
Evaluating single-turn agent interactions follows a sample that almost all groups perceive nicely. You present an enter, accumulate the output, and choose the outcome. Frameworks like Strands Analysis SDK make this course of systematic by evaluators that assess helpfulness, faithfulness, and device utilization. In a earlier weblog publish, we lined the way to construct complete analysis suites for AI brokers utilizing these capabilities. Nonetheless, manufacturing conversations hardly ever cease at one flip.
Actual customers interact in exchanges that unfold over a number of turns. They ask follow-up questions when solutions are incomplete, change course when new data surfaces, and specific frustration when their wants go unmet. A journey assistant that handles “Guide me a flight to Paris” nicely in isolation may battle when the identical person follows up with “Really, can we have a look at trains as an alternative?” or “What about accommodations close to the Eiffel Tower?” Testing these dynamic patterns requires greater than static take a look at circumstances with fastened inputs and anticipated outputs.
The core problem is scale as a result of you’ll be able to’t manually conduct tons of of multi-turn conversations each time your agent adjustments, and writing scripted dialog flows locks you into predetermined paths that miss how actual customers behave. What analysis groups want is a technique to generate lifelike, goal-driven customers programmatically and allow them to converse naturally with an agent throughout a number of turns. On this publish, we discover how ActorSimulator in Strands Evaluations SDK addresses this problem with structured person simulation that integrates into your analysis pipeline.
Why multi-turn analysis is basically more durable
Single-turn analysis has an easy construction. The enter is thought forward of time, the output is self-contained, and the analysis context is restricted to that single change. Multi-turn conversations break each considered one of these assumptions.
In a multi-turn interplay, every message relies on every little thing that got here earlier than it. The person’s second query is formed by how the agent answered the primary. A partial reply attracts a follow-up about no matter was neglected, a misunderstanding leads the person to restate their authentic request, and a shocking suggestion can ship the dialog in a brand new course.
These adaptive behaviors create dialog paths that may’t be predicted at test-design time. A static dataset of I/O pairs, irrespective of how giant, can’t seize this dynamic high quality as a result of the “right” subsequent person message relies on what the agent simply stated.
Guide testing covers this hole in principle however fails in apply. Testers can conduct lifelike multi-turn conversations, however doing so for each situation, throughout each persona kind, after each agent change isn’t sustainable. Because the agent’s capabilities develop, the variety of dialog paths grows combinatorially, nicely past what groups can discover manually.
Some groups flip to immediate engineering as a shortcut, asking a big language mannequin (LLM) to “act like a person” throughout testing. With out structured persona definitions and express purpose monitoring, these approaches produce inconsistent outcomes. The simulated person’s habits drifts between runs, making it tough to check evaluations over time or establish real regressions versus random variation. A structured method to person simulation can bridge this hole by combining the realism of human dialog with the repeatability and scale of automated testing.
What makes a very good simulated person
Simulation-based testing is nicely established in different engineering disciplines. Flight simulators take a look at pilot responses to eventualities that might be harmful or not possible to breed in the actual world. Sport engines use AI-driven brokers to discover thousands and thousands of participant habits paths earlier than launch. The identical precept applies to conversational AI. You create a managed setting the place lifelike actors work together along with your system beneath circumstances you outline, then measure the outcomes.
For AI agent analysis, a helpful simulated person begins with a constant persona. One which behaves like a technical skilled in a single flip and a confused novice within the subsequent produces unreliable analysis knowledge. Consistency means to keep up the identical communication type, experience degree, and character traits by each change, simply as an actual particular person would.
Equally necessary is goal-driven habits. Actual customers come to an agent with one thing they need to accomplish. They persist till they obtain it, modify their method when one thing isn’t working, and acknowledge when their purpose has been met. With out express objectives, a simulated person tends to both finish conversations too early or proceed asking questions indefinitely, neither of which displays actual utilization.
The simulated person should additionally reply adaptively to what the agent says, not comply with a predetermined script. When the agent asks a clarifying query, the actor ought to reply it in character. If the response is incomplete, the actor follows up on no matter was neglected fairly than transferring on. If the dialog drifts off matter, the actor steers it again towards the unique purpose. These adaptive behaviors make simulated conversations useful as analysis knowledge as a result of they train the identical dialog dynamics your agent faces in manufacturing.
Constructing persona consistency, purpose monitoring, and adaptive habits right into a simulation framework is what differentiates structured person simulation from ad-hoc prompting. ActorSimulator in Strands Evals is designed round precisely these rules.
How ActorSimulator works
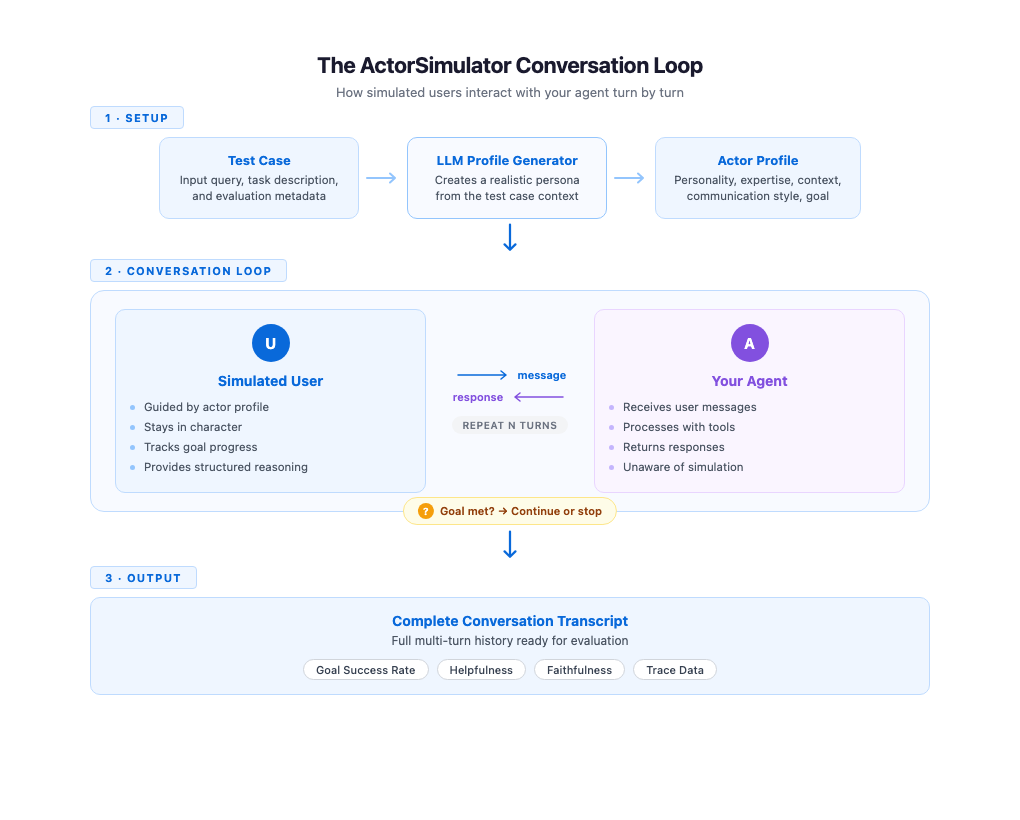
ActorSimulator implements these simulation qualities by a system that wraps a Strands Agent configured to behave as a sensible person persona. The method begins with profile technology. Given a take a look at case containing an enter question and an elective job description, ActorSimulator makes use of an LLM to create a whole actor profile. A take a look at case with enter “I need assistance reserving a flight to Paris” and job description “Full flight reserving beneath price range” may produce a budget-conscious traveler with beginner-level expertise and an informal communication type. Profile technology provides every simulated dialog a definite, constant character.
With the profile established, the simulator manages the dialog flip by flip. It maintains the total dialog historical past and generates every response in context, maintaining the simulated person’s habits aligned with their profile and objectives all through. When your agent addresses solely a part of the request, the simulated person naturally follows up on the gaps. A clarifying query out of your agent will get a response that stays in line with the persona. The dialog feels natural as a result of each response displays each the actor’s persona and every little thing stated thus far.
Objective monitoring runs alongside the dialog. ActorSimulator features a built-in purpose completion evaluation device that the simulated person can invoke to guage whether or not their authentic goal has been met. When the purpose is happy or the simulated person determines that the agent can’t full their request, the simulator emits a cease sign and the dialog ends. If the utmost flip rely is reached earlier than the purpose is met, the dialog additionally stops. This provides you a sign that the agent won’t be resolving person wants effectively. This mechanism makes certain conversations have a pure endpoint fairly than working indefinitely or slicing off arbitrarily.
Every response from the simulated person additionally contains structured reasoning alongside the message textual content. You possibly can examine why the simulated person selected to say what they stated, whether or not they had been following up on lacking data, expressing confusion, or redirecting the dialog. This transparency is efficacious throughout analysis improvement as a result of you’ll be able to see the reasoning behind every flip, making it extra easy to hint the place conversations succeed or go off observe.
Getting began with ActorSimulator
To get began, you will have to put in the Strands Analysis SDK utilizing: pip set up strands-agents-evals. For a step-by-step setup, you’ll be able to consult with our documentation or our earlier weblog for extra particulars. Placing these ideas into apply requires minimal code. You outline a take a look at case with an enter question and a job description that captures the person’s purpose. ActorSimulator handles profile technology, dialog administration, and purpose monitoring mechanically.
The next instance evaluates a journey assistant agent by a multi-turn simulated dialog.
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
# Outline your take a look at case
case = Case(
enter="I need to plan a visit to Tokyo with resort and actions",
metadata={"task_description": "Full journey package deal organized"}
)
# Create the agent you need to consider
agent = Agent(
system_prompt="You're a useful journey assistant.",
callback_handler=None
)
# Create person simulator from take a look at case
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=5
)
# Run the multi-turn dialog
user_message = case.enter
conversation_history = []
whereas user_sim.has_next():
# Agent responds to person
agent_response = agent(user_message)
agent_message = str(agent_response)
conversation_history.append({
"position": "assistant",
"content material": agent_message
})
# Simulator generates subsequent person message
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
conversation_history.append({
"position": "person",
"content material": user_message
})
print(f"Dialog accomplished in {len(conversation_history) // 2} turns")The dialog loop continues till has_next() returns False, which occurs when the simulated person’s objectives are met or simulated person determines that the agent can’t full the request or the utmost flip restrict is reached. The ensuing conversation_history comprises the total multi-turn transcript, prepared for analysis.
Integration with analysis pipelines

A standalone dialog loop is beneficial for fast experiments, however manufacturing analysis requires capturing traces and feeding them into your evaluator pipeline. The subsequent instance combines ActorSimulator with OpenTelemetry telemetry assortment and Strands Evals session mapping. The duty operate runs a simulated dialog and collects spans from every flip, then maps them right into a structured session for analysis.
from opentelemetry.sdk.hint.export import BatchSpanProcessor
from opentelemetry.sdk.hint.export.in_memory_span_exporter import InMemorySpanExporter
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
from strands_evals.evaluators import HelpfulnessEvaluator
from strands_evals.telemetry import StrandsEvalsTelemetry
from strands_evals.mappers import StrandsInMemorySessionMapper
# Setup telemetry for capturing agent traces
telemetry = StrandsEvalsTelemetry()
memory_exporter = InMemorySpanExporter()
span_processor = BatchSpanProcessor(memory_exporter)
telemetry.tracer_provider.add_span_processor(span_processor)
def evaluation_task(case: Case) -> dict:
# Create simulator
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=3
)
# Create agent
agent = Agent(
system_prompt="You're a useful journey assistant.",
callback_handler=None
)
# Accumulate spans throughout dialog
all_target_spans = []
user_message = case.enter
whereas user_sim.has_next():
memory_exporter.clear()
agent_response = agent(user_message)
agent_message = str(agent_response)
# Seize telemetry
turn_spans = listing(memory_exporter.get_finished_spans())
all_target_spans.prolong(turn_spans)
# Generate subsequent person message
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
# Map to session for analysis
mapper = StrandsInMemorySessionMapper()
session = mapper.map_to_session(
all_target_spans,
session_id="test-session"
)
return {"output": agent_message, "trajectory": session}
# Create analysis dataset
test_cases = [
Case(
name="booking-simple",
input="I need to book a flight to Paris next week",
metadata={
"category": "booking",
"task_description": "Flight booking confirmed"
}
)
]
evaluator = HelpfulnessEvaluator()
dataset = Experiment(circumstances=test_cases, evaluator=evaluator)
# Run evaluations
report = Experiment.run_evaluations(evaluation_task)
report.run_display()
This method captures full traces of your agent’s habits throughout dialog turns. The spans embrace device calls, mannequin invocations, and timing data for each flip within the simulated dialog. By mapping these spans right into a structured session, you make the total multi-turn interplay obtainable to evaluators like GoalSuccessRateEvaluator and HelpfulnessEvaluator, which may then assess the dialog as a complete, fairly than remoted turns.
Customized actor profiles for focused testing
Automated profile technology covers most analysis eventualities nicely, however some testing objectives require particular personas. You may need to confirm that your agent handles an impatient skilled person otherwise from a affected person newbie, or that it responds appropriately to a person with domain-specific wants. For these circumstances, ActorSimulator accepts a totally outlined actor profile that you just management.
from strands_evals.varieties.simulation import ActorProfile
from strands_evals import ActorSimulator
from strands_evals.simulation.prompt_templates.actor_system_prompt import (
DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE
)
# Outline a customized actor profile
actor_profile = ActorProfile(
traits={
"character": "analytical and detail-oriented",
"communication_style": "direct and technical",
"expertise_level": "skilled",
"patience_level": "low"
},
context="Skilled enterprise traveler with elite standing who values effectivity",
actor_goal="Guide enterprise class flight with particular seat preferences and lounge entry"
)
# Initialize simulator with customized profile
user_sim = ActorSimulator(
actor_profile=actor_profile,
initial_query="I must ebook a enterprise class flight to London subsequent Tuesday",
system_prompt_template=DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE,
max_turns=10
)
By defining traits like endurance degree, communication type, and experience, you’ll be able to systematically take a look at how your agent performs throughout completely different person segments. An agent that scores nicely with affected person, non-technical customers however poorly with impatient specialists reveals a particular high quality hole you could deal with. Working the identical purpose throughout a number of persona configurations turns person simulation right into a device for understanding your agent’s strengths and weaknesses by person kind.
Finest practices for simulation-based analysis
These greatest practices assist you to get probably the most out of simulation-based analysis:
- Set
max_turnsprimarily based on job complexity, utilizing 3-5 for targeted duties and 8-10 for multi-step workflows. If most conversations attain the restrict with out finishing the purpose, enhance it. - Write particular job descriptions that the simulator can consider in opposition to. “Assist the person ebook a flight” is simply too imprecise to guage completion reliably, whereas “flight reserving confirmed with dates, vacation spot, and worth” provides a concrete goal.
- Use auto-generated profiles for broad protection throughout person varieties and customized profiles to breed particular patterns out of your manufacturing logs, resembling an impatient skilled or a first-time person.
- Give attention to patterns throughout your take a look at suite fairly than particular person transcripts. Constant redirects from the simulated person means that the agent is drifting off matter, and declining purpose completion charges after an agent change factors to a regression.
- Begin with a small set of take a look at circumstances protecting your commonest eventualities and increase to edge circumstances and extra personas as your analysis apply matures.
Conclusion
We confirmed how ActorSimulator in Strands Evals permits systematic, multi-turn analysis of conversational AI brokers by lifelike person simulation. Somewhat than counting on static take a look at circumstances that seize solely single exchanges, you’ll be able to outline objectives and personas and let simulated customers work together along with your agent throughout pure, adaptive conversations. The ensuing transcripts feed instantly into the identical analysis pipeline that you just use for single-turn testing, providing you with helpfulness scores, purpose success charges, and detailed traces throughout each dialog flip.
To get began, discover the working examples within the Strands Brokers samples repository. For groups evaluating brokers deployed by Amazon Bedrock AgentCore, the next AgentCore evaluations pattern exhibit the way to simulate interactions with deployed brokers. Begin with a handful of take a look at circumstances representing your commonest person eventualities, run them by ActorSimulator, and consider the outcomes. As your analysis apply matures, increase to cowl extra personas, edge circumstances, and dialog patterns.
Concerning the authors