
EAGLE is the state-of-the-art technique for speculative decoding in giant language mannequin (LLM) inference, however its autoregressive drafting creates a hidden bottleneck: the extra tokens that you just speculate, the extra sequential ahead passes the drafter wants. Ultimately these overhead eats into your positive factors. P-EAGLE removes this ceiling by producing all Okay draft tokens in a single ahead cross, delivering as much as 1.69x speedup over vanilla EAGLE-3 on actual workloads on NVIDIA B200.
You possibly can unlock this efficiency achieve by downloading (or coaching) a parallel-capable drafter head, including “parallel_drafting”: true on you vLLM serving pipeline. Pre-trained P-EAGLE heads are already accessible on HuggingFace for GPT-OSS 120B, GPT-OSS 20B, and Qwen3-Coder 30B, so you can begin right now.
On this submit, we clarify how P-EAGLE works, how we built-in it into vLLM ranging from v0.16.0 (PR#32887), and tips on how to serve it with our pre-trained checkpoints. Right here is the checklist of artifacts used:
Determine 1: P-EAGLE over different strategies on SPEED-BENCH with Concurrency of 1 on one NVIDIA B200 card.
Fast begin P-EAGLE:
You possibly can allow parallel drafting with a single configuration change within the SpeculativeConfig class:
Right here’s an instance command in vLLM to allow parallel drafting with P-EAGLE as drafter:
EAGLE’s Drafting Bottleneck
EAGLE achieves 2–3× speedups over normal autoregressive decoding and is extensively deployed in manufacturing inference frameworks together with vLLM, SGLang, and TensorRT-LLM.EAGLE drafts tokens autoregressively. To provide Okay draft tokens, it requires Okay ahead passes by the draft mannequin. As drafter fashions get higher at drafting lengthy outputs, this drafting overhead turns into important—the drafter’s latency scales linearly with hypothesis depth, constraining how aggressively we are able to speculate.
Our Strategy: Parallel-EAGLE (P-EAGLE)
We current P-EAGLE, which transforms EAGLE from autoregressive to parallel draft technology. On B200 GPUs, P-EAGLE achieves 1.05×–1.69× speedup over vanilla EAGLE-3 on GPT-OSS 20B over MT-Bench, HumanEval, and SpeedBench. It’s now built-in into vLLM to unlock parallel speculative decoding, and able to speed up real-world deployments.
P-EAGLE generates the Okay draft tokens in a single ahead cross. Determine 2 exhibits the structure, which consists of two steps.
Step 1: Prefilling. The goal mannequin processes the immediate and generates a brand new token, as it will throughout regular inference. Alongside the best way, P-EAGLE captures the mannequin’s inner hidden states: h_prompt for every immediate place, and h_context for the newly generated token. These hidden states encode what the goal mannequin “is aware of” at every place and can information the drafter’s predictions. This step is an identical to autoregressive EAGLE.
Step 2: P-EAGLE Drafter. The drafter constructs inputs for every place in parallel. Every enter consists of a token embedding concatenated with a hidden state.
For immediate positions, the enter pairs every immediate token embedding emb(p) with its corresponding h_prompt from the goal mannequin. Following the identical conference as autoregressive EAGLE, positions are shifted by one. Place i receives the token and hidden state from place i-1, enabling it to foretell the token at place i.
For place 1, Subsequent-Token-Prediction (NTP), the enter pairs the newly generated token embedding emb(new) with h_context. This place operates identically to the usual autoregressive EAGLE.For positions 2 by Okay, Multi-Token-Prediction (MTP), the required inputs—the token embedding and hidden state—don’t but exist. P-EAGLE fills these with two learnable parameters: a shared masks token embedding emb(masks) and a shared hidden state h_shared. These are fastened vectors discovered throughout coaching that function impartial placeholders.
Positions cross collectively by N transformer layers, then by the language mannequin head to foretell draft tokens t1, t2, t3, and t4 in a single ahead cross.
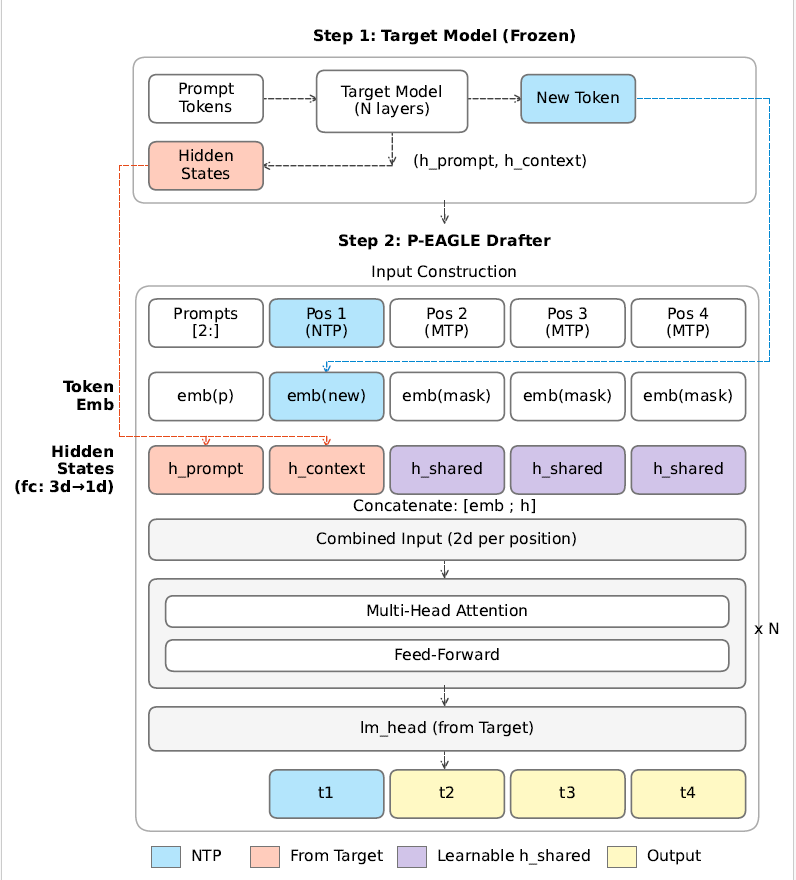
Determine 2: P-EAGLE structure overview.
Coaching P-EAGLE on Lengthy Sequences
Trendy reasoning fashions produce lengthy outputs. As proven in Determine 3, GPT-OSS 120B generates sequences (together with prompts) with a median size of three,891 tokens and P90 of 10,800 tokens on the UltraChat dataset. Draft fashions have to be skilled on matching context lengths to be efficient at inference.
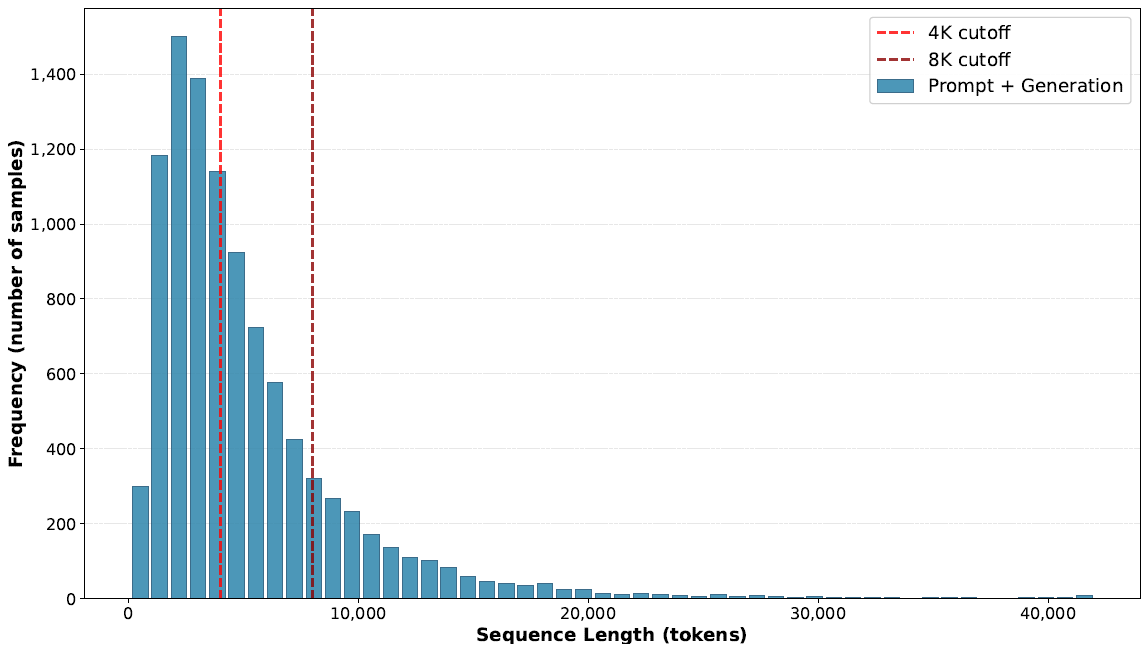
Determine 3: Sequence size (immediate + technology) distribution on UltraChat dataset with GPT-OSS 120B. Reasoning stage: Medium.
A key problem is that parallel drafting amplifies reminiscence necessities throughout coaching. Coaching Okay parallel teams on a sequence of size N creates N × Okay whole positions. With N = 8,192 and Okay = 8, a single coaching instance accommodates 65,536 positions. Consideration requires every place to attend to each legitimate place—65K × 65K means over 4 billion parts, consuming 8GB in bf16.
Place sampling [An et al., 2025] reduces reminiscence by randomly skipping positions, however skipping too aggressively degrades draft high quality. Gradient accumulation is the usual resolution for memory-constrained coaching, however it splits throughout totally different coaching examples. When a single sequence exceeds reminiscence, there’s nothing to separate.
P-EAGLE introduces a sequence partition algorithm for intra-sequence splitting. The algorithm divides the N × Okay place sequence into contiguous chunks, maintains appropriate consideration dependencies throughout chunk boundaries, and accumulates gradients throughout chunks of the identical sequence. For particulars, see the P-EAGLE paper.
Implementation in vLLM
Parallel drafting challenges
In lots of speculative decoding setups, drafting and verification share the identical per-request token format. That’s largely true for EAGLE: the drafter consumes a window that already matches what the verifier will examine; Okay drafted tokens and one extra sampled token.
Parallel drafting breaks that consistency. To foretell Okay tokens in a single drafter ahead cross, we append MASK placeholders (for instance, [token, MASK, MASK, …]). These further positions exist just for drafting, so the draft batch form not matches the verification batch form. As a result of we are able to’t reuse verification metadata, we should rebuild the batch metadata. We broaden the enter token IDs, hidden states, and positions to insert slots for masks tokens/embeddings, increment positions per request, then recompute the slot mapping and per-request begin indices from the up to date positions.
The Triton Kernel
To offset the overhead of rebuilding the batch metadata, we implement a fused Triton kernel that populates the drafter’s enter batch on-GPU by copying and increasing the target-model batch. In a single cross, the kernel copies the earlier token IDs and positions from the goal batch into new vacation spot slots and inserts the per-request bonus token sampled by the goal mannequin. It then fills the additional parallel-drafting slots with a particular MASK token ID. Lastly, it generates light-weight metadata: a rejected-token masks, a masked-token masks for parallel drafting slots, new-token indices for sampling draft tokens, and a hidden-state mapping.
This logic would in any other case be many GPU ops (copy/scatter + insert + fill + masks + remap). Fusing it into one kernel reduces launch overhead and additional reminiscence visitors, protecting the drafting setup low-cost.
Hidden State Administration
For EAGLE-based strategies that cross hidden states to the draft mannequin, parallel drafting handles populating these fields individually. Since hidden states are considerably bigger than the remainder of the enter batch, we cut up the work: the Triton kernel outputs a mapping, and a devoted copy kernel broadcasts the discovered hidden state placeholder into the masks token slots.
The parallel_drafting_hidden_state_tensor is loaded from the mannequin’s mask_hidden buffer, a discovered illustration that tells the mannequin these positions ought to predict future tokens.
For KV cache slot mapping, legitimate tokens obtain regular slot task whereas rejected tokens are mapped to PADDING_SLOT_ID (-1) to forestall spurious cache writes. For CUDA graphs, we prolong the seize vary by Okay × max_num_seqs to accommodate the bigger draft batch launched by parallel drafting.
vLLM Benchmarking on P-EAGLE
We practice P-EAGLE on GPT-OSS-20B and consider throughout three benchmarks: MT-Bench for multi-turn instruction following, SPEED-Bench Code for long-term code technology, and HumanEval for function-level code synthesis. P-EAGLE delivers 55–69% larger throughput at low concurrency (c=1), with positive factors of 5–25% sustained at excessive concurrency (c=64), in comparison with the publicly accessible vanilla EAGLE-3 checkpoint. Outcomes are proven in Determine 4-6.
The P-EAGLE drafter is a light-weight 4-layer mannequin skilled to foretell as much as 10 tokens in parallel. To guage efficiency, we sweep hypothesis depths Okay ∈ {3,5,7} throughout concurrency ranges C ∈ {1,2,4,8,16,32,64}. Our purpose is to establish the correct deployment configuration for each P-EAGLE and vanilla EAGLE-3. Linear drafting is used for each P-EAGLE and vanilla EAGLE-3. On this context, “finest P-EAGLE” and “finest EAGLE-3” discuss with the configurations that obtain peak throughput. These are measured in tokens per second (TPS), for a given hypothesis depth Okay. For every technique, we choose Okay that maximizes TPS underneath the given serving situations.
A constant sample emerges. P-EAGLE achieves peak TPS at Okay=7 throughout all concurrency ranges. In distinction, vanilla EAGLE-3 reaches its highest TPS at Okay=3, with its improved depth sometimes shifting towards larger values relying on concurrency. This conduct displays a basic benefit of parallel drafting. P-EAGLE generates all Okay draft tokens in a single ahead cross, permitting it to profit from deeper hypothesis with out incurring extra sequential overhead. Autoregressive drafters, against this, should generate speculative tokens step-by-step, which limits their means to effectively scale to bigger Okay.
All experiments are performed on one NVIDIA B200 (Blackwell) GPU utilizing vLLM with the next serving configuration.
Observe. Serving GPT-OSS-20B with EAGLE drafters at the moment requires a one-line vLLM patch (PR#36684). Apply it earlier than launching. This repair is anticipated to land in an upcoming vLLM launch.
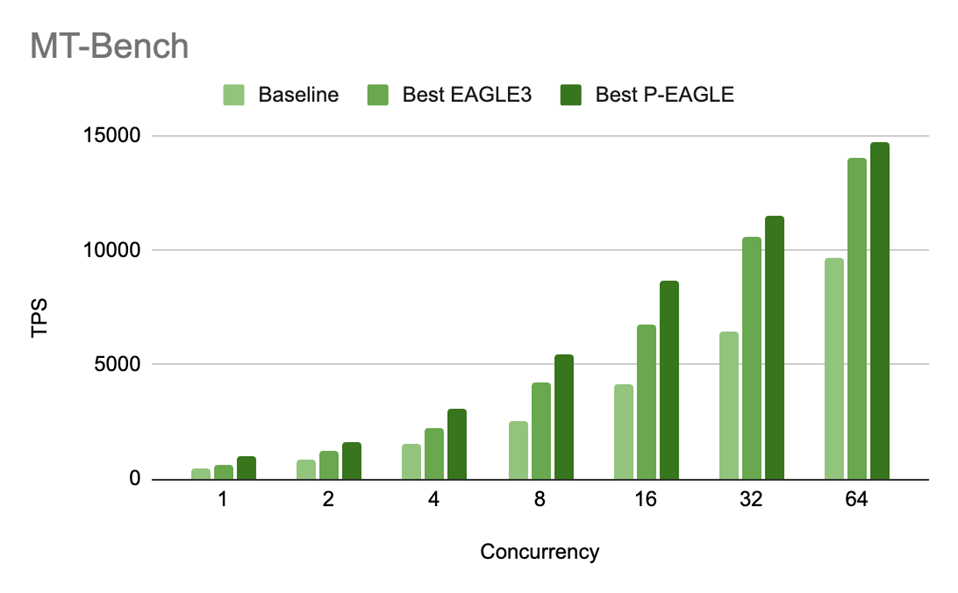
Determine 4: MT-Bench throughput (TPS) for P-EAGLE vs EAGLE-3 on GPT-OSS-20B throughout concurrency ranges. The P/E speedup ratios are: 1.55x (c=1), 1.29x (c=2), 1.35x (c=4), 1.28x (c=8), 1.27x (c=16), 1.09x (c=32), and 1.05x (c=64).
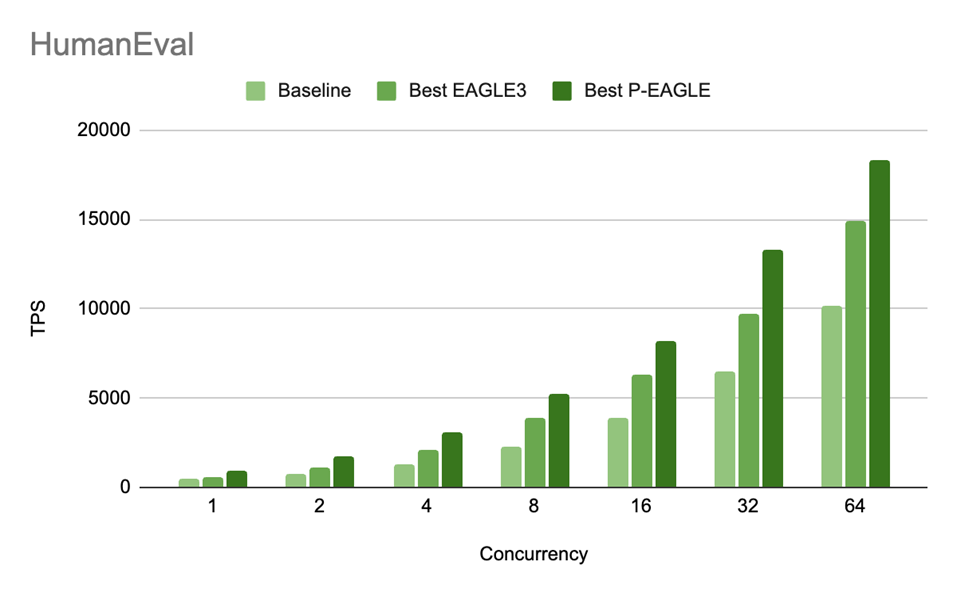
Determine 5: HumanEval throughput (TPS) for P-EAGLE vs EAGLE-3 on GPT-OSS-20B throughout concurrency ranges. The P/E speedup ratios are: 1.55x (c=1), 1.53x (c=2), 1.45x (c=4), 1.35x (c=8), 1.31x (c=16), 1.37x (c=32), and 1.23x (c=64).
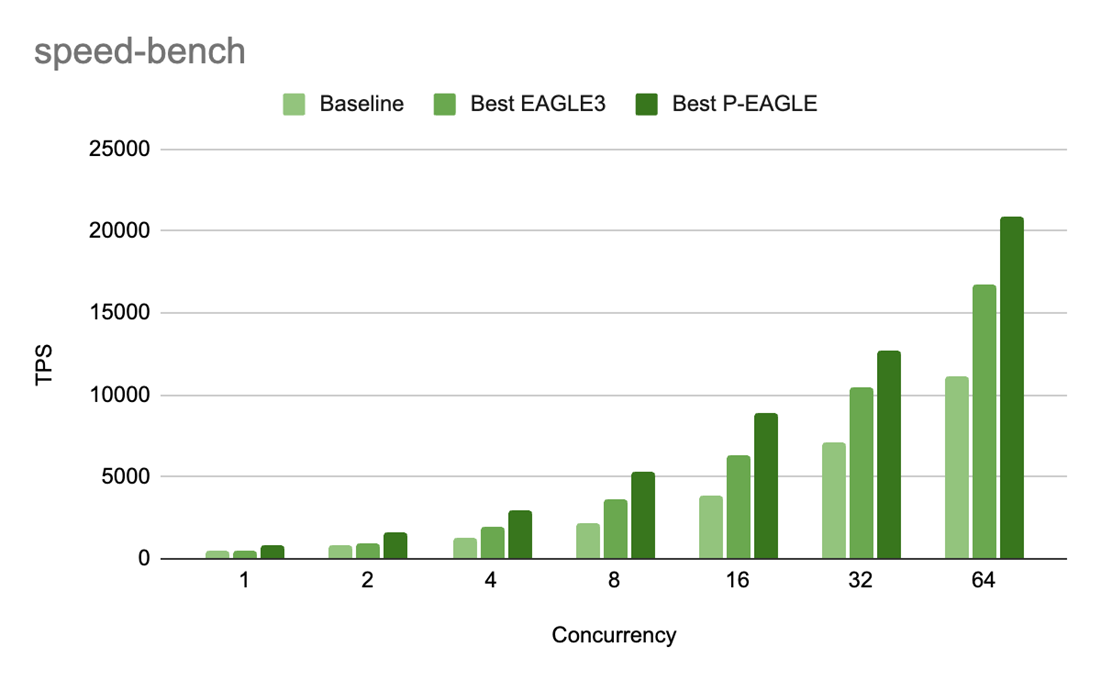
Determine 6: Pace-bench throughput (TPS) for P-EAGLE vs EAGLE-3 on GPT-OSS-20B throughout concurrency ranges. The P/E speedup ratios are: 1.69x (c=1), 1.61x (c=2), 1.54x (c=4), 1.45x (c=8), 1.40x (c=16), 1.22x (c=32), and 1.25x (c=64).
Along with decreasing drafting overhead, P-EAGLE’s throughput positive factors are additionally pushed by higher acceptance size (AL), the typical variety of draft tokens accepted by the verifier per hypothesis spherical. Larger AL means extra of the draft work turns into actual output, which immediately boosts efficient OTPS/TPS.
The next tables evaluate AL for P-EAGLE and vanilla EAGLE-3 on GPT-OSS-20B throughout our three benchmarks:
P-EAGLE (AL):
| Config | HumanEval | SPEED-Bench | MT-Bench |
| Okay=3 | 3.02 | 2.87 | 2.87 |
| Okay=7 | 3.94 | 3.38 | 3.70 |
EAGLE-3 (AL):
| Config | HumanEval | SPEED-Bench | MT-Bench |
| Okay=3 | 2.65 | 2.24 | 2.70 |
| Okay=7 | 3.03 | 2.59 | 3.27 |
P-EAGLE persistently achieves larger AL than EAGLE-3 on the similar hypothesis depth Okay. At Okay=7, P-EAGLE outperforms EAGLE-3 by 30% on HumanEval (3.94 vs 3.03), 31% on SPEED-Bench (3.38 vs 2.59), and 13% on MT-Bench (3.70 vs 3.27).Notably, P-EAGLE advantages extra from deeper hypothesis. From Okay=3 to Okay=7, P-EAGLE’s AL will increase by 0.92 on HumanEval (3.02 to three.94), whereas EAGLE-3 positive factors solely 0.38 (2.65 to three.03). This widening hole at larger Okay is in step with P-EAGLE’s single-pass parallel drafting, which incurs no extra value from deeper hypothesis.
Reproducing the Outcomes
After launching the server, run benchmarks with `vllm bench serve`:
P-EAGLE removes the sequential bottleneck from speculative decoding, delivering as much as 1.69× speedup over vanilla EAGLE-3 on actual workloads. By decoupling draft depend from ahead cross depend, we are able to now discover bigger drafting architectures, which may even allow elevated acceptance charges in comparison with single-layer baselines. This implementation fastidiously handles the complexities of enter preparation, consideration metadata administration, and KV cache slot mapping by hand-written fused kernels. Whereas it requires specifically skilled fashions, the efficiency advantages make it a beneficial addition to vLLM’s speculative decoding capabilities.
As extra parallel-trained fashions develop into accessible, we count on this method to develop into the popular selection for manufacturing LLM deployments. The mix of P-EAGLE’s architectural effectivity and vLLM’s strong infrastructure supplies a transparent path for these searching for most inference efficiency and lowered latency.
Strive it right now: obtain a pre-trained P-EAGLE head from HuggingFace, set "parallel_drafting": true in your vLLM config for any of the supported fashions, and see the speedup for your self.
Acknowledgement
We want to acknowledge our contributors and collaborators from Nvidia: Xin Li, Kaihang Jiang, Omri Almog, and our crew members: Ashish Khetan, and George Karypis.
In regards to the authors