
Think about you might have an x-ray report and you have to perceive what accidents you might have. One choice is you possibly can go to a physician which ideally it’s best to however for some motive, in the event you can’t, you should use Multimodal Massive Language Fashions (MLLMs) which can course of your x-ray scan and inform you exactly what accidents you might have in response to the scans.
In easy phrases, MLLMs are nothing however a fusion of a number of fashions like textual content, picture, voice, movies, and many others. that are able to not solely processing a standard textual content question however can course of questions in a number of varieties comparable to photographs and sound.
So on this article, we are going to stroll you thru what MLLMs are, how they work and what are the highest MMLMs you should use.
What are Multimodal LLMs?
In contrast to conventional LLMs which might solely work with one sort of knowledge—principally textual content or picture, these multimodal LLMs can work with a number of types of information just like how people can course of imaginative and prescient, voice, and textual content abruptly.
At its core, multimodal AI takes in numerous types of information, comparable to textual content, photographs, audio, video, and even sensor information, to supply a richer and extra refined understanding and interplay. Contemplate an AI system that not solely views a picture however can describe it, perceive the context, reply questions on it, and even generate associated content material based mostly on a number of enter varieties.
Now, let’s take the identical instance of an x-ray report with the context of how a multimodal LLM will perceive the context of it. Right here’s a easy animation explaining the way it first processes the picture through the picture encoder to transform the picture into vectors and in a while it makes use of LLM which is educated over medical information to reply the question.
Supply: Google multimodal medical AI
How do Multimodal LLMs work?
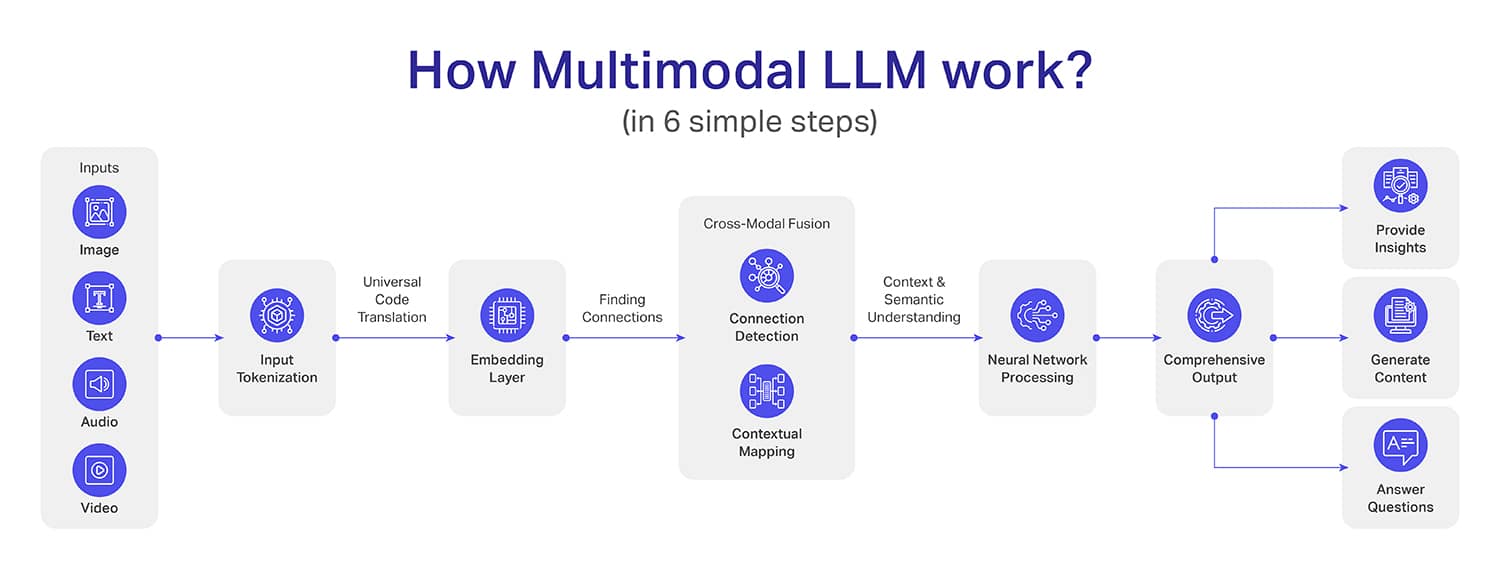
Whereas the interior workings of multimodal LLMs are fairly complicated (greater than LLMs), we’ve tried breaking them down into six easy steps:
Step 1: Enter Assortment – This is step one the place the information is collected and undergoes the preliminary processing. For instance, photographs are transformed into pixels sometimes utilizing convolutional neural community (CNN) architectures.
Textual content inputs are transformed into tokens utilizing algorithms like BytePair Encoding (BPE) or SentencePiece. Then again, audio indicators are transformed into spectrograms or mel-frequency cepstral coefficients (MFCCs). Video information nonetheless is damaged down to every body in sequential kind.
Step 2: Tokenization – The thought behind tokenization is to transform the information into an ordinary kind in order that the machine can perceive the context of it. For instance, to transform textual content into tokens, pure language processing (NLP) is used.
For picture tokenization, the system makes use of pre-trained convolutional neural networks like ResNet or Imaginative and prescient Transformer (ViT) architectures. The audio indicators are transformed into tokens utilizing sign processing methods in order that audio waveforms could be transformed into compact and significant expressions.
Step 3: Embedding Layer – On this step, the tokens (which we achieved within the earlier step) are transformed into dense vectors in a manner that these vectors can seize the context of the information. The factor to notice right here is every modality develops its personal vectors that are cross-compatible with others.
Step 4: Cross-Modal Fusion – Until now, fashions had been capable of perceive the information until the person mannequin stage however from the 4th step, it adjustments. In cross-modal fusion, the system learns to attach dots between a number of modalities for deeper contextual relationships.
One good instance the place the picture of a seaside, a textual illustration of a trip on the seaside, and audio clips of waves, wind, and a cheerful crowd work together. This fashion the multimodal LLM not solely understands the inputs but in addition places all the pieces collectively as one single expertise.
Step 5: Neural Community Processing – Neural community processing is the step the place info gathered from the cross-modal fusion (earlier step) will get transformed into significant insights. Now, the mannequin will use deep studying to research the intricate connections that had been discovered throughout cross-modal fusion.
Picture a case the place you mix x-ray stories, affected person notes, and symptom descriptions. With neural community processing, it is not going to solely listing info however will create a holistic understanding that may establish potential well being dangers and counsel attainable diagnoses.
Step 6 – Output Era – That is the ultimate step the place the MLLM will craft a exact output for you. In contrast to conventional fashions which are sometimes context-limited, MLLM’s output can have a depth and a contextual understanding.
Additionally, the output can have multiple format comparable to making a dataset, creating a visible illustration of a state of affairs, and even an audio or video output of a particular occasion.
[Also Read: RAG vs. Fine-Tuning: Which One Suits Your LLM?]
What are the Functions of Multimodal Massive Language Fashions?
Despite the fact that the MLLM is a just lately tossed time period, there are lots of of purposes the place you can see exceptional enhancements in comparison with conventional strategies, all due to MLLMs. Listed here are some necessary purposes of MLLM: