
This publish is cowritten with Abdullahi Olaoye, Curtice Lockhart, Nirmal Kumar Juluru from NVIDIA.
We’re excited to announce that NVIDIA’s Nemotron 3 Nano is now out there as a totally managed and serverless mannequin in Amazon Bedrock. This follows our earlier announcement at AWS re:Invent supporting NVIDIA Nemotron 2 Nano 9B and NVIDIA Nemotron 2 Nano VL 12B fashions.
With NVIDIA Nemotron open fashions on Amazon Bedrock, you possibly can speed up innovation and ship tangible enterprise worth with out having to handle infrastructure complexities. You possibly can energy your generative AI functions with Nemotron’s capabilities via the inference capabilities of Amazon Bedrock and harness the good thing about its intensive options and tooling.
This publish explores the technical traits of the NVIDIA Nemotron 3 Nano mannequin and discusses potential software use instances. Moreover, it supplies technical steerage that will help you get began utilizing this mannequin on your generative AI functions throughout the Amazon Bedrock atmosphere.
About Nemotron 3 Nano
NVIDIA Nemotron 3 Nano is a small language mannequin (SLM) with a hybrid Combination-of-Specialists (MoE) structure that delivers excessive compute effectivity and accuracy that builders can use to construct specialised agentic AI techniques. The mannequin is absolutely open with open-weights, datasets, and recipes facilitating transparency and confidence for builders and enterprises. In comparison with different comparable sized fashions, Nemotron 3 Nano excels in coding and reasoning duties, taking the lead on benchmarks corresponding to SWE Bench Verified, AIME 2025, Area Laborious v2, and IFBench.
Mannequin overview:
- Structure:
- Combination-of-Specialists (MoE) with Hybrid Transformer-Mamba Structure
- Helps Token Funds for offering accuracy whereas avoiding overthinking
- Accuracy:
- Main accuracy on coding, scientific reasoning, math, software calling, instruction following, and chat
- Nemotron 3 Nano leads on benchmarks corresponding to SWE Bench, AIME 2025, Humanity Final Examination, IFBench, RULER, and Area Laborious (in comparison with different open language fashions with 30 billion or fewer MoE)
- Mannequin measurement: 30 B with 3 B energetic parameters
- Context size: 256K
- Mannequin enter: Textual content
- Mannequin output: Textual content
Nemotron 3 Nano combines Mamba, Transformer, and Combination-of-Specialists layers right into a single spine to assist steadiness effectivity, reasoning accuracy, and scale. Mamba permits long-range sequence modeling with low reminiscence overhead, whereas Transformer layers assist add exact consideration for structured reasoning duties like code, math, and planning. MoE routing additional boosts scalability by activating solely a subset of consultants per token, serving to to enhance latency and throughput. This makes Nemotron 3 Nano particularly well-suited for agent clusters operating many concurrent, light-weight workflows.
To study extra about Nemotron 3 Nano’s structure and the way it’s educated, see Inside NVIDIA Nemotron 3: Strategies, Instruments, and Information That Make It Environment friendly and Correct.
Mannequin benchmarks
The next picture exhibits that Nemotron 3 Nano leads in probably the most engaging quadrant in Synthetic Evaluation Openness Index vs. Intelligence Index. Why openness issues: It builds belief via transparency. Builders and enterprises can confidently construct on Nemotron with clear visibility into the mannequin, knowledge pipeline, and knowledge traits, enabling easy auditing and governance.
Title: Chart exhibiting Nemotron 3 Nano in probably the most engaging quadrant in Synthetic Evaluation Openness vs Intelligence Index (Supply: Synthetic Evaluation)
As proven within the following picture, Nemotron 3 Nano supplies main accuracy with the best effectivity among the many open fashions and scores a formidable 52 factors, a major bounce over the earlier Nemotron 2 Nano mannequin. Token demand is growing because of agentic AI, so the power to ‘assume quick’ (arrive on the appropriate reply shortly whereas utilizing fewer tokens) is important. Nemotron 3 Nano delivers excessive throughput with its environment friendly Hybrid Transformer-Mamba and MoE structure.
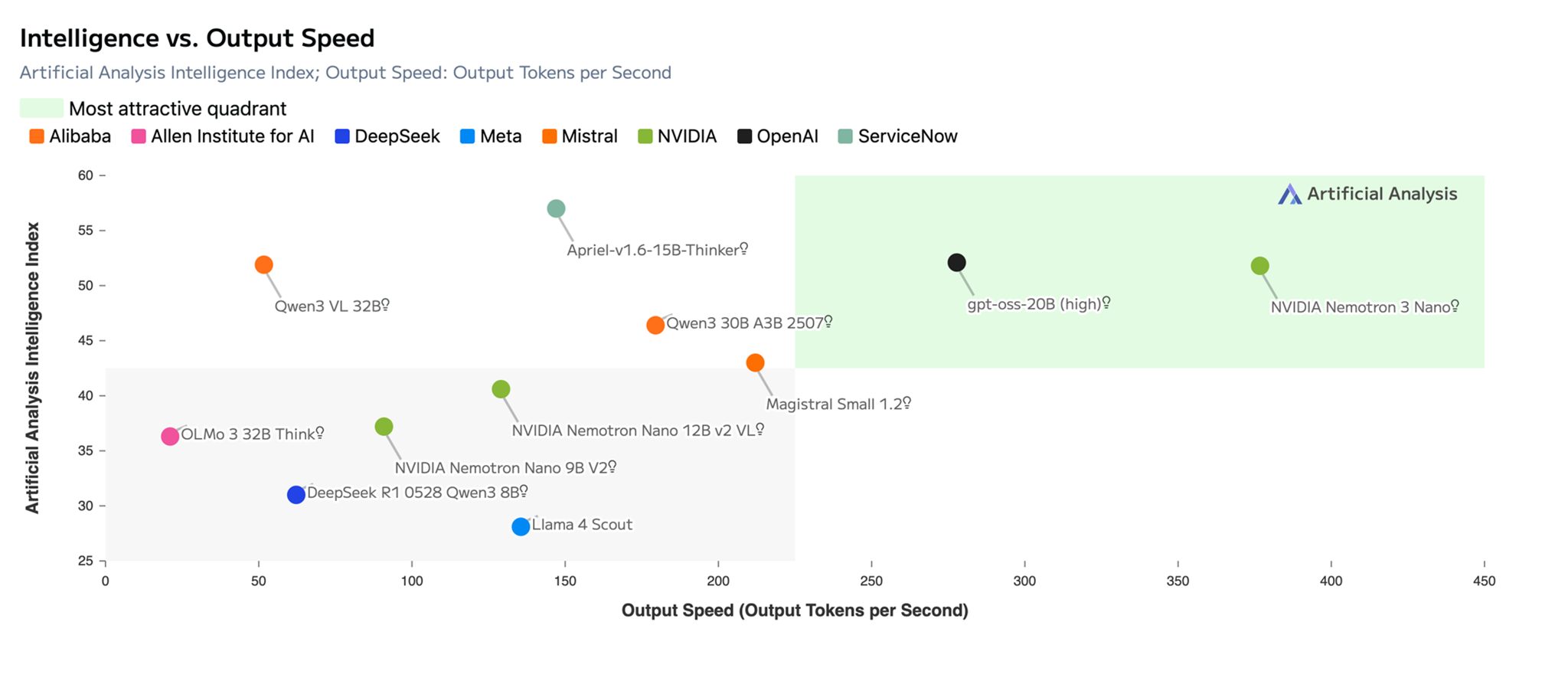
Title: NVIDIA Nemotron 3 Nano supplies highest effectivity with main accuracy amongst open fashions with a formidable 52 factors rating on Synthetic Evaluation Intelligence vs. Output Velocity Index. (Supply: Synthetic Evaluation)
NVIDIA Nemotron 3 Nano use instances
Nemotron 3 Nano helps energy numerous use instances for various industries. Among the use instances embody
- Finance – Speed up mortgage processing by extracting knowledge, analyzing earnings patterns, detecting fraudulent operations, decreasing cycle instances, and danger.
- Cybersecurity – Robotically triage vulnerabilities, carry out in-depth malware evaluation, and proactively hunt for safety threats.
- Software program improvement – Help with duties like code summarization.
- Retail – Optimize stock administration and assist improve in-store service with real-time, personalised product suggestions and assist.
Get began with NVIDIA Nemotron 3 Nano in Amazon Bedrock
To check NVIDIA Nemotron 3 Nano in Amazon Bedrock, full the next steps:
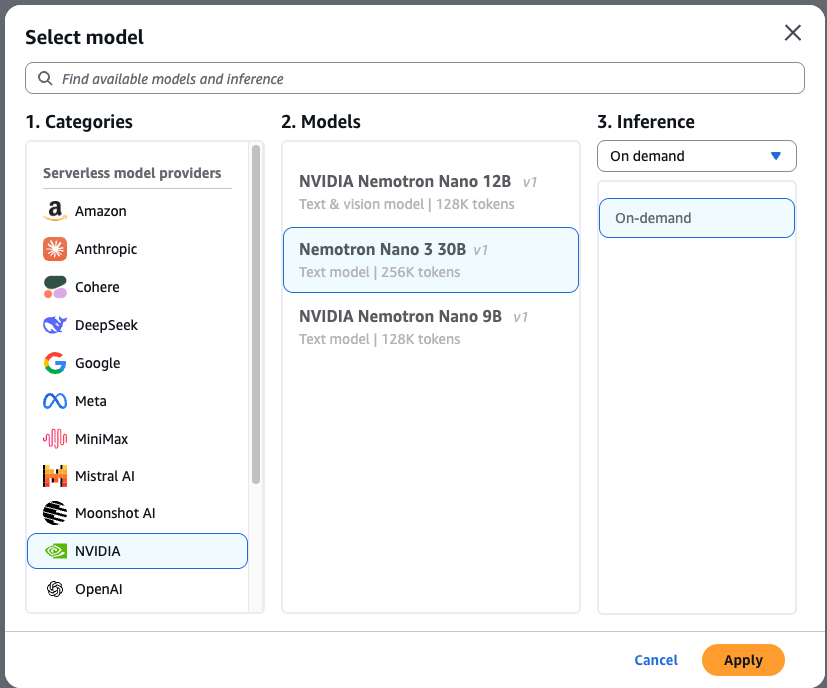
- Navigate to the Amazon Bedrock console and choose Chat/Textual content playground from the left menu (below the Take a look at part).
- Select Choose mannequin within the upper-left nook of the playground.
- Select NVIDIA from the class listing, then choose NVIDIA Nemotron 3 Nano.
- Select Apply to load the mannequin.
After choice, you possibly can check the mannequin instantly. Let’s use the next immediate to generate a unit check in Python code utilizing the pytest framework:
Write a pytest unit check suite for a Python operate referred to as calculate_mortgage(principal, fee, years). Embrace check instances for: 1) An ordinary 30-year fastened mortgage 2) An edge case with 0% curiosity 3) Error dealing with for unfavourable enter values.
Complicated duties like this immediate can profit from a sequence of thought method to assist produce a exact consequence based mostly on the reasoning capabilities constructed natively into the mannequin.
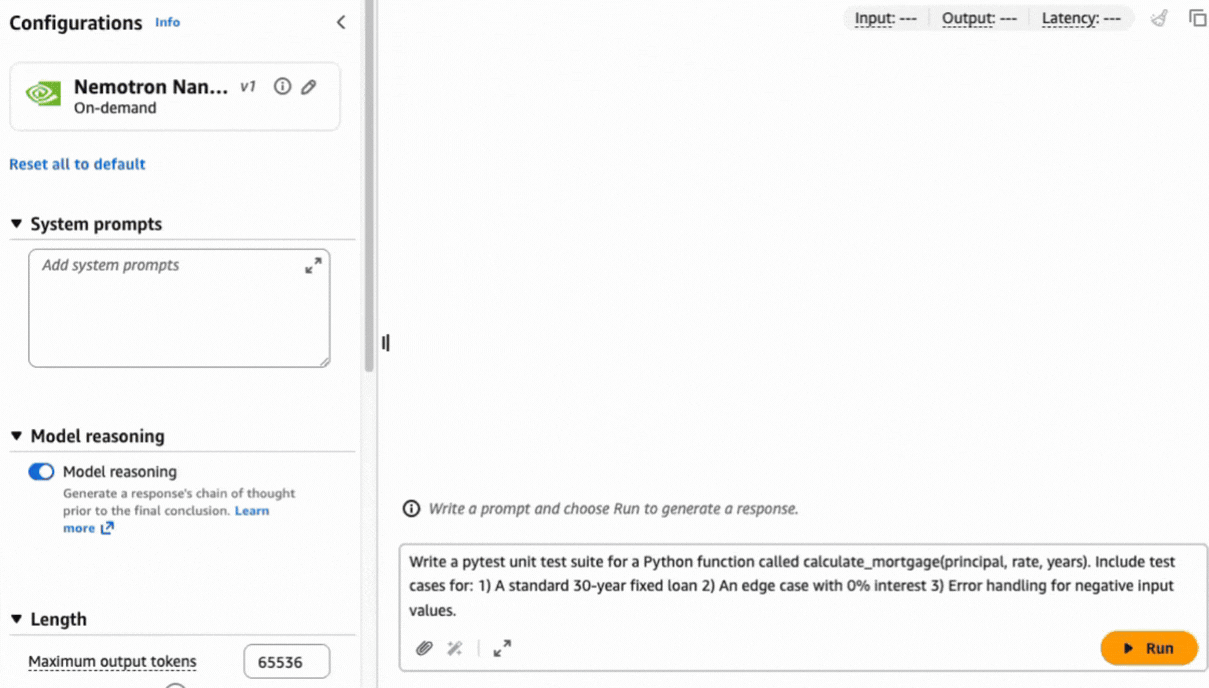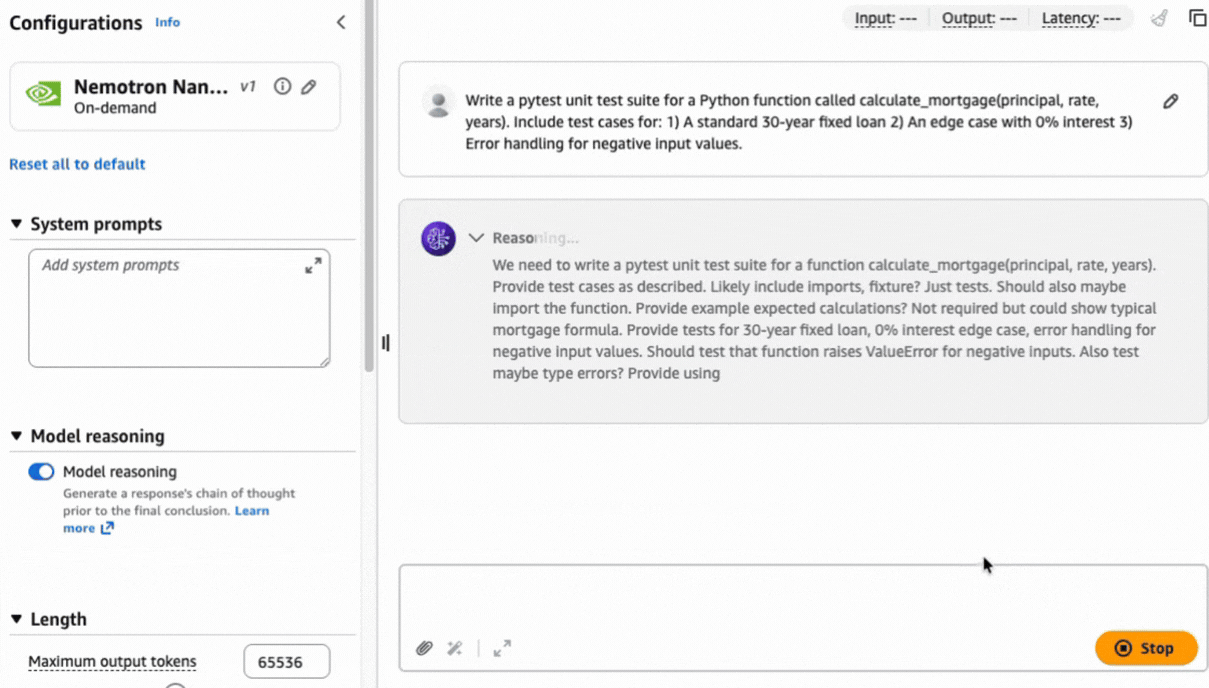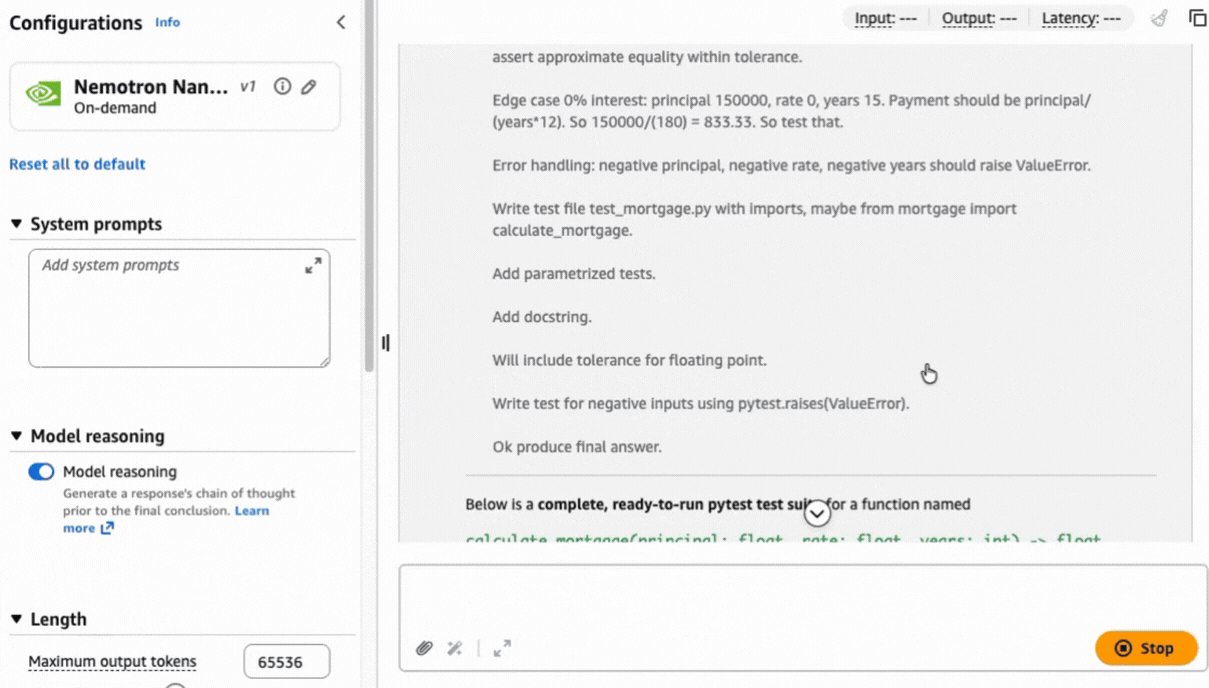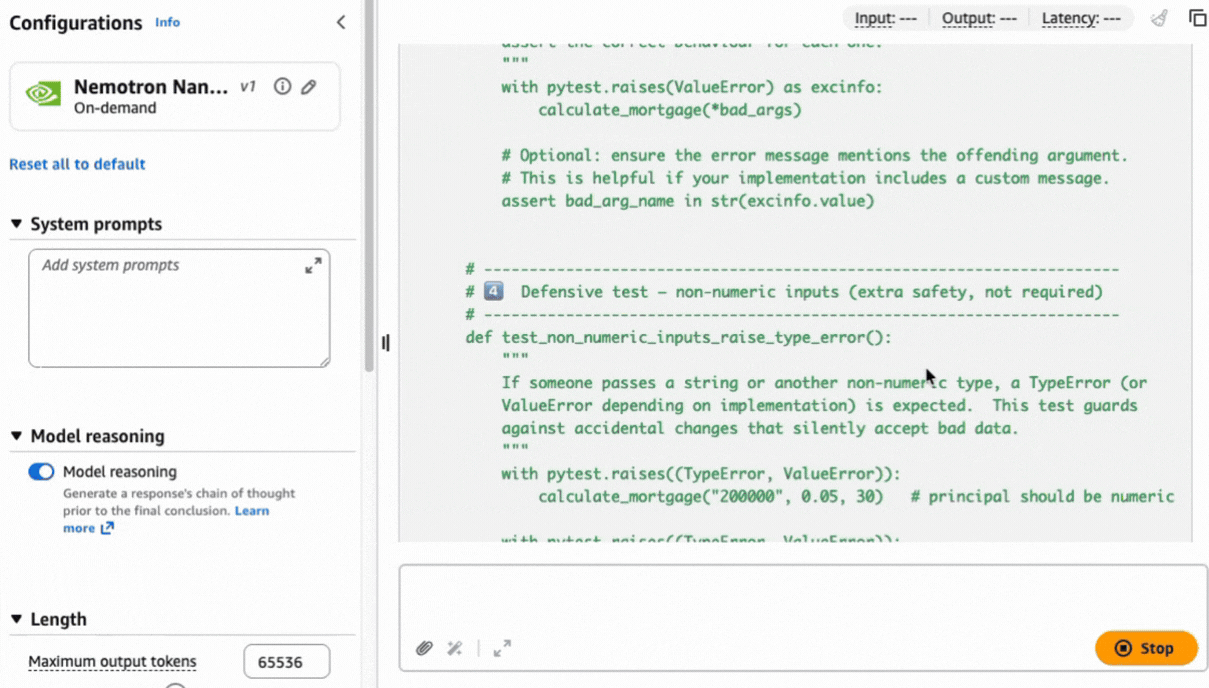
Utilizing the AWS CLI and SDKs
You possibly can entry the mannequin programmatically utilizing the mannequin ID nvidia.nemotron-nano-3-30b. The mannequin helps each the InvokeModel and Converse APIs via the AWS Command Line Interface (AWS CLI) and AWS SDK with nvidia.nemotron-nano-3-30b because the mannequin ID. Additional, it helps the Amazon Bedrock OpenAI SDK appropriate API.
Run the next command to invoke the mannequin straight out of your terminal utilizing the AWS Command Line Interface (AWS CLI) and the InvokeModel API:
To invoke the mannequin via the AWS SDK for Python (boto3), use the next script to ship a immediate to the mannequin, on this case by utilizing the Converse API:
To invoke the mannequin via the Amazon Bedrock OpenAI-compatible ChatCompletions endpoint, you are able to do so by utilizing the OpenAI SDK:
Use NVIDIA Nemotron 3 Nano with Amazon Bedrock options
You possibly can improve your generative AI functions by combining Nemotron 3 Nano with the Amazon Bedrock managed instruments. Use Amazon Bedrock Guardrails to implement safeguards and Amazon Data Bases to create sturdy Retrieval Augmented Era (RAG) workflows.
Amazon Bedrock guardrails
Guardrails is a managed security layer that helps implement accountable AI by filtering dangerous content material, redacting delicate info (PII), and blocking particular matters throughout prompts and responses. It really works throughout a number of fashions to assist detect immediate injection assaults and hallucinations.
Instance use case: In case you’re constructing a mortgage assistant, you possibly can assist stop it from providing basic funding recommendation. By configuring a filter for the phrase “shares”, person prompts containing that time period might be instantly blocked and obtain a customized message.
To arrange a guardrail, full the next steps:
- Within the Amazon Bedrock console, navigate to the Construct part on the left and choose Guardrails.
- Create a brand new guardrail and configure the required filters on your use case.
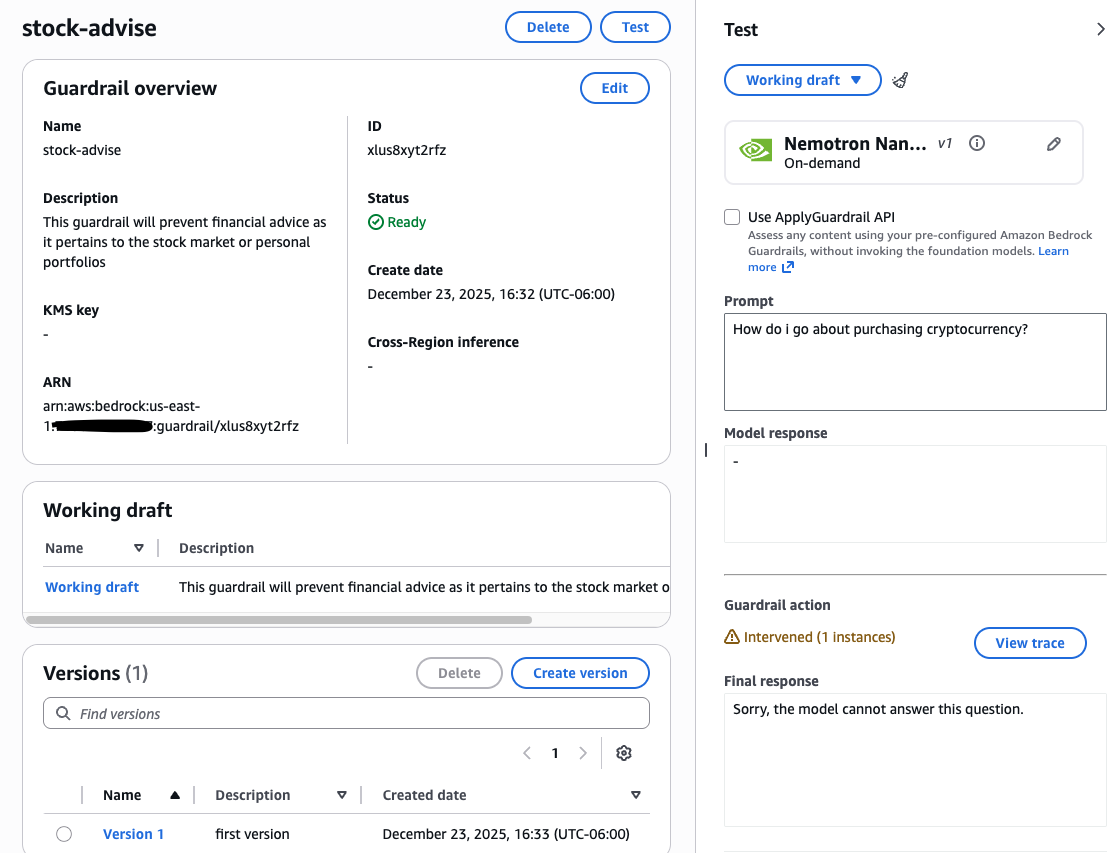
After configured, check the guardrail with numerous prompts to confirm its efficiency. You possibly can then fine-tune settings, corresponding to denied matters, phrase filters, and PII redaction, to match your particular security necessities. For a deep dive, see Create your guardrail.
Amazon Bedrock Data Bases
Amazon Bedrock Data Bases automates the whole RAG workflow. It handles ingesting content material out of your knowledge sources, chunking it into searchable segments, changing them into vector embeddings, and storing them in a vector database. Then, when a person submits a question, the system matches the enter towards saved vectors to seek out semantically comparable content material, which is then used to reinforce the immediate despatched to the muse mannequin.
For this instance, we uploaded PDFs (for instance, Shopping for a New House, House Mortgage Toolkit, Searching for a Mortgage) to Amazon Easy Storage Service (Amazon S3) and chosen Amazon OpenSearch Serverless because the vector retailer. The next code demonstrates the way to question this data base utilizing the RetrieveAndGenerate API, whereas robotically facilitating security compliance alignment via a particular Guardrail ID.
It directs the NVIDIA Nemotron 3 Nano mannequin to synthesize the retrieved paperwork into a transparent, grounded reply utilizing your customized immediate template. To arrange your personal pipeline, evaluation the total walkthrough within the Amazon Bedrock Person Information.
Conclusion
On this publish, we confirmed you the way to get began with NVIDIA Nemotron 3 Nano on Amazon Bedrock for absolutely managed serverless inference. We additionally confirmed you the way to use the mannequin with Amazon Bedrock Data Bases and Amazon Bedrock Guardrails. The mannequin is now out there within the US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Mumbai), South America (Sao Paulo), Europe (London), and Europe (Milan) AWS Areas. Verify the full Area listing for future updates. To study extra, take a look at NVIDIA Nemotron and provides NVIDIA Nemotron 3 Nano a attempt within the Amazon Bedrock console immediately.
Concerning the authors