
Fraud continues to trigger important monetary injury globally, with U.S. shoppers alone shedding $12.5 billion in 2024—a 25% enhance from the earlier yr based on the Federal Commerce Fee. This surge stems not from extra frequent assaults, however from fraudsters’ rising sophistication. As fraudulent actions turn into extra complicated and interconnected, typical machine studying approaches fall brief by analyzing transactions in isolation, unable to seize the networks of coordinated actions that characterize trendy fraud schemes.
Graph neural networks (GNNs) successfully handle this problem by modeling relationships between entities—equivalent to customers sharing gadgets, areas, or fee strategies. By analyzing each community buildings and entity attributes, GNNs are efficient at figuring out refined fraud schemes the place perpetrators masks particular person suspicious actions however depart traces of their relationship networks. Nonetheless, implementing GNN-based on-line fraud prevention in manufacturing environments presents distinctive challenges: attaining sub-second inference responses, scaling to billions of nodes and edges, and sustaining operational effectivity for mannequin updates. On this publish, we present you the way to overcome these challenges utilizing GraphStorm, notably the brand new real-time inference capabilities of GraphStorm v0.5.
Earlier options required tradeoffs between functionality and ease. Our preliminary DGL method supplied complete real-time capabilities however demanded intricate service orchestration—together with manually updating endpoint configurations and payload codecs after retraining with new hyperparameters. This method additionally lacked mannequin flexibility, requiring customization of GNN fashions and configurations when utilizing architectures past relational graph convolutional networks (RGCN). Subsequent in-memory DGL implementations lowered complexity however encountered scalability limitations with enterprise knowledge volumes. We constructed GraphStorm to bridge this hole, by introducing distributed coaching and high-level APIs that assist simplify GNN growth at enterprise scale.
In a latest weblog publish, we illustrated GraphStorm’s enterprise-scale GNN mannequin coaching and offline inference functionality and ease. Whereas offline GNN fraud detection can establish fraudulent transactions after they happen—stopping monetary loss requires stopping fraud earlier than it occurs. GraphStorm v0.5 makes this potential by way of native real-time inference help by way of Amazon SageMaker AI. GraphStorm v0.5 delivers two improvements: streamlined endpoint deployment that reduces weeks of customized engineering—coding SageMaker entry level recordsdata, packaging mannequin artifacts, and calling SageMaker deployment APIs—to a single-command operation, and standardized payload specification that helps simplify consumer integration with real-time inference companies. These capabilities allow sub-second node classification duties like fraud prevention, empowering organizations to proactively counter fraud risk with scalable, operationally easy GNN options.
To showcase these capabilities, this publish presents a fraud prevention resolution. By this resolution, we present how a knowledge scientist can transition a skilled GNN mannequin to production-ready inference endpoints with minimal operational overhead. In case you’re keen on implementing GNN-based fashions for real-time fraud prevention or comparable enterprise circumstances, you’ll be able to adapt the approaches introduced right here to create your personal options.
Resolution overview
Our proposed resolution is a 4-step pipeline as proven within the following determine. The pipeline begins at step 1 with transaction graph export from a web-based transaction processing (OLTP) graph database to scalable storage (Amazon Easy Storage Service (Amazon S3) or Amazon EFS), adopted by distributed mannequin coaching in step 2. Step 3 is GraphStorm v0.5’s simplified deployment course of that creates SageMaker real-time inference endpoints with one command. After SageMaker AI has deployed the endpoint efficiently, a consumer utility integrates with the OLTP graph database that processes reside transaction streams in step 4. By querying the graph database, the consumer prepares subgraphs round to-be predicted transactions, convert the subgraph into standardized payload format, and invoke deployed endpoint for real-time prediction.
To supply concrete implementation particulars for every step within the real-time inference resolution, we show the whole workflow utilizing the publicly obtainable IEEE-CIS fraud detection activity.
Word: This instance makes use of a Jupyter pocket book because the controller of the general four-step pipeline for simplicity. For extra production-ready design, see the structure described in Construct a GNN-based real-time fraud detection resolution.
Conditions
To run this instance, you want an AWS account that the instance’s AWS Cloud Improvement Equipment (AWS CDK) code makes use of to create required sources, together with Amazon Digital Non-public Cloud (Amazon VPC), an Amazon Neptune database, Amazon SageMaker AI, Amazon Elastic Container Registry (Amazon ECR), Amazon S3, and associated roles and permission.
Word: These sources incur prices throughout execution (roughly $6 per hour with default settings). Monitor utilization rigorously and overview pricing pages for these companies earlier than continuing. Observe cleanup directions on the finish to keep away from ongoing prices.
Fingers-on instance: Actual-time fraud prevention with IEEE-CIS dataset
All implementation code for this instance, together with Jupyter notebooks and supporting Python scripts, is obtainable in our public repository. The repository offers an entire end-to-end implementation you could immediately execute and adapt in your personal fraud prevention use circumstances.
Dataset and activity overview
This instance makes use of the IEEE-CIS fraud detection dataset, containing 500,000 anonymized transactions with roughly 3.5% fraudulent circumstances. The dataset consists of 392 categorical and numerical options, with key attributes like card sorts, product sorts, addresses, and electronic mail domains forming the graph construction proven within the following determine. Every transaction (with an isFraud label) connects to Card Sort, Location, Product Sort, and Purchaser and Recipient electronic mail area entities, making a heterogeneous graph that allows GNN fashions to detect fraud patterns by way of entity relationships.
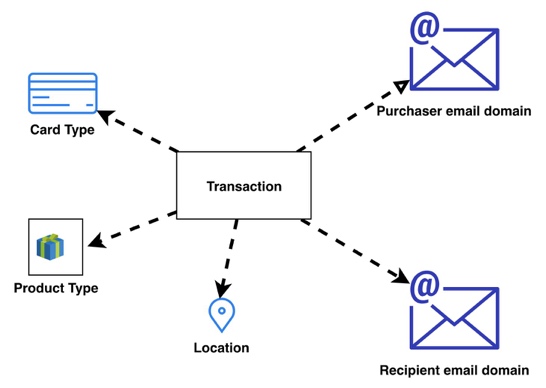
In contrast to our earlier publish that demonstrated GraphStorm plus Amazon Neptune Analytics for offline evaluation workflows, this instance makes use of a Neptune database because the OLTP graph retailer, optimized for the fast subgraph extraction required throughout real-time inference. Following the graph design, the tabular IEEE-CIS knowledge is transformed to a set CSV recordsdata appropriate with Neptune database format, permitting direct loading into each the Neptune database and GraphStorm’s GNN mannequin coaching pipeline with a single set of recordsdata.
Step 0: Setting setup
Step 0 establishes the working atmosphere required for the four-step fraud prevention pipeline. Full setup directions can be found within the implementation repository.
To run the instance resolution, it is advisable to deploy an AWS CloudFormation stack by way of the AWS CDK. This stack creates the Neptune DB occasion, the VPC to put it in, and applicable roles and safety teams. It moreover creates a SageMaker AI pocket book occasion, from which you run the instance notebooks that include the repository.
When deployment is completed (it takes roughly 10 minutes for required sources to be prepared), the AWS CDK prints a couple of outputs, one in every of which is the title of the SageMaker pocket book occasion you utilize to run by way of the notebooks:
You may navigate to the SageMaker AI pocket book UI, discover the corresponding pocket book occasion, and choose its Open Jupyterlab hyperlink to entry the pocket book.
Alternatively, you need to use the AWS Command Line Interface (AWS CLI) to get a pre-signed URL to entry the pocket book. You have to to interchange the
If you’re within the pocket book occasion net console, open the primary pocket book, 0-Information-Preparation.ipynb, to begin going by way of the instance.
Step 1: Graph building
Within the Pocket book 0-Information-Preparation, you remodel the tabular IEEE-CIS dataset into the heterogeneous graph construction proven within the determine at first of this part. The supplied Jupyter Pocket book extracts entities from transaction options, creating Card Sort nodes from card1–card6 options, Purchaser and Recipient nodes from electronic mail domains, Product Sort nodes from product codes, and Location nodes from geographic info. The transformation establishes relationships between transactions and these entities, producing graph knowledge in Neptune import format for direct ingestion into the OLTP graph retailer. The create_neptune_db_data() perform orchestrates this entity extraction and relationship creation course of throughout all node sorts (which takes roughly 30 seconds).
This pocket book additionally generates the JSON configuration file required by GraphStorm’s GConstruct command and executes the graph building course of. This GConstruct command transforms the Neptune-formatted knowledge right into a distributed binary graph format optimized for GraphStorm’s coaching pipeline, which partitions the heterogeneous graph construction throughout compute nodes to allow scalable mannequin coaching on industry-scale graphs (measured in billions of nodes and edges). For the IEEE-CIS knowledge, the GConstruct command takes 90 seconds to finish.
Within the Pocket book 1-Load-Information-Into-Neptune-DB, you load the CSV knowledge into the Neptune database occasion (takes roughly 9 minutes), which makes them obtainable for on-line inference. Throughout on-line inference, after deciding on a transaction node, you question the Neptune database to get the graph neighborhood of the goal node, retrieving the options of each node within the neighborhood and the subgraph construction across the goal.
Step 2: Mannequin coaching
After you could have transformed the information into the distributed binary graph format, it’s time to coach a GNN mannequin. GraphStorm offers command-line scripts to coach a mannequin with out writing code. Within the Pocket book 2-Mannequin-Coaching, you prepare a GNN mannequin utilizing GraphStorm’s node classification command with configuration managed by way of YAML recordsdata. The baseline configuration defines a two-layer RGCN mannequin with 128-dimensional hidden layers, coaching for 4 epochs with a 0.001 studying charge and 1024 batch measurement, which takes roughly 100 seconds for 1 epoch of mannequin coaching and analysis in an ml.m5.4xlarge occasion. To enhance fraud detection accuracy, the pocket book offers extra superior mannequin configurations just like the command under.
Arguments on this command handle the dataset’s label imbalance problem the place solely 3.5% of transactions are fraudulent by utilizing AUC-ROC because the analysis metric and utilizing class weights. The command additionally saves the best-performing mannequin together with important configuration recordsdata required for endpoint deployment. Superior configurations can additional improve mannequin efficiency by way of methods like HGT encoders, multi-head consideration, and class-weighted cross entropy loss perform, although these optimizations enhance computational necessities. GraphStorm permits these modifications by way of run time arguments and YAML configurations, decreasing the necessity for code modifications.
Step 3: Actual-time endpoint deployment
Within the Pocket book 3-GraphStorm-Endpoint-Deployment, you deploy the real-time endpoint by way of GraphStorm v0.5’s easy launch script. The deployment requires three mannequin artifacts generated throughout coaching: the saved mannequin file that accommodates weights, the up to date graph building JSON file with characteristic transformation metadata, and the runtime-updated coaching configuration YAML file. These artifacts allow GraphStorm to recreate the precise coaching configurations and mannequin for constant inference conduct. Notably, the up to date graph building JSON and coaching configuration YAML file accommodates essential configurations which are important for restoring the skilled mannequin on the endpoint and processing incoming request payloads. It’s essential to make use of the up to date JSON and YAML recordsdata for endpoint deployment.GraphStorm makes use of SageMaker AI convey your personal container (BYOC) to deploy a constant inference atmosphere. It’s essential to construct and push the GraphStorm real-time Docker picture to Amazon ECR utilizing the supplied shell scripts. This containerized method offers constant runtime environments appropriate with the SageMaker AI managed infrastructure. The Docker picture accommodates the required dependencies for GraphStorm’s real-time inference capabilities on the deployment atmosphere.
To deploy the endpoint, you need to use the GraphStorm-provided launch_realtime_endpoint.py script that helps you collect required artifacts and creates the required SageMaker AI sources to deploy an endpoint. The script accepts the Amazon ECR picture URI, IAM position, mannequin artifact paths, and S3 bucket configuration, robotically dealing with endpoint provisioning and configuration. By default, the script waits for endpoint deployment to be full earlier than exiting. When accomplished, it prints the title and AWS Area of the deployed endpoint for subsequent inference requests. You have to to interchange the fields enclosed by <> with the precise values of your atmosphere.
Step 4: Actual-time inference
Within the Pocket book 4-Pattern-Graph-and-Invoke-Endpoint, you construct a fundamental consumer utility that integrates with the deployed GraphStorm endpoint to carry out real-time fraud prevention on incoming transactions. The inference course of accepts transaction knowledge by way of standardized JSON payloads, executes node classification predictions in a couple of a whole lot of milliseconds, and returns fraud likelihood scores that allow speedy decision-making.
An end-to-end inference name for a node that already exists within the graph has three distinct phases:
- Graph sampling from the Neptune database. For a given goal node that already exists within the graph, retrieve its k-hop neighborhood with a fanout restrict, that’s, limiting the variety of neighbors retrieved at every hop by a threshold.
- Payload preparation for inference. Neptune returns graphs utilizing GraphSON, a specialised JSON-like knowledge format used to explain graph knowledge. At this step, it is advisable to convert the returned GraphSON to GraphStorm’s personal JSON specification. This step is carried out on the inference consumer, on this case a SageMaker pocket book occasion.
- Mannequin inference utilizing a SageMaker endpoint. After the payload is ready, you ship an inference request to a SageMaker endpoint that has loaded a beforehand skilled mannequin snapshot. The endpoint receives the request, performs any characteristic transformations wanted (equivalent to changing categorical options to one-hot encoding), creates the binary graph illustration in reminiscence, and makes a prediction for the goal node utilizing the graph neighborhood and skilled mannequin weights. The response is encoded to JSON and despatched again to the consumer.
An instance response from the endpoint would appear to be:
The information of curiosity for the one transaction you made a prediction for are within the prediction key and corresponding node_id. The prediction offers you the uncooked scores the mannequin produces for sophistication 0 (reputable) and sophistication 1 (fraudulent) on the corresponding 0 and 1 indexes of the predictions checklist. On this instance, the mannequin marks the transaction as almost certainly reputable. You’ll find the total GraphStorm response specification within the GraphStorm documentation.
Full implementation examples, together with consumer code and payload specs, are supplied within the repository to information integration with manufacturing programs.
Clear up
To cease accruing prices in your account, it is advisable to delete the AWS sources that you just created with the AWS CDK on the Setting Setup step.
You should first delete the SageMaker endpoint created through the Step 3 for cdk destroy to finish. See the Delete Endpoints and Sources for extra choices to delete an endpoint. When completed, you’ll be able to run the next from the repository’s root:
See the AWS CDK docs for extra details about the way to use cdk destroy, or see the CloudFormation docs for the way to delete a stack from the console UI. By default, the cdk destroy command doesn’t delete the mannequin artifacts and processed graph knowledge saved within the S3 bucket through the coaching and deployment course of. You could take away them manually. See Deleting a basic objective bucket for details about the way to empty and delete an S3 bucket the AWS CDK has created.
Conclusion
Graph neural networks handle complicated fraud prevention challenges by modeling relationships between entities that conventional machine studying approaches miss when analyzing transactions in isolation. GraphStorm v0.5 helps simplify deployment of GNN real-time inference with one command for endpoint creation that beforehand required coordination of a number of companies and a standardized payload specification that helps simplify consumer integration with real-time inference companies. Organizations can now deploy enterprise-scale fraud prevention endpoints by way of streamlined instructions that cut back customized engineering from weeks to single-command operations.
To implement GNN-based fraud prevention with your personal knowledge:
- Overview the GraphStorm documentation for mannequin configuration choices and deployment specs.
- Adapt this IEEE-CIS instance to your fraud prevention dataset by modifying the graph building and have engineering steps utilizing the whole supply code and tutorials obtainable in our GitHub repository.
- Entry step-by-step implementation steerage to construct production-ready fraud prevention options with GraphStorm v0.5’s enhanced capabilities utilizing your enterprise knowledge.
In regards to the authors
 Jian Zhang is a Senior Utilized Scientist who has been utilizing machine studying methods to assist prospects remedy varied issues, equivalent to fraud detection, ornament picture era, and extra. He has efficiently developed graph-based machine studying, notably graph neural community, options for patrons in China, the US, and Singapore. As an enlightener of AWS graph capabilities, Zhang has given many public shows about GraphStorm, the GNN, the Deep Graph Library (DGL), Amazon Neptune, and different AWS companies.
Jian Zhang is a Senior Utilized Scientist who has been utilizing machine studying methods to assist prospects remedy varied issues, equivalent to fraud detection, ornament picture era, and extra. He has efficiently developed graph-based machine studying, notably graph neural community, options for patrons in China, the US, and Singapore. As an enlightener of AWS graph capabilities, Zhang has given many public shows about GraphStorm, the GNN, the Deep Graph Library (DGL), Amazon Neptune, and different AWS companies.
 Theodore Vasiloudis is a Senior Utilized Scientist at AWS, the place he works on distributed machine studying programs and algorithms. He led the event of GraphStorm Processing, the distributed graph processing library for GraphStorm and is a core developer for GraphStorm. He acquired his PhD in Laptop Science from KTH Royal Institute of Expertise, Stockholm, in 2019.
Theodore Vasiloudis is a Senior Utilized Scientist at AWS, the place he works on distributed machine studying programs and algorithms. He led the event of GraphStorm Processing, the distributed graph processing library for GraphStorm and is a core developer for GraphStorm. He acquired his PhD in Laptop Science from KTH Royal Institute of Expertise, Stockholm, in 2019.
 Xiang Music is a Senior Utilized Scientist at AWS AI Analysis and Schooling (AIRE), the place he develops deep studying frameworks together with GraphStorm, DGL, and DGL-KE. He led the event of Amazon Neptune ML, a brand new functionality of Neptune that makes use of graph neural networks for graphs saved in graph database. He’s now main the event of GraphStorm, an open supply graph machine studying framework for enterprise use circumstances. He acquired his PhD in pc programs and structure on the Fudan College, Shanghai, in 2014.
Xiang Music is a Senior Utilized Scientist at AWS AI Analysis and Schooling (AIRE), the place he develops deep studying frameworks together with GraphStorm, DGL, and DGL-KE. He led the event of Amazon Neptune ML, a brand new functionality of Neptune that makes use of graph neural networks for graphs saved in graph database. He’s now main the event of GraphStorm, an open supply graph machine studying framework for enterprise use circumstances. He acquired his PhD in pc programs and structure on the Fudan College, Shanghai, in 2014.
 Florian Saupe is a Principal Technical Product Supervisor at AWS AI/ML analysis supporting science groups just like the graph machine studying group, and ML Methods groups engaged on giant scale distributed coaching, inference, and fault resilience. Earlier than becoming a member of AWS, Florian lead technical product administration for automated driving at Bosch, was a technique guide at McKinsey & Firm, and labored as a management programs and robotics scientist—a discipline through which he holds a PhD.
Florian Saupe is a Principal Technical Product Supervisor at AWS AI/ML analysis supporting science groups just like the graph machine studying group, and ML Methods groups engaged on giant scale distributed coaching, inference, and fault resilience. Earlier than becoming a member of AWS, Florian lead technical product administration for automated driving at Bosch, was a technique guide at McKinsey & Firm, and labored as a management programs and robotics scientist—a discipline through which he holds a PhD.
 Ozan Eken is a Product Supervisor at AWS, captivated with constructing cutting-edge Generative AI and Graph Analytics merchandise. With a deal with simplifying complicated knowledge challenges, Ozan helps prospects unlock deeper insights and speed up innovation. Outdoors of labor, he enjoys attempting new meals, exploring completely different international locations, and watching soccer.
Ozan Eken is a Product Supervisor at AWS, captivated with constructing cutting-edge Generative AI and Graph Analytics merchandise. With a deal with simplifying complicated knowledge challenges, Ozan helps prospects unlock deeper insights and speed up innovation. Outdoors of labor, he enjoys attempting new meals, exploring completely different international locations, and watching soccer.