
Top-of-the-line-performing algorithms in machine studying is the boosting algorithm. These are characterised by good predictive skills and accuracy. All of the strategies of gradient boosting are primarily based on a common notion. They get to study by means of the errors of the previous fashions. Every new mannequin is aimed toward correcting the earlier errors. This fashion, a weak group of learners is become a strong workforce on this course of.
This text compares 5 common strategies of boosting. These are Gradient Boosting, AdaBoost, XGBoost, CatBoost, and LightGBM. It describes the best way each approach capabilities and exhibits main variations, together with their strengths and weaknesses. It additionally addresses the utilization of each strategies. There are efficiency benchmarks and code samples.
Introduction to Boosting
Boosting is a technique of ensemble studying. It fuses a number of weak learners with frequent shallow choice bushes into a robust mannequin. The fashions are skilled sequentially. Each new mannequin dwells upon the errors dedicated by the previous one. You possibly can study all about boosting algorithms in machine studying right here.
It begins with a primary mannequin. In regression, it may be used to forecast the common. Residuals are subsequently obtained by figuring out the distinction between the precise and predicted values. These residuals are predicted by coaching a brand new weak learner. This assists within the rectification of previous errors. The process is repeated till minimal errors are attained or a cease situation is achieved.
This concept is utilized in numerous boosting strategies otherwise. Some reweight information factors. Others minimise a loss perform by gradient descent. Such variations affect efficiency and suppleness. The final word prediction is, in any case, a weighted common of all weak learners.
AdaBoost (Adaptive Boosting)
One of many first boosting algorithms is AdaBoost. It was developed within the mid-Nineties. It builds fashions step-by-step. Each successive mannequin is devoted to the errors made within the earlier theoretical fashions. The purpose is that there’s adaptive reweighting of knowledge factors.
How It Works (The Core Logic)
AdaBoost works in a sequence. It doesn’t practice fashions abruptly; it builds them one after the other.
- Begin Equal: Give each information level the identical weight.
- Prepare a Weak Learner: Use a easy mannequin (normally a Resolution Stump—a tree with just one cut up).
- Discover Errors: See which information factors the mannequin bought incorrect.
- Reweight:
Enhance weights for the “incorrect” factors. They grow to be extra essential.
Lower weights for the “right” factors. They grow to be much less essential. - Calculate Significance (alpha): Assign a rating to the learner. Extra correct learners get a louder “voice” within the ultimate choice.
- Repeat: The subsequent learner focuses closely on the factors beforehand missed.
- Remaining Vote: Mix all learners. Their weighted votes decide the ultimate prediction.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Easy: Simple to arrange and perceive. | Delicate to Noise: Outliers get large weights, which may destroy the mannequin. |
| No Overfitting: Resilient on clear, easy information. | Sequential: It’s gradual and can’t be skilled in parallel. |
| Versatile: Works for each classification and regression. | Outdated: Fashionable instruments like XGBoost usually outperform it on complicated information. |
Gradient Boosting (GBM): The “Error Corrector”
Gradient Boosting is a strong ensemble technique. It builds fashions one after one other. Every new mannequin tries to repair the errors of the earlier one. As an alternative of reweighting factors like AdaBoost, it focuses on residuals (the leftover errors).
How It Works (The Core Logic)
GBM makes use of a method known as gradient descent to reduce a loss perform.
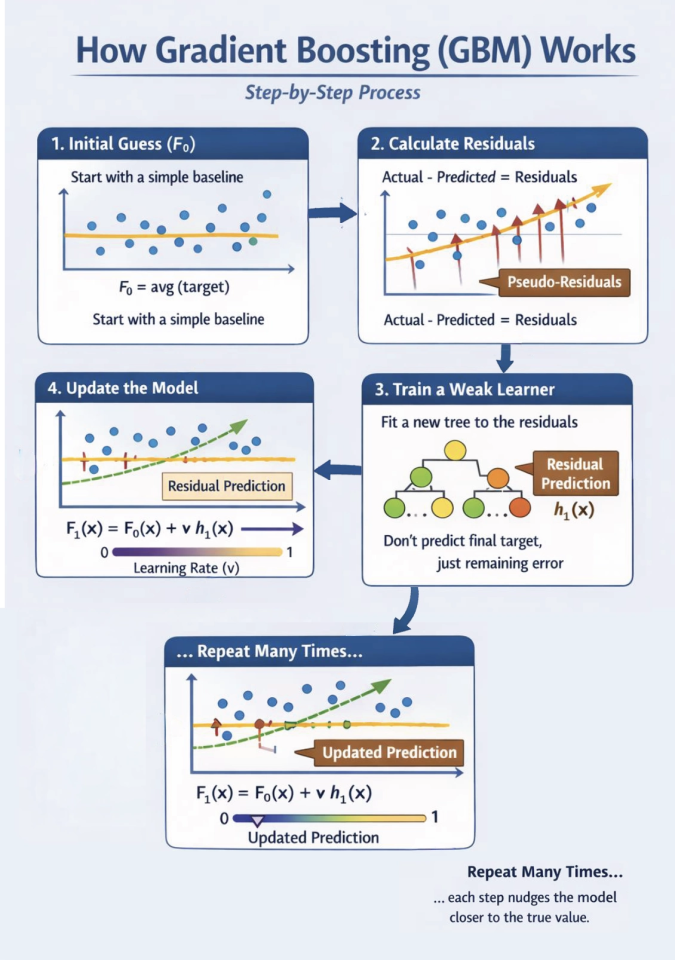
- Preliminary Guess (F0): Begin with a easy baseline. Often, that is simply the common of the goal values.
- Calculate Residuals: Discover the distinction between the precise worth and the present prediction. These “pseudo-residuals” characterize the gradient of the loss perform.
- Prepare a Weak Learner: Match a brand new choice tree (hm) particularly to foretell these residuals. It isn’t attempting to foretell the ultimate goal, simply the remaining error.
- Replace the Mannequin: Add the brand new tree’s prediction to the earlier ensemble. We use a studying fee (v) to forestall overfitting.
- Repeat: Do that many occasions. Every step nudges the mannequin nearer to the true worth.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Extremely Versatile: Works with any differentiable loss perform (MSE, Log-Loss, and so on.). | Sluggish Coaching: Timber are constructed one after the other. It’s exhausting to run in parallel. |
| Superior Accuracy: Usually beats different fashions on structured/tabular information. | Knowledge Prep Required: You should convert categorical information to numbers first. |
| Function Significance: It’s straightforward to see which variables are driving predictions. | Tuning Delicate: Requires cautious tuning of studying fee and tree depend. |
XGBoost: The “Excessive” Evolution
XGBoost stands for eXtreme Gradient Boosting. It’s a sooner, extra correct, and extra sturdy model of Gradient Boosting (GBM). It grew to become well-known by profitable many Kaggle competitions. You possibly can study all about it right here.
Key Enhancements (Why it’s “Excessive”)
In contrast to normal GBM, XGBoost consists of good math and engineering methods to enhance efficiency.
- Regularization: It makes use of $L1$ and $L2$ regularization. This penalizes complicated bushes and prevents the mannequin from “overfitting” or memorizing the information.
- Second-Order Optimization: It makes use of each first-order gradients and second-order gradients (Hessians). This helps the mannequin discover the perfect cut up factors a lot sooner.
- Sensible Tree Pruning: It grows bushes to their most depth first. Then, it prunes branches that don’t enhance the rating. This “look-ahead” method prevents ineffective splits.
- Parallel Processing: Whereas bushes are constructed one after one other, XGBoost builds the person bushes by taking a look at options in parallel. This makes it extremely quick.
- Lacking Worth Dealing with: You don’t have to fill in lacking information. XGBoost learns the easiest way to deal with “NaNs” by testing them in each instructions of a cut up.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| High Efficiency: Usually essentially the most correct mannequin for tabular information. | No Native Categorical Help: You should manually encode labels or one-hot vectors. |
| Blazing Quick: Optimized in C++ with GPU and CPU parallelization. | Reminiscence Hungry: Can use loads of RAM when coping with large datasets. |
| Strong: Constructed-in instruments deal with lacking information and forestall overfitting. | Advanced Tuning: It has many hyperparameters (like eta, gamma, and lambda). |
LightGBM: The “Excessive-Velocity” Various
LightGBM is a gradient boosting framework launched by Microsoft. It’s designed for excessive velocity and low reminiscence utilization. It’s the go-to alternative for enormous datasets with hundreds of thousands of rows.
Key Improvements (How It Saves Time)
LightGBM is “mild” as a result of it makes use of intelligent math to keep away from taking a look at each piece of knowledge.
- Histogram-Primarily based Splitting: Conventional fashions kind each single worth to discover a cut up. LightGBM teams values into “bins” (like a bar chart). It solely checks the bin boundaries. That is a lot sooner and makes use of much less RAM.
- Leaf-wise Progress: Most fashions (like XGBoost) develop bushes level-wise (filling out a complete horizontal row earlier than transferring deeper). LightGBM grows leaf-wise. It finds the one leaf that reduces error essentially the most and splits it instantly. This creates deeper, extra environment friendly bushes.
- GOSS (Gradient-Primarily based One-Facet Sampling): It assumes information factors with small errors are already “discovered.” It retains all information with massive errors however solely takes a random pattern of the “straightforward” information. This focuses the coaching on the toughest elements of the dataset.
- EFB (Unique Function Bundling): In sparse information (a lot of zeros), many options by no means happen on the identical time. LightGBM bundles these options collectively into one. This reduces the variety of options the mannequin has to course of.
- Native Categorical Help: You don’t have to one-hot encode. You possibly can inform LightGBM which columns are classes, and it’ll discover the easiest way to group them.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Quickest Coaching: Usually 10x–15x sooner than unique GBM on massive information. | Overfitting Threat: Leaf-wise progress can overfit small datasets in a short time. |
| Low Reminiscence: Histogram binning compresses information, saving large quantities of RAM. | Delicate to Hyperparameters: You should rigorously tune num_leaves and max_depth. |
| Extremely Scalable: Constructed for giant information and distributed/GPU computing. | Advanced Timber: Ensuing bushes are sometimes lopsided and more durable to visualise. |
CatBoost: The “Categorical” Specialist
CatBoost, developed by Yandex, is brief for Categorical Boosting. It’s designed to deal with datasets with many classes (like metropolis names or person IDs) natively and precisely without having heavy information preparation.
Key Improvements (Why It’s Distinctive)
CatBoost modifications each the construction of the bushes and the best way it handles information to forestall errors.
- Symmetric (Oblivious) Timber: In contrast to different fashions, CatBoost builds balanced bushes. Each node on the identical depth makes use of the very same cut up situation.
Profit: This construction is a type of regularization that stops overfitting. It additionally makes “inference” (making predictions) extraordinarily quick. - Ordered Boosting: Most fashions use your complete dataset to calculate class statistics, which ends up in “goal leakage” (the mannequin “dishonest” by seeing the reply early). CatBoost makes use of random permutations. A knowledge level is encoded utilizing solely the knowledge from factors that got here earlier than it in a random order.
- Native Categorical Dealing with: You don’t have to manually convert textual content classes to numbers.
– Low-count classes: It makes use of one-hot encoding.
– Excessive-count classes: It makes use of superior goal statistics whereas avoiding the “leaking” talked about above. - Minimal Tuning: CatBoost is legendary for having wonderful “out-of-the-box” settings. You usually get nice outcomes with out touching the hyperparameters.
Strengths & Weaknesses
| Strengths | Weaknesses |
|---|---|
| Greatest for Classes: Handles high-cardinality options higher than every other mannequin. | Slower Coaching: Superior processing and symmetric constraints make it slower to coach than LightGBM. |
| Strong: Very exhausting to overfit because of symmetric bushes and ordered boosting. | Reminiscence Utilization: It requires loads of RAM to retailer categorical statistics and information permutations. |
| Lightning Quick Inference: Predictions are 30–60x sooner than different boosting fashions. | Smaller Ecosystem: Fewer group tutorials in comparison with XGBoost. |
The Boosting Evolution: A Facet-by-Facet Comparability
Selecting the best boosting algorithm relies on your information dimension, function sorts, and {hardware}. Under is a simplified breakdown of how they examine.
Key Comparability Desk
| Function | AdaBoost | GBM | XGBoost | LightGBM | CatBoost |
|---|---|---|---|---|---|
| Primary Technique | Reweights information | Suits to residuals | Regularized residuals | Histograms & GOSS | Ordered boosting |
| Tree Progress | Degree-wise | Degree-wise | Degree-wise | Leaf-wise | Symmetric |
| Velocity | Low | Average | Excessive | Very Excessive | Average (Excessive on GPU) |
| Cat. Options | Guide Prep | Guide Prep | Guide Prep | Constructed-in (Restricted) | Native (Glorious) |
| Overfitting | Resilient | Delicate | Regularized | Excessive Threat (Small Knowledge) | Very Low Threat |
Evolutionary Highlights
- AdaBoost (1995): The pioneer. It centered on hard-to-classify factors. It’s easy however gradual on huge information and lacks fashionable math like gradients.
- GBM (1999): The inspiration. It makes use of calculus (gradients) to reduce loss. It’s versatile however will be gradual as a result of it calculates each cut up precisely.
- XGBoost (2014): The sport changer. It added Regularization ($L1/L2$) to cease overfitting. It additionally launched parallel processing to make coaching a lot sooner.
- LightGBM (2017): The velocity king. It teams information into Histograms so it doesn’t have to take a look at each worth. It grows bushes Leaf-wise, discovering essentially the most error-reducing splits first.
- CatBoost (2017): The class grasp. It makes use of Symmetric Timber (each cut up on the identical stage is similar). This makes it extraordinarily steady and quick at making predictions.
When to Use Which Methodology
The next desk clearly marks when to make use of which technique.
| Mannequin | Greatest Use Case | Decide It If | Keep away from It If |
|---|---|---|---|
| AdaBoost | Easy issues or small, clear datasets | You want a quick baseline or excessive interpretability utilizing easy choice stumps | Your information is noisy or accommodates robust outliers |
| Gradient Boosting (GBM) | Studying or medium-scale scikit-learn tasks | You need customized loss capabilities with out exterior libraries | You want excessive efficiency or scalability on massive datasets |
| XGBoost | Common-purpose, production-grade modeling | Your information is usually numeric and also you desire a dependable, well-supported mannequin | Coaching time is essential on very massive datasets |
| LightGBM | Giant-scale, speed- and memory-sensitive duties | You might be working with hundreds of thousands of rows and want fast experimentation | Your dataset is small and susceptible to overfitting |
| CatBoost | Datasets dominated by categorical options | You might have high-cardinality classes and need minimal preprocessing | You want most CPU coaching velocity |
Professional Tip: Many competition-winning options don’t select only one. They use an Ensemble averaging the predictions of XGBoost, LightGBM, and CatBoost to get the perfect of all worlds.
Conclusion
Boosting algorithms rework weak learners into robust predictive fashions by studying from previous errors. AdaBoost launched this concept and stays helpful for easy, clear datasets, nevertheless it struggles with noise and scale. Gradient Boosting formalized boosting by means of loss minimization and serves because the conceptual basis for contemporary strategies. XGBoost improved this method with regularization, parallel processing, and robust robustness, making it a dependable all-round alternative.
LightGBM optimized velocity and reminiscence effectivity, excelling on very massive datasets. CatBoost solved categorical function dealing with with minimal preprocessing and robust resistance to overfitting. No single technique is greatest for all issues. The optimum alternative relies on information dimension, function sorts, and {hardware}. In lots of real-world and competitors settings, combining a number of boosting fashions usually delivers the perfect efficiency.
Hello, I’m Janvi, a passionate information science fanatic at the moment working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we are able to extract significant insights from complicated datasets.
Login to proceed studying and luxuriate in expert-curated content material.