
How do AI picture mills image the previous? New analysis signifies that they drop smartphones into the 18th century, insert laptops into Thirties scenes, and place vacuum cleaners in Nineteenth-century properties, elevating questions on how these fashions think about historical past – and whether or not they’re able to contextual historic accuracy in any respect.
Early in 2024, the image-generation capabilities of Google’s Gemini multimodal AI mannequin got here below criticism for imposing demographic equity in inappropriate contexts, akin to producing WWII German troopers with unlikely provenance:
Demographically inconceivable German navy personnel, as envisaged by Google’s Gemini multimodal mannequin in 2024. Supply: Gemini AI/Google by way of The Guardian
This was an instance the place efforts to redress bias in AI fashions didn’t take account of a historic context. On this case, the problem was addressed shortly after. Nevertheless, diffusion-based fashions stay liable to generate variations of historical past that confound trendy and historic facets and artefacts.
That is partly due to entanglement, the place qualities that steadily seem collectively in coaching knowledge turn into fused within the mannequin’s output. For instance, if trendy objects like smartphones usually co-occur with the act of speaking or listening within the dataset, the mannequin might be taught to affiliate these actions with trendy units, even when the immediate specifies a historic setting. As soon as these associations are embedded within the mannequin’s inside representations, it turns into troublesome to separate the exercise from its modern context, resulting in traditionally inaccurate outcomes.
A brand new paper from Switzerland, analyzing the phenomenon of entangled historic generations in latent diffusion fashions, observes that AI frameworks which are fairly able to creating photorealistic individuals nonetheless choose to depict historic figures in historic methods:
![From the new paper, diverse representations via LDM of the prompt' 'A photorealistic image of a person laughing with a friend in [the historical period]', with each period indicated in each output. As we can see, the medium of the era has become associated with the content. Source: https://arxiv.org/pdf/2505.17064](https://www.unite.ai/wp-content/uploads/2025/05/laughing-with-a-friend.jpg)
From the brand new paper, numerous representations by way of LDM of the immediate’ ‘A photorealistic picture of an individual laughing with a good friend in [the historical period]’, with every interval indicated in every output. As we are able to see, the medium of the period has turn into related to the content material. Supply: https://arxiv.org/pdf/2505.17064
For the immediate ‘A photorealistic picture of an individual laughing with a good friend in [the historical period]’, one of many three examined fashions usually ignores the unfavourable immediate ‘monochrome’ and as a substitute makes use of coloration therapies that mirror the visible media of the required period, for example mimicking the muted tones of celluloid movie from the Nineteen Fifties and Seventies.
In testing the three fashions for his or her capability to create anachronisms (issues which aren’t of the goal interval, or ‘out of time’ – which can be from the goal interval’s future in addition to its previous), they discovered a normal disposition to conflate timeless actions (akin to ‘singing’ or ‘cooking’) with trendy contexts and gear:

Various actions which are completely legitimate for earlier centuries are depicted with present or more moderen know-how and paraphernalia, in opposition to the spirit of the requested imagery.
Of notice is that smartphones are notably troublesome to separate from the idiom of pictures, and from many different historic contexts, since their proliferation and depiction is well-represented in influential hyperscale datasets akin to Frequent Crawl:

Within the Flux generative text-to-image mannequin, communications and smartphones are tightly-associated ideas – even when historic context doesn’t allow it.
To find out the extent of the issue, and to present future analysis efforts a approach ahead with this specific bugbear, the brand new paper’s authors developed a bespoke dataset in opposition to which to check generative techniques. In a second, we’ll check out this new work, which is titled Artificial Historical past: Evaluating Visible Representations of the Previous in Diffusion Fashions, and comes from two researchers on the College of Zurich. The dataset and code are publicly obtainable.
A Fragile ‘Fact’
Among the themes within the paper contact on culturally delicate points, such because the under-representation of races and gender in historic representations. Whereas Gemini’s imposition of racial equality within the grossly inequitable Third Reich is an absurd and insulting historic revision, restoring ‘conventional’ racial representations (the place diffusion fashions have ‘up to date’ these) would usually successfully ‘re-whitewash’ historical past.
Many latest hit historic exhibits, akin to Bridgerton, blur historic demographic accuracy in methods more likely to affect future coaching datasets, complicating efforts to align LLM-generated interval imagery with conventional requirements. Nevertheless, it is a advanced subject, given the historic tendency of (western) historical past to favor wealth and whiteness, and to depart so many ‘lesser’ tales untold.
Making an allowance for these difficult and ever-shifting cultural parameters, let’s check out the researchers’ new method.
Methodology and Checks
To check how generative fashions interpret historic context, the authors created HistVis, a dataset of 30,000 pictures produced from 100 prompts depicting frequent human actions, every rendered throughout ten distinct time intervals:
A pattern from the HistVis dataset, which the authors have made obtainable at Hugging Face. Supply: https://huggingface.co/datasets/latentcanon/HistVis
The actions, akin to cooking, praying or listening to music, had been chosen for his or her universality, and phrased in a impartial format to keep away from anchoring the mannequin in any specific aesthetic. Time intervals for the dataset vary from the seventeenth century to the current day, with added give attention to 5 particular person many years from the 20 th century.
30,000 pictures had been generated utilizing three widely-used open-source diffusion fashions: Steady Diffusion XL; Steady Diffusion 3; and FLUX.1. By isolating the time interval as the one variable, the researchers created a structured foundation for evaluating how historic cues are visually encoded or ignored by these techniques.
Visible Model Dominance
The writer initially examined whether or not generative fashions default to particular visible types when depicting historic intervals; as a result of it appeared that even when prompts included no point out of medium or aesthetic, the fashions would usually affiliate specific centuries with attribute types:
![Predicted visual styles for images generated from the prompt “A person dancing with another in the [historical period]” (left) and from the modified prompt “A photorealistic image of a person dancing with another in the [historical period]” with “monochrome picture” set as a negative prompt (right).](https://www.unite.ai/wp-content/uploads/2025/05/period-style.jpg)
Predicted visible types for pictures generated from the immediate ‘An individual dancing with one other within the [historical period]’ (left) and from the modified immediate ‘A photorealistic picture of an individual dancing with one other within the [historical period]’ with ‘monochrome image’ set as a unfavourable immediate (proper).
To measure this tendency, the authors educated a convolutional neural community (CNN) to categorise every picture within the HistVis dataset into one among 5 classes: drawing; engraving; illustration; portray; or pictures. These classes had been supposed to mirror frequent patterns that emerge throughout time-periods, and which help structured comparability.
The classifier was based mostly on a VGG16 mannequin pre-trained on ImageNet and fine-tuned with 1,500 examples per class from a WikiArt-derived dataset. Since WikiArt doesn’t distinguish monochrome from coloration pictures, a separate colorfulness rating was used to label low-saturation pictures as monochrome.
The educated classifier was then utilized to the total dataset, with the outcomes exhibiting that each one three fashions impose constant stylistic defaults by interval: SDXL associates the seventeenth and 18th centuries with engravings, whereas SD3 and FLUX.1 have a tendency towards work. In twentieth-century many years, SD3 favors monochrome pictures, whereas SDXL usually returns trendy illustrations.
These preferences had been discovered to persist regardless of immediate changes, suggesting that the fashions encode entrenched hyperlinks between fashion and historic context.
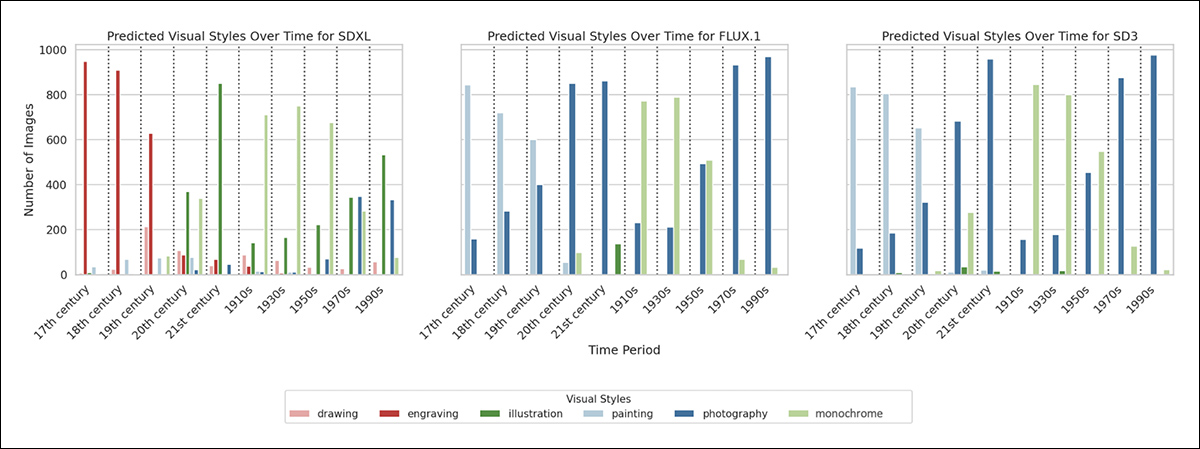
Predicted visible types of generated pictures throughout historic intervals for every diffusion mannequin, based mostly on 1,000 samples per interval per mannequin.
To quantify how strongly a mannequin hyperlinks a historic interval to a specific visible fashion, the authors developed a metric they title Visible Model Dominance (VSD). For every mannequin and time interval, VSD is outlined because the proportion of outputs predicted to share the commonest fashion:
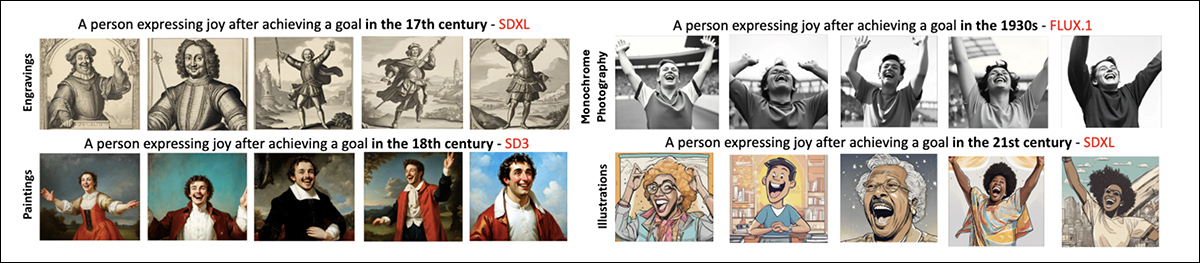
Examples of stylistic biases throughout the fashions.
The next rating signifies {that a} single fashion dominates the outputs for that interval, whereas a decrease rating factors to better variation. This makes it potential to check how tightly every mannequin adheres to particular stylistic conventions throughout time.
Utilized to the total HistVis dataset, the VSD metric reveals differing ranges of convergence, serving to to make clear how strongly every mannequin narrows its visible interpretation of the previous:

The outcomes desk above exhibits VSD scores throughout historic intervals for every mannequin. Within the seventeenth and 18th centuries, SDXL tends to supply engravings with excessive consistency, whereas SD3 and FLUX.1 favor portray. By the twentieth and twenty first centuries, SD3 and FLUX.1 shift towards pictures, whereas SDXL exhibits extra variation, however usually defaults to illustration.
All three fashions show a powerful choice for monochrome imagery in earlier many years of the twentieth century, notably the 1910s, Thirties and Nineteen Fifties.
To check whether or not these patterns may very well be mitigated, the authors used immediate engineering, explicitly requesting photorealism and discouraging monochrome output utilizing a unfavourable immediate. In some instances, dominance scores decreased, and the main fashion shifted, for example, from monochrome to portray, within the seventeenth and 18th centuries.
Nevertheless, these interventions hardly ever produced genuinely photorealistic pictures, indicating that the fashions’ stylistic defaults are deeply embedded.
Historic Consistency
The subsequent line of research checked out historic consistency: whether or not generated pictures included objects that didn’t match the time interval. As a substitute of utilizing a hard and fast record of banned gadgets, the authors developed a versatile technique that leveraged giant language (LLMs) and vision-language fashions (VLMs) to identify parts that appeared misplaced, based mostly on the historic context.
The detection technique adopted the identical format because the HistVis dataset, the place every immediate mixed a historic interval with a human exercise. For every immediate, GPT-4o generated a listing of objects that might be misplaced within the specified time interval; and for each proposed object, GPT-4o produced a yes-or-no query designed to verify whether or not that object appeared within the generated picture.
For instance, given the immediate ‘An individual listening to music within the 18th century’, GPT-4o may establish trendy audio units as traditionally inaccurate, and produce the query Is the particular person utilizing headphones or a smartphone that didn’t exist within the 18th century?.
These questions had been handed again to GPT-4o in a visible question-answering setup, the place the mannequin reviewed the picture and returned a sure or no reply for every. This pipeline enabled detection of traditionally implausible content material with out counting on any predefined taxonomy of recent objects:

Examples of generated pictures flagged by the two-stage detection technique, exhibiting anachronistic parts: headphones within the 18th century; a vacuum cleaner within the Nineteenth century; a laptop computer within the Thirties; and a smartphone within the Nineteen Fifties.
To measure how usually anachronisms appeared within the generated pictures, the authors launched a easy technique for scoring frequency and severity. First, they accounted for minor wording variations in how GPT-4o described the identical object.
For instance, trendy audio machine and digital audio machine had been handled as equal. To keep away from double-counting, a fuzzy matching system was used to group these surface-level variations with out affecting genuinely distinct ideas.
As soon as all proposed anachronisms had been normalized, two metrics had been computed: frequency measured how usually a given object appeared in pictures for a particular time interval and mannequin; and severity measured how reliably that object appeared as soon as it had been recommended by the mannequin.
If a contemporary cellphone was flagged ten occasions and appeared in ten generated pictures, it acquired a severity rating of 1.0. If it appeared in solely 5, the severity rating was 0.5. These scores helped establish not simply whether or not anachronisms occurred, however how firmly they had been embedded within the mannequin’s output for every interval:
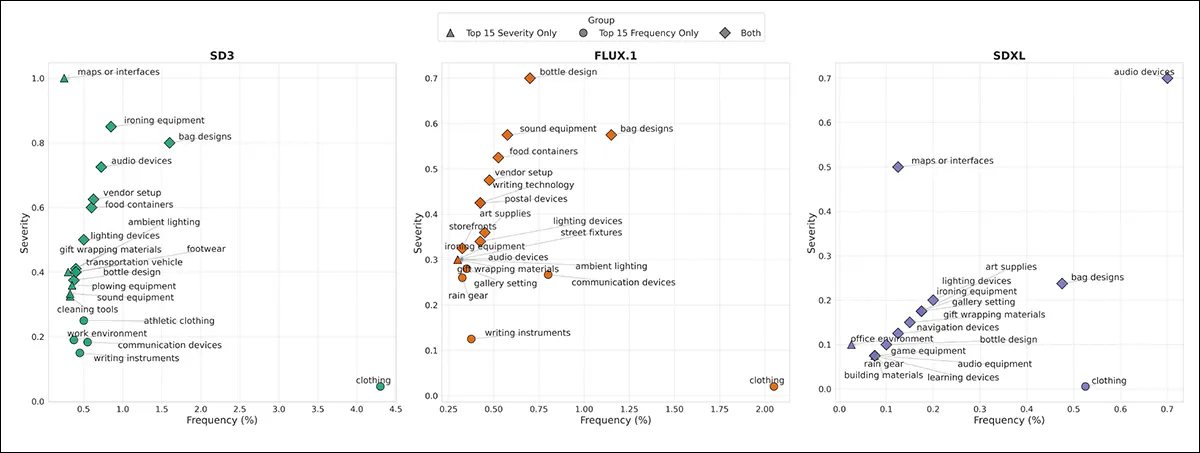
High fifteen anachronistic parts for every mannequin, plotted by frequency on the x-axis and severity on the y-axis. Circles mark parts ranked within the high fifteen by frequency, triangles by severity, and diamonds by each.
Above we see the fifteen commonest anachronisms for every mannequin, ranked by how usually they appeared and the way persistently they matched prompts.
Clothes was frequent however scattered, whereas gadgets like audio units and ironing gear appeared much less usually, however with excessive consistency – patterns that counsel the fashions usually reply to the exercise within the immediate greater than the time interval.
SD3 confirmed the very best price of anachronisms, particularly in Nineteenth-century and Thirties pictures, adopted by FLUX.1 and SDXL.
To check how nicely the detection technique matched human judgment, the authors ran a user-study that includes 1,800 randomly-sampled pictures from SD3 (the mannequin with the very best anachronism price), with every picture rated by three crowd-workers. After filtering for dependable responses, 2,040 judgments from 234 customers had been included, and the strategy agreed with the bulk vote in 72 p.c of instances.
GUI for the human analysis examine, exhibiting process directions, examples of correct and anachronistic pictures, and yes-no questions for figuring out temporal inconsistencies in generated outputs.
Demographics
The ultimate evaluation checked out how fashions painting race and gender over time. Utilizing the HistVis dataset, the authors in contrast mannequin outputs to baseline estimates generated by a language mannequin. These estimates weren’t exact however supplied a tough sense of historic plausibility, serving to to disclose whether or not the fashions tailored depictions to the supposed interval.
To evaluate these depictions at scale, the authors constructed a pipeline evaluating model-generated demographics to tough expectations for every time and exercise. They first used the FairFace classifier, a ResNet34-based instrument educated on over 100 thousand pictures, to detect gender and race within the generated outputs, permitting for measurement of how usually faces in every scene had been categorized as male or feminine, and for the monitoring of racial classes throughout intervals.

Examples of generated pictures exhibiting demographic overrepresentation throughout totally different fashions, time intervals and actions.
Low-confidence outcomes had been filtered out to cut back noise, and predictions had been averaged over all pictures tied to a particular time and exercise. To verify the reliability of the FairFace readings, a second system based mostly on DeepFace was used on a pattern of 5,000 pictures. The 2 classifiers confirmed sturdy settlement, supporting the consistency of the demographic readings used within the examine.
To match mannequin outputs with historic plausibility, the authors requested GPT-4o to estimate the anticipated gender and race distribution for every exercise and time interval. These estimates served as tough baselines somewhat than floor reality. Two metrics had been then used: underrepresentation and overrepresentation, measuring how a lot the mannequin’s outputs deviated from the LLM’s expectations.
The outcomes confirmed clear patterns: FLUX.1 usually overrepresented males, even in eventualities akin to cooking, the place girls had been anticipated; SD3 and SDXL confirmed comparable tendencies throughout classes akin to work, schooling and faith; white faces appeared greater than anticipated total, although this bias declined in more moderen intervals; and a few classes confirmed surprising spikes in non-white illustration, suggesting that mannequin habits might mirror dataset correlations somewhat than historic context:
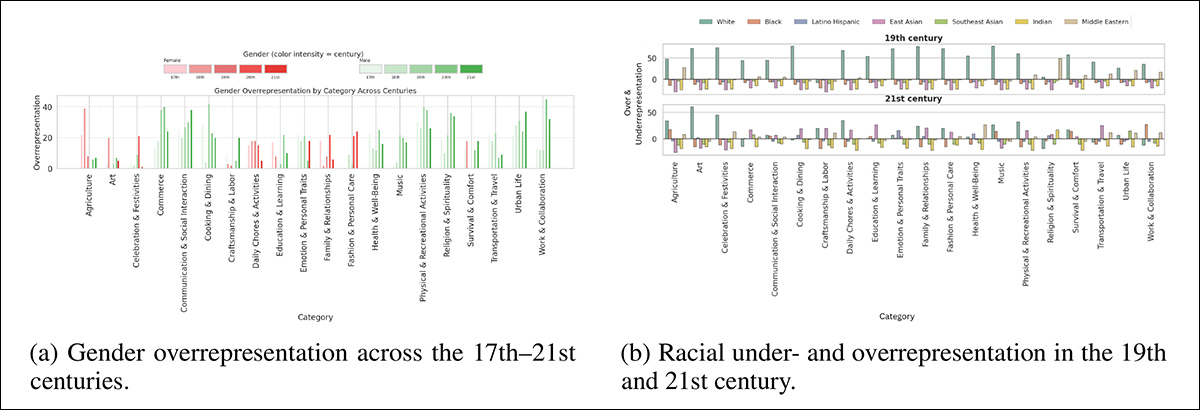
Gender and racial overrepresentation and underrepresentation in FLUX.1 outputs throughout centuries and actions, proven as absolute variations from GPT-4o demographic estimates.
The authors conclude:
‘Our evaluation reveals that [Text-to-image/TTI] fashions depend on restricted stylistic encodings somewhat than nuanced understandings of historic intervals. Every period is strongly tied to a particular visible fashion, leading to one-dimensional portrayals of historical past.
‘Notably, photorealistic depictions of individuals seem solely from the twentieth century onward, with solely uncommon exceptions in FLUX.1 and SD3, suggesting that fashions reinforce realized associations somewhat than flexibly adapting to historic contexts, perpetuating the notion that realism is a contemporary trait.
‘As well as, frequent anachronisms counsel that historic intervals will not be cleanly separated within the latent areas of those fashions, since trendy artifacts usually emerge in pre-modern settings, undermining the reliability of TTI techniques in schooling and cultural heritage contexts.’
Conclusion
In the course of the coaching of a diffusion mannequin, new ideas don’t neatly settle into predefined slots inside the latent house. As a substitute, they type clusters formed by how usually they seem and by their proximity to associated concepts. The result’s a loosely-organized construction the place ideas exist in relation to their frequency and typical context, somewhat than by any clear or empirical separation.
This makes it troublesome to isolate what counts as ‘historic’ inside a big, general-purpose dataset. Because the findings within the new paper counsel, many time intervals are represented extra by the look of the media used to depict them than by any deeper historic element.
That is one motive it stays troublesome to generate a 2025-quality photorealistic picture of a personality from (for example) the Nineteenth century; generally, the mannequin will depend on visible tropes drawn from movie and tv. When these fail to match the request, there may be little else within the knowledge to compensate. Bridging this hole will probably rely on future enhancements in disentangling overlapping ideas.
First printed Monday, Could 26, 2025