
This submit is cowritten by Mike Koźmiński from Beekeeper.
Giant Language Fashions (LLMs) are evolving quickly, making it troublesome for organizations to pick out the very best mannequin for every particular use case, optimize prompts for high quality and price, adapt to altering mannequin capabilities, and personalize responses for various customers.
Selecting the “proper” LLM and immediate isn’t a one-time determination—it shifts as fashions, costs, and necessities change. System prompts have gotten bigger (e.g. Anthropic system immediate) and extra advanced. Loads of mid-sized firms don’t have sources to rapidly consider and enhance them. To handle this situation, Beekeeper constructed an Amazon Bedrock-powered system that repeatedly evaluates mannequin+immediate candidates, ranks them on a reside leaderboard, and routes every request to the present most suitable option for that use case.
Beekeeper: Connecting and empowering the frontline workforce
Beekeeper gives a complete digital office system particularly designed for frontline workforce operations. The corporate supplies a mobile-first communication and productiveness answer that connects non-desk employees with one another and headquarters, enabling organizations to streamline operations, enhance worker engagement, and handle duties effectively. Their system options strong integration capabilities with current enterprise techniques (human sources, scheduling, payroll), whereas focusing on industries with massive deskless workforces resembling hospitality, manufacturing, retail, healthcare, and transportation. At its core, Beekeeper addresses the standard disconnect between frontline staff and their organizations by offering accessible digital instruments that improve communication, operational effectivity, and workforce retention, all delivered by means of a cloud-based SaaS system with cell apps, administrative dashboards, and enterprise-grade security measures.
Beekeeper’s answer: A dynamic analysis system
Beekeeper solved this problem with an automatic system that repeatedly checks totally different mannequin and immediate mixtures, ranks choices primarily based on high quality, value, and velocity, incorporates consumer suggestions to personalize responses, and routinely routes requests to the present best choice. High quality is scored with a small artificial check set and validated in manufacturing with consumer suggestions (thumbs up/down and feedback). By incorporating immediate mutation, Beekeeper created an natural system that evolves over time. The result’s a constantly-optimizing setup that balances high quality, latency, and price—and adapts routinely when the panorama modifications.
Actual-world instance: Chat Summarization
Beekeeper’s Frontline Success Platform unifies communication for deskless employees throughout industries. One sensible software of their LLM system is chat summarization. When a consumer returns to shift, they could discover a chat with many unread messages – as a substitute of studying every little thing, they’ll request a abstract. The system generates a concise overview with motion gadgets tailor-made to the consumer’s wants. Customers can then present suggestions to enhance future summaries. This seemingly easy characteristic depends on refined know-how behind the scenes. The system should perceive dialog context, determine necessary factors, acknowledge motion gadgets, and current data concisely—all whereas adapting to consumer preferences.
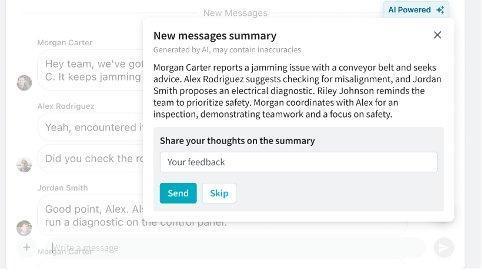
Answer overview
Beekeeper’s answer consists of two primary phases: constructing a baseline leaderboard and personalizing with consumer suggestions.
The system makes use of a number of AWS elements, together with Amazon EventBridge for scheduling, Amazon Elastic Kubernetes Service (EKS) for orchestration, AWS Lambda for analysis features, Amazon Relational Database Service (RDS) for information storage, and Amazon Mechanical Turk for handbook validation.
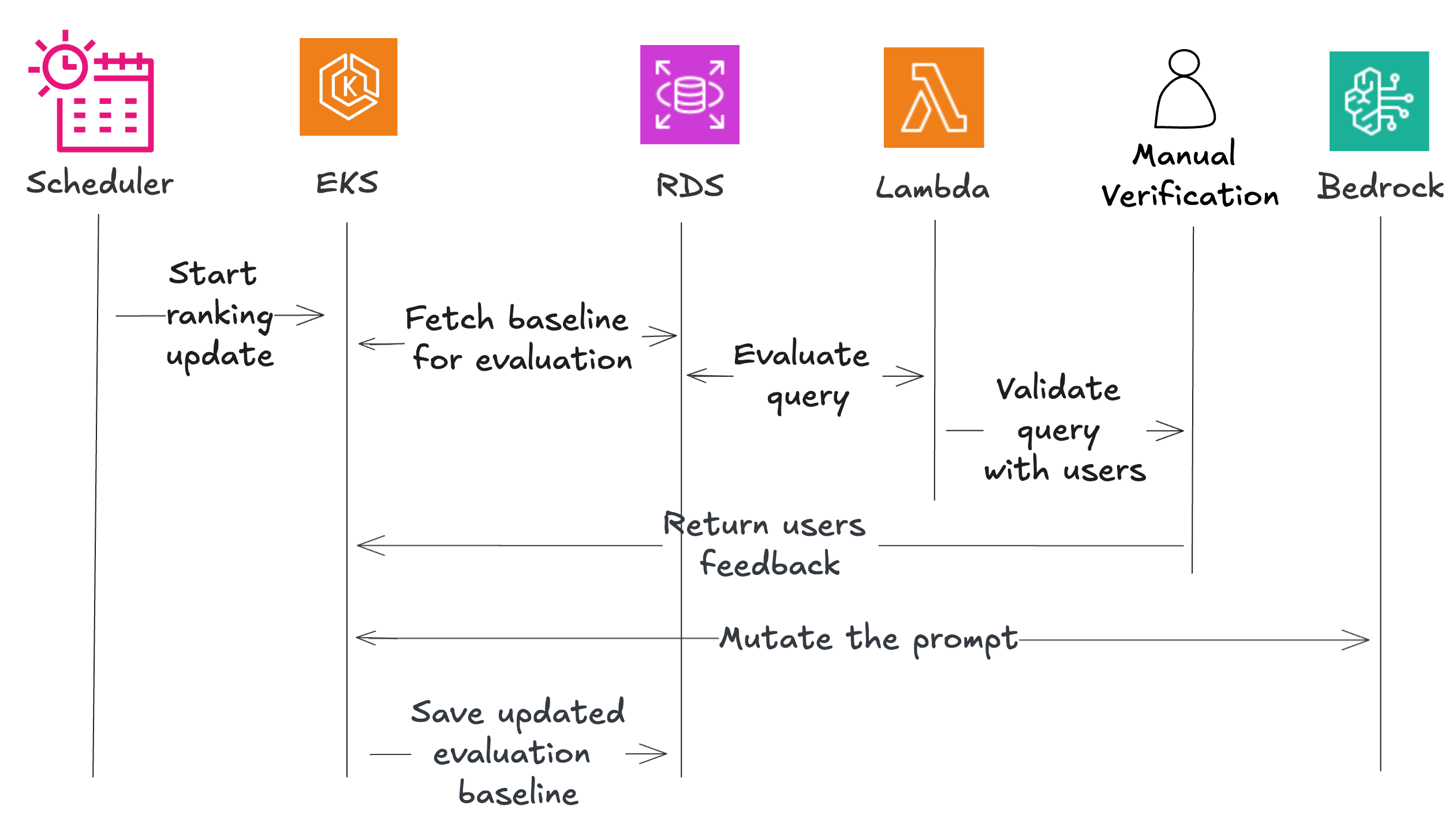
The workflow begins with an artificial rank creator that establishes baseline efficiency. A scheduler triggers the coordinator, which fetches check information and sends it to evaluators. These evaluators check every mannequin/immediate pair and return outcomes, with a portion despatched for handbook validation. The system mutates promising prompts to create variations, evaluates these once more, and saves the very best performers. When consumer suggestions arrives, the system incorporates it by means of a second section. The coordinator fetches ranked mannequin/immediate pairs and sends them with consumer suggestions to a mutator, which returns customized prompts. A drift detector makes positive these customized variations don’t stray too removed from high quality requirements, and validated prompts are saved for particular customers.
Constructing the baseline leaderboard
To kick-start the optimization journey, Beekeeper engineers chosen numerous fashions and offered them with domain-specific human-written prompts. The tech crew examined these prompts utilizing LLM-generated examples to verify they have been error-free. A stable baseline is essential right here. This basis helps them refine their method when incorporating suggestions from actual customers.
The next sections, we dive into their success metrics, which guides their refinement of prompts and helps create an optimum consumer expertise.
Analysis standards for baseline
The standard of summaries generated by mannequin/immediate pairs is measured utilizing each quantitative and qualitative metrics, together with the next:
- Compression ratio – Measures abstract size relative to the unique textual content, rewarding adherence to focus on lengths and penalizing extreme size.
- Presence of motion gadgets – Makes positive user-specific motion gadgets are clearly recognized.
- Lack of hallucinations – Validates factual accuracy and consistency.
- Vector comparability – Assesses semantic similarity to human-generated good outcomes.
Within the following sections, we stroll by means of every of the analysis standards and the way they’re applied.
Compression ratio
The compression ratio evaluates the size of the summarized textual content in comparison with the unique one and its adherence to a goal size (it rewards compression ratios near the goal and penalizes texts that deviate from goal size). The corresponding rating, between 0 and 100, is computed programmatically with the next Python code:
Presence of motion gadgets associated to the consumer
To verify whether or not the abstract comprises all of the motion gadgets associated to the customers, Beekeeper depends on the comparability to the bottom reality. For the bottom reality comparability, the anticipated output format requires a bit labeled “Motion gadgets:” adopted by bullet factors, which makes use of common expressions to extract the motion merchandise listing as within the following Python code:
They embrace this extra extraction step to verify the info is formatted in a means that the LLM can simply course of. The extracted listing is distributed to an LLM with the request to verify whether or not it’s right or not. A +1 rating is assigned for every motion merchandise accurately assigned, and a -1 is utilized in case of false optimistic. After that, scores are normalized to not penalize/gratify summaries with roughly motion gadgets.
Lack of hallucinations
To guage hallucinations, Beekeeper makes use of two approaches: cross-LLM analysis and handbook validation.

Within the cross-LLM analysis, a abstract created by LLM A (for instance, Mistral Giant) is handed to the evaluator part, along with the immediate and the preliminary enter. The evaluator submits this textual content to LLM B (for instance, Anthropic’s Claude), asking if the information from the abstract match the uncooked context. An LLM of a distinct household is used for this analysis. Amazon Bedrock makes this train notably easy by means of the Converse API—customers can choose totally different LLMs by altering the mannequin identifier string.
One other necessary level is the presence of handbook verification on a small set of evaluations at Beekeeper, to keep away from circumstances of double hallucination. They assign a rating of 1 if no hallucination was detected and -1 if any is detected. For the entire pipeline, they use the identical heuristic of seven% handbook analysis (particulars mentioned additional alongside on this submit).
Vector comparability
As an extra analysis technique, semantic similarity is used for information with out there floor reality data. The embedding fashions are chosen among the many MTEB Leaderboard (multi-task and multi-language comparability of embedding fashions), contemplating massive vector dimensionality to maximise the quantity of data saved contained in the vector. Beekeeper makes use of as its baseline Qwen3, a mannequin offering a 4096 dimensionality and supporting 16-bit quantization for quick computation. Additional embedding fashions are additionally used straight from Amazon Bedrock. After computing the embedding vectors for each the bottom reality reply and the one generated by a given mannequin/immediate pair, cosine similarity is used to compute the similarity, as proven within the following Python code:
Analysis baseline
The analysis baseline of every mannequin/immediate pair is carried out by accumulating the generated output of a set of fastened, predefined queries which can be manually annotated with floor reality outputs containing the “true solutions” (on this case, the best summaries from in-house and public dataset). This set as talked about earlier than is created from a public dataset in addition to hand crafted examples higher representing a buyer’s area. The scores are evaluated routinely primarily based on the metrics described earlier: compression, lack of hallucinations, presence of motion gadgets, and vector comparability, to construct a baseline model of the leaderboard.
Guide evaluations
For extra validation, Beekeeper manually critiques a scientifically decided pattern of evaluations utilizing Amazon Mechanical Turk. This pattern measurement is calculated utilizing Cochran’s method to assist statistical significance.
Amazon Mechanical Turk permits companies to harness human intelligence for duties computer systems can’t carry out successfully. This crowdsourcing market connects customers with a world, on-demand workforce to finish microtasks like information labeling, content material moderation, and analysis validation—serving to to scale operations with out sacrificing high quality or rising overhead. As talked about earlier, Beekeeper employs human suggestions to confirm that the automated LLM-based ranking system is working accurately. Primarily based on their prior assumptions, they know what share of responses needs to be labeled as containing hallucinations. If the quantity detected by human verification diverges by greater than two share factors from their estimations, they know that the automated course of isn’t working correctly and desires revision. Now that Beekeeper has established their baseline, they’ll present the very best outcomes to their prospects. By always updating their fashions, they’ll carry new worth in an automatic trend. Every time their engineers have concepts for brand new immediate optimization, they’ll let the pipeline consider it in opposition to earlier ones utilizing baseline outcomes. Beekeeper can take it additional and embed consumer suggestions, permitting for extra customizable outcomes. Nevertheless, they don’t need consumer suggestions to completely change the habits of their mannequin by means of immediate injection in suggestions. Within the following part, we look at the natural a part of Beekeeper’s pipeline that embeds consumer preferences into responses with out affecting different customers.
Analysis of consumer suggestions
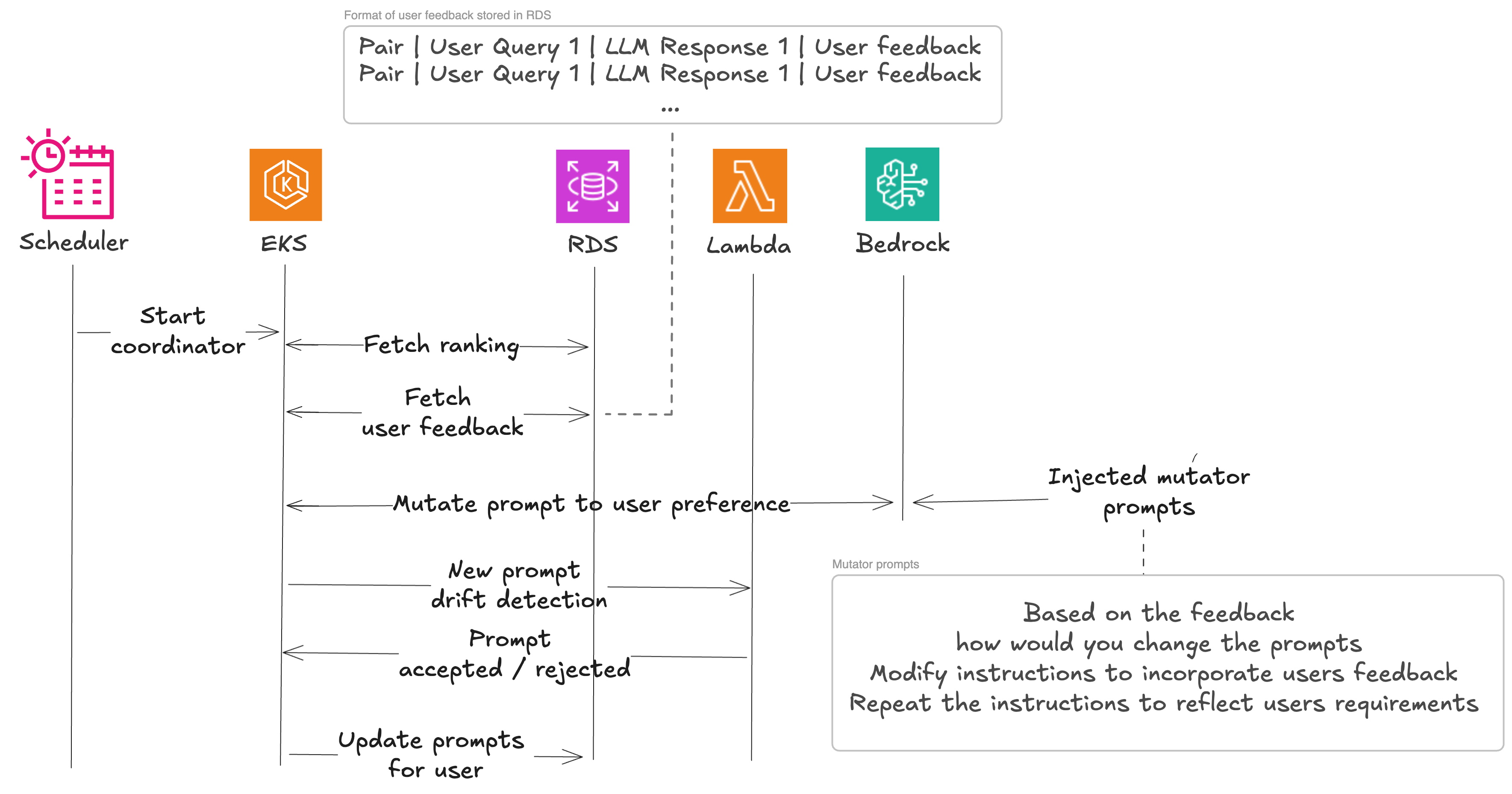
Now that Beekeeper has established their baseline utilizing floor reality set, they’ll begin incorporating human suggestions. This works in accordance with the identical ideas because the beforehand described hallucination detection course of. Person suggestions is pulled along with enter and LLM response. They move inquiries to the LLM within the following format:
They use this to verify whether or not the suggestions offered continues to be relevant after the prompt-model pair was up to date. This works as a baseline for incorporating consumer suggestions. They’re now prepared to start out mutating the immediate. That is finished to keep away from suggestions being utilized a number of occasions. If mannequin change or mutation already solved the issue, there is no such thing as a want to use it once more.
The mutation course of consists of reevaluating the consumer generated dataset after immediate mutation till the output incorporates the consumer suggestions, then we use the baseline to know variations and discard modifications in case they undermine mannequin work.
The 4 best-performing mannequin/immediate pairs chosen within the baseline analysis (for mutated prompts) are additional processed by means of a immediate mutation course of, to verify for residual enchancment of the outcomes. That is important in an setting the place even small modifications to a immediate can result in dramatically totally different outcomes when used along with consumer suggestions.
The preliminary immediate is enriched with a immediate mutation, the obtained consumer suggestions, a considering type (a selected cognitive method like “Make it artistic” or “Assume in steps” that guides how the LLM approaches the mutation activity), the consumer context, and is distributed to the LLM to supply a mutated immediate. The mutated prompts are added to the listing, evaluated, and the corresponding scores are integrated into the leaderboard. Mutation prompts also can embrace customers suggestions when such is current.
Examples of generated mutations prompts embrace:
Answer instance
The baseline analysis course of begins with eight pairs of prompts and related fashions (Amazon Nova, Anthropic Claude 4 Sonnet, Meta Llama 3, and Mistral 8x7B). Beekeeper often makes use of 4 base prompts and two fashions to start out with. These prompts are used throughout all of the fashions, however outcomes are thought of in pairs of prompt-models. Fashions are routinely up to date as newer variations grow to be out there by way of Amazon Bedrock.
Beekeeper begins by evaluating the eight current pairs:
- Every analysis requires producing 20 summaries per pair (8 x 20 = 160)
- Every abstract is checked by three static checks and two LLM checks (160 x 2 = 320)
In whole, this creates 480 LLM calls. Scores are in contrast, making a leaderboard, and two prompt-model pairs are chosen. These two prompts are mutated utilizing consumer suggestions, creating 10 new prompts, that are once more evaluated, creating 600 calls to the LLM (10 x 20 + 10 x 20 x 2 = 600).
This course of may be run n occasions to carry out extra artistic mutations; Beekeeper often performs two cycles.
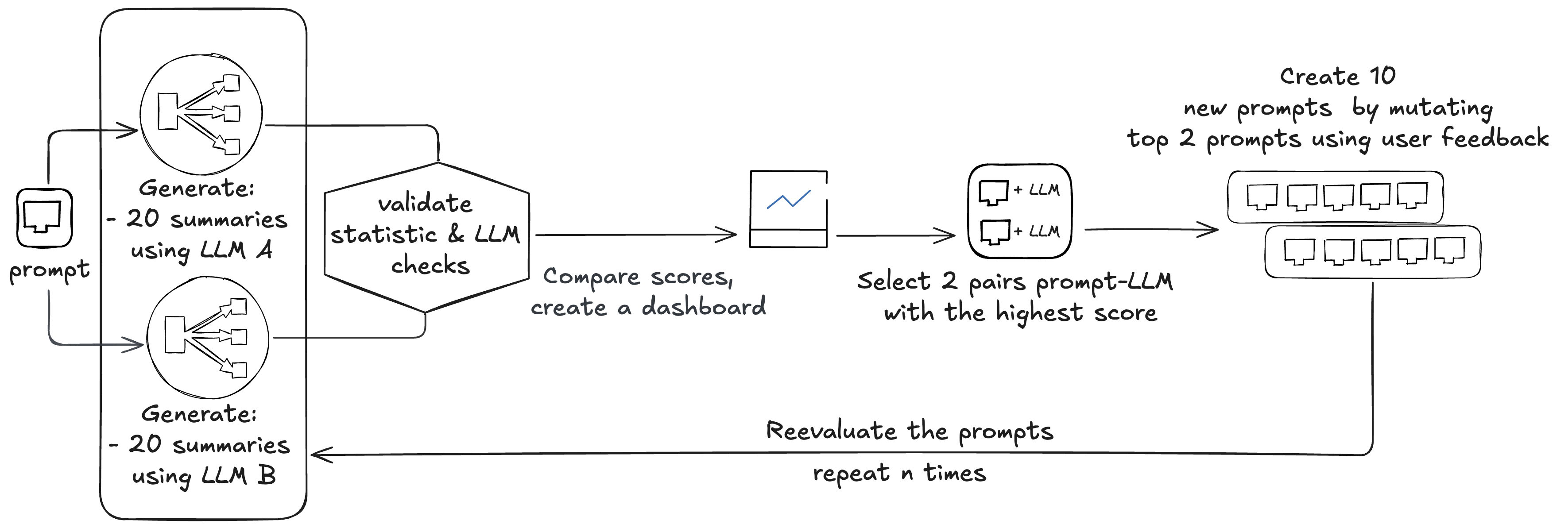
In whole, this train performs checks on (8 + 10 + 10) x 2 mannequin/immediate pairs. The entire course of on common requires round 8,352,000 enter tokens and round 1,620,000 output tokens, costing round $48.Newly chosen mannequin/immediate pairs are utilized in manufacturing with ratios 1st: 50%, 2nd: 30%, and third: 20%.After deploying the brand new mannequin/immediate pairs, Beekeeper gathers suggestions from the customers. This suggestions is used to feed the mutator to create three new prompts. These prompts are despatched for drift detection, which compares them to the baseline. In whole, they create 4 LLM calls, costing round 4,800 enter tokens and 500 output tokens.
Advantages
The important thing good thing about Beekeeper’s answer is its capacity to quickly evolve and adapt to consumer wants. With this method, they’ll make preliminary estimations of which mannequin/immediate pairs could be optimum candidates for every activity, whereas controlling each value and the standard of outcomes. By combining the advantages of artificial information with consumer suggestions, the answer is appropriate even for smaller engineering groups. As a substitute of specializing in generic prompts, Beekeeper prioritizes tailoring the immediate enchancment course of to satisfy the distinctive wants of every tenant. By doing so, they’ll refine prompts to be extremely related and user-friendly. This method permits customers to develop their very own type, which in flip enhances their expertise as they supply suggestions and see its impression. One of many unintended effects they noticed is that sure teams of individuals favor totally different types of communication. By mapping these outcomes to buyer interactions, they goal to current a extra tailor-made expertise. This makes positive that suggestions given by one consumer doesn’t impression one other. Their preliminary outcomes counsel 13–24% higher scores on response when aggregated per tenant. In abstract, the proposed answer gives a number of notable advantages. It reduces handbook labor by automating the LLM and immediate choice course of, shortens the suggestions cycle, permits the creation of user- or tenant-specific enhancements, and supplies the capability to seamlessly combine and estimate the efficiency of recent fashions in the identical method because the earlier ones.
Conclusion
Beekeeper’s automated leaderboard method and human suggestions loop system for dynamic LLM and immediate pair choice addresses the important thing challenges organizations face in navigating the quickly evolving panorama of language fashions. By repeatedly evaluating and optimizing high quality, measurement, velocity, and price, the answer helps prospects use the best-performing mannequin/immediate mixtures for his or her particular use circumstances. Wanting forward, Beekeeper plans to additional refine and broaden the capabilities of this method, incorporating extra superior strategies for immediate engineering and analysis. Moreover, the crew is exploring methods to empower customers to develop their very own custom-made prompts, fostering a extra customized and interesting expertise. In case your group is exploring methods to optimize LLM choice and immediate engineering, there’s no want to start out from scratch. Utilizing AWS providers like Amazon Bedrock for mannequin entry, AWS Lambda for light-weight analysis, Amazon EKS for orchestration, and Amazon Mechanical Turk for human validation, a pipeline may be constructed that routinely evaluates, ranks, and evolves your prompts. As a substitute of manually updating prompts or re-benchmarking fashions, give attention to making a feedback-driven system that repeatedly improves outcomes in your customers. Begin with a small set of fashions and prompts, outline your analysis metrics, and let the system scale as new fashions and use circumstances emerge.
Concerning the authors
 Mike (Michał) Koźmiński is a Zürich-based Principal Engineer at Beekeeper by LumApps, the place he builds the foundations that make AI a first-class a part of the product. With 10+ years spanning startups and enterprises, he focuses on translating new know-how into dependable techniques and actual buyer impression.
Mike (Michał) Koźmiński is a Zürich-based Principal Engineer at Beekeeper by LumApps, the place he builds the foundations that make AI a first-class a part of the product. With 10+ years spanning startups and enterprises, he focuses on translating new know-how into dependable techniques and actual buyer impression.
 Magdalena Gargas is a Options Architect keen about know-how and fixing buyer challenges. At AWS, she works largely with software program firms, serving to them innovate within the cloud.
Magdalena Gargas is a Options Architect keen about know-how and fixing buyer challenges. At AWS, she works largely with software program firms, serving to them innovate within the cloud.
 Luca Perrozzi is a Options Architect at Amazon Net Providers (AWS), primarily based in Switzerland. He focuses on innovation subjects at AWS, particularly within the space of Synthetic Intelligence. Luca holds a PhD in particle physics and has 15 years of hands-on expertise as a analysis scientist and software program engineer.
Luca Perrozzi is a Options Architect at Amazon Net Providers (AWS), primarily based in Switzerland. He focuses on innovation subjects at AWS, particularly within the space of Synthetic Intelligence. Luca holds a PhD in particle physics and has 15 years of hands-on expertise as a analysis scientist and software program engineer.
 Simone Pomata is a Principal Options Architect at AWS. He has labored enthusiastically within the tech business for greater than 10 years. At AWS, he helps prospects reach constructing new applied sciences every single day.
Simone Pomata is a Principal Options Architect at AWS. He has labored enthusiastically within the tech business for greater than 10 years. At AWS, he helps prospects reach constructing new applied sciences every single day.