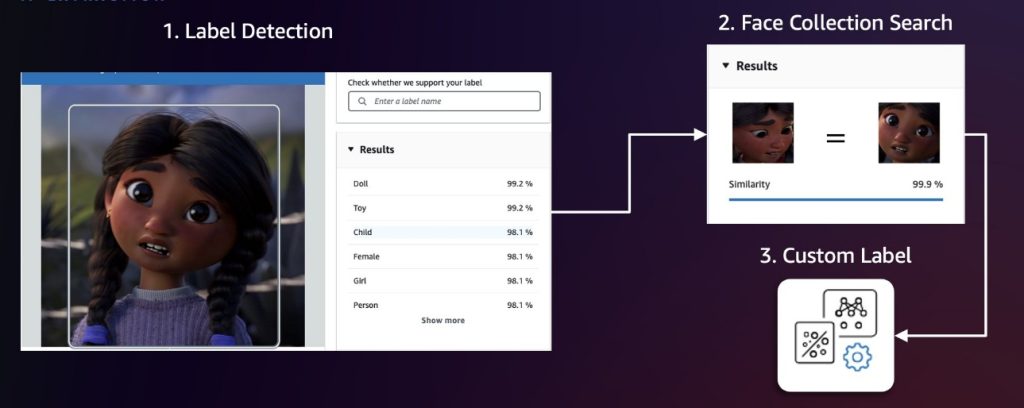
After detection, we center-crop every character with acceptable pixel padding after which run a deduplication algorithm utilizing the Amazon Titan Multimodal Embeddings mannequin to take away semantically comparable pictures above a threshold worth. Doing so helps us construct a various dataset as a result of redundant or practically similar frames may result in mannequin overfitting (when a mannequin learns the coaching information too exactly, together with its noise and fluctuations, making it carry out poorly on new, unseen information). We will calibrate the similarity threshold to fine-tune what we take into account to be similar pictures, so we are able to higher management the steadiness between dataset range and redundancy elimination.
Knowledge labeling
We generate captions for every picture utilizing Amazon Nova Professional in Amazon Bedrock after which add the picture and label manifest file to an Amazon S3 location. This course of focuses on two essential elements of immediate engineering: character description to assist the FM determine and identify the characters primarily based on their distinctive attributes, and diverse description technology that avoids repetitive patterns within the caption (for instance, “an animated character”). The next is an instance immediate template used throughout our information labeling course of:
The information labeling output is formatted as a JSONL file, the place every line pairs a picture reference Amazon S3 path with a caption generated by Amazon Nova Professional. This JSONL file is then uploaded to Amazon S3 for coaching. The next is an instance of the file:
Human verification
For enterprise use instances, we suggest incorporating a human-in-the-loop course of to confirm labeled information earlier than continuing with mannequin coaching. This verification could be carried out utilizing Amazon Augmented AI (Amazon A2I), a service that helps annotators confirm each picture and caption high quality. For extra particulars, confer with Get Began with Amazon Augmented AI.
Positive-tune Amazon Nova Canvas
Now that now we have the coaching information, we are able to fine-tune the Amazon Nova Canvas mannequin in Amazon Bedrock. Amazon Bedrock requires an AWS Identification and Entry Administration (IAM) service position to entry the S3 bucket the place you saved your mannequin customization coaching information. For extra particulars, see Mannequin customization entry and safety. You may carry out the fine-tuning job immediately on the Amazon Bedrock console or use the Boto3 API. We clarify each approaches on this put up, and you could find the end-to-end code pattern in picchu-finetuning.ipynb.
Create a fine-tuning job on the Amazon Bedrock console
Let’s begin by creating an Amazon Nova Canvas fine-tuning job on the Amazon Bedrock console:
- On the Amazon Bedrock console, within the navigation pane, select Customized fashions underneath Basis fashions.
- Select Customise mannequin after which Create Positive-tuning job.
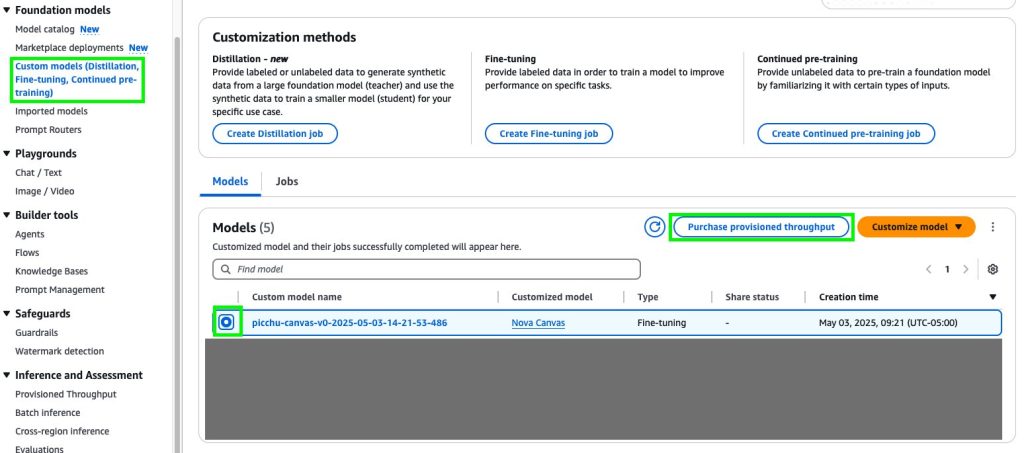
- On the Create Positive-tuning job particulars web page, select the mannequin you wish to customise and enter a reputation for the fine-tuned mannequin.
- Within the Job configuration part, enter a reputation for the job and optionally add tags to affiliate with it.
- Within the Enter information part, enter the Amazon S3 location of the coaching dataset file.
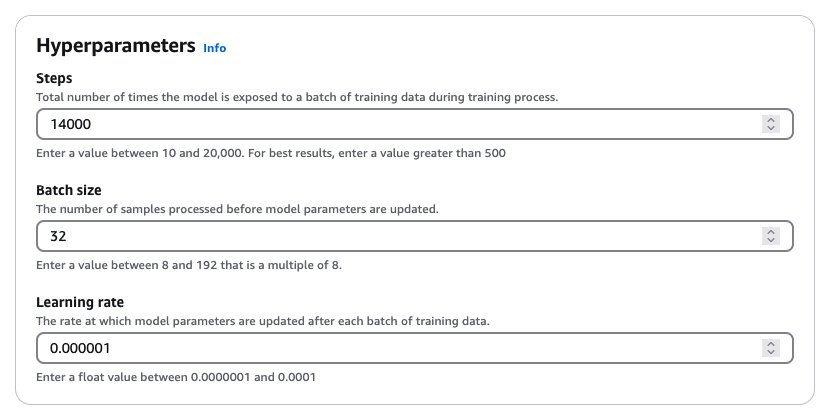
- Within the Hyperparameters part, enter values for hyperparameters, as proven within the following screenshot.
- Within the Output information part, enter the Amazon S3 location the place Amazon Bedrock ought to save the output of the job.
- Select Positive-tune mannequin job to start the fine-tuning course of.
This hyperparameter mixture yielded good outcomes throughout our experimentation. Normally, growing the educational fee makes the mannequin prepare extra aggressively, which regularly presents an fascinating trade-off: we would obtain character consistency extra rapidly, however it would possibly impression general picture high quality. We suggest a scientific strategy to adjusting hyperparameters. Begin with the recommended batch dimension and studying fee, and take a look at growing or lowering the variety of coaching steps first. If the mannequin struggles to study your dataset even after 20,000 steps (the utmost allowed in Amazon Bedrock), then we recommend both growing the batch dimension or adjusting the educational fee upward. These changes, by way of delicate, could make a big distinction in our mannequin’s efficiency. For extra particulars concerning the hyperparameters, confer with Hyperparameters for Inventive Content material Era fashions.
Create a fine-tuning job utilizing the Python SDK
The next Python code snippet creates the identical fine-tuning job utilizing the create_model_customization_job API:
When the job is full, you’ll be able to retrieve the brand new customModelARN utilizing the next code:
Deploy the fine-tuned mannequin
With the previous hyperparameter configuration, this fine-tuning job would possibly take as much as 12 hours to finish. When it’s full, it’s best to see a brand new mannequin within the {custom} fashions listing. You may then create provisioned throughput to host the mannequin. For extra particulars on provisioned throughput and completely different dedication plans, see Improve mannequin invocation capability with Provisioned Throughput in Amazon Bedrock.
Deploy the mannequin on the Amazon Bedrock console
To deploy the mannequin from the Amazon Bedrock console, full the next steps:
- On the Amazon Bedrock console, select Customized fashions underneath Basis fashions within the navigation pane.
- Choose the brand new {custom} mannequin and select Buy provisioned throughput.
- Within the Provisioned Throughput particulars part, enter a reputation for the provisioned throughput.
- Underneath Choose mannequin, select the {custom} mannequin you simply created.
- Then specify the dedication time period and mannequin models.
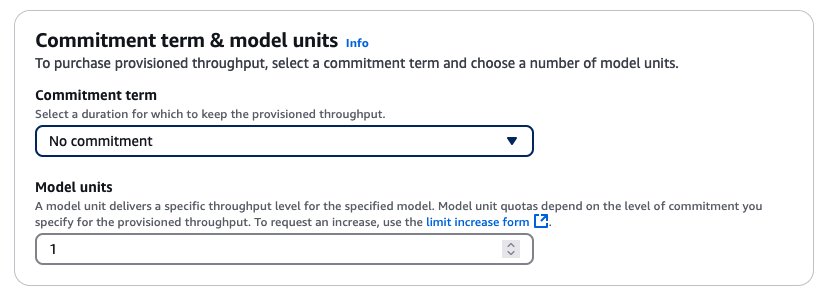
After you buy provisioned throughput, a brand new mannequin Amazon Useful resource Title (ARN) is created. You may invoke this ARN when the provisioned throughput is in service.
Deploy the mannequin utilizing the Python SDK
The next Python code snippet creates provisioned throughput utilizing the create_provisioned_model_throughput API:
Check the fine-tuned mannequin
When the provisioned throughput is dwell, we are able to use the next code snippet to check the {custom} mannequin and experiment with producing some new pictures for a sequel to Picchu:
 |
 |
 |
| Mayu face exhibits a mixture of nervousness and dedication. Mommy kneels beside her, gently holder her. A panorama is seen within the background. | A steep cliff face with an extended picket ladder extending downwards. Midway down the ladder is Mayu with a decided expression on her face. Mayu’s small palms grip the edges of the ladder tightly as she fastidiously locations her ft on every rung. The encircling surroundings exhibits a rugged, mountainous panorama. | Mayu standing proudly on the entrance of a easy faculty constructing. Her face beams with a large smile, expressing delight and accomplishment. |
Clear up
To keep away from incurring AWS costs after you’re carried out testing, full the cleanup steps in picchu-finetuning.ipynb and delete the next sources:
- Amazon SageMaker Studio area
- Positive-tuned Amazon Nova mannequin and provision throughput endpoint
Conclusion
On this put up, we demonstrated how you can elevate character and magnificence consistency in storyboarding from Half 1 by fine-tuning Amazon Nova Canvas in Amazon Bedrock. Our complete workflow combines automated video processing, clever character extraction utilizing Amazon Rekognition, and exact mannequin customization utilizing Amazon Bedrock to create an answer that maintains visible constancy and dramatically accelerates the storyboarding course of. By fine-tuning the Amazon Nova Canvas mannequin on particular characters and kinds, we’ve achieved a degree of consistency that surpasses commonplace immediate engineering, so artistic groups can produce high-quality storyboards in hours moderately than weeks. Begin experimenting with Nova Canvas fine-tuning at this time, so you can even elevate your storytelling with higher character and magnificence consistency.
Concerning the authors
 Dr. Achin Jain is a Senior Utilized Scientist at Amazon AGI, the place he works on constructing multi-modal basis fashions. He brings over 10+ years of mixed business and educational analysis expertise. He has led the event of a number of modules for Amazon Nova Canvas and Amazon Titan Picture Generator, together with supervised fine-tuning (SFT), mannequin customization, instantaneous customization, and steerage with colour palette.
Dr. Achin Jain is a Senior Utilized Scientist at Amazon AGI, the place he works on constructing multi-modal basis fashions. He brings over 10+ years of mixed business and educational analysis expertise. He has led the event of a number of modules for Amazon Nova Canvas and Amazon Titan Picture Generator, together with supervised fine-tuning (SFT), mannequin customization, instantaneous customization, and steerage with colour palette.
 James Wu is a Senior AI/ML Specialist Resolution Architect at AWS. serving to prospects design and construct AI/ML options. James’s work covers a variety of ML use instances, with a major curiosity in pc imaginative and prescient, deep studying, and scaling ML throughout the enterprise. Previous to becoming a member of AWS, James was an architect, developer, and expertise chief for over 10 years, together with 6 years in engineering and 4 years in advertising and marketing & promoting industries.
James Wu is a Senior AI/ML Specialist Resolution Architect at AWS. serving to prospects design and construct AI/ML options. James’s work covers a variety of ML use instances, with a major curiosity in pc imaginative and prescient, deep studying, and scaling ML throughout the enterprise. Previous to becoming a member of AWS, James was an architect, developer, and expertise chief for over 10 years, together with 6 years in engineering and 4 years in advertising and marketing & promoting industries.
 Randy Ridgley is a Principal Options Architect targeted on real-time analytics and AI. With experience in designing information lakes and pipelines. Randy helps organizations remodel various information streams into actionable insights. He makes a speciality of IoT options, analytics, and infrastructure-as-code implementations. As an open-source contributor and technical chief, Randy offers deep technical information to ship scalable information options throughout enterprise environments.
Randy Ridgley is a Principal Options Architect targeted on real-time analytics and AI. With experience in designing information lakes and pipelines. Randy helps organizations remodel various information streams into actionable insights. He makes a speciality of IoT options, analytics, and infrastructure-as-code implementations. As an open-source contributor and technical chief, Randy offers deep technical information to ship scalable information options throughout enterprise environments.