
In the advantages administration {industry}, claims processing is an important operational pillar that makes certain workers and beneficiaries obtain well timed advantages, corresponding to well being, dental, or incapacity funds, whereas controlling prices and adhering to rules like HIPAA and ERISA. Companies goal to optimize the workflow—overlaying declare submission, validation, adjudication, cost, and appeals—to reinforce worker satisfaction, strengthen supplier relationships, and mitigate monetary dangers. The method consists of particular steps like declare submission (by means of portals or paper), knowledge validation (verifying eligibility and accuracy), adjudication (assessing protection in opposition to plan guidelines), cost or denial (together with test processing for reimbursements), and enchantment dealing with. Environment friendly claims processing helps aggressive advantages choices, which is essential for expertise retention and employer branding, however requires balancing pace, accuracy, and price in a extremely regulated atmosphere.
Regardless of its significance, claims processing faces vital challenges in lots of organizations. Most notably, the reliance on legacy programs and handbook processes ends in frustratingly gradual decision instances, excessive error charges, and elevated administrative prices. Incomplete or inaccurate declare submissions—corresponding to these with lacking prognosis codes or eligibility mismatches—often result in denials and rework, creating frustration for each workers and healthcare suppliers. Moreover, fraud, waste, and abuse proceed to inflate prices, but detecting these points with out delaying reputable claims stays difficult. Advanced regulatory necessities demand fixed system updates, and poor integration between programs—corresponding to Human Useful resource Info Techniques (HRIS) and different downstream programs—severely limits scalability. These points drive up operational bills, erode belief in advantages packages, and overburden customer support groups, significantly throughout appeals processes or peak claims intervals.
Generative AI may help tackle these challenges. With Amazon Bedrock Information Automation, you may automate era of helpful insights from unstructured multimodal content material corresponding to paperwork, photos, audio, and video. Amazon Bedrock Information Automation can be utilized in advantages claims course of to automate doc processing by extracting and classifying paperwork from claims packets, coverage functions, and supporting paperwork with industry-leading accuracy, lowering handbook errors and accelerating decision instances. Amazon Bedrock Information Automation pure language processing capabilities interpret unstructured knowledge, corresponding to supplier notes, supporting compliance with plan guidelines and rules. By automating repetitive duties and offering insights, Amazon Bedrock Information Automation helps cut back administrative burdens, improve experiences for each workers and suppliers, and help compliance in an economical method. Moreover, its scalable structure allows seamless integration with current programs, bettering knowledge move throughout HRIS, claims programs, and supplier networks, and superior analytics assist detect fraud patterns to optimize price management.
On this put up, we look at the standard profit claims processing workflow and determine the place generative AI-powered automation can ship the best influence.
Profit claims processing
When an worker or beneficiary pays out of pocket for an expense coated below their well being advantages, they submit a declare for reimbursement. This course of requires a number of supporting paperwork, together with physician’s prescriptions and proof of cost, which could embody test photos, receipts, or digital cost confirmations.
The claims processing workflow entails a number of essential steps:
- Doc consumption and processing – The system receives and categorizes submitted documentation, together with:
- Medical information and prescriptions
- Proof of cost documentation
- Supporting varieties and eligibility verification
- Cost verification processing – For check-based reimbursements, the system should full the next steps:
- Extract data from test photos, together with the account quantity and routing quantity contained within the MICR line
- Confirm payee and payer names in opposition to the data offered in the course of the declare submission course of
- Verify cost quantities match the claimed bills
- Flag discrepancies for human evaluation
- Adjudication and reimbursement – When verification is full, the system performs a number of actions:
- Decide eligibility primarily based on plan guidelines and protection limits
- Calculate acceptable reimbursement quantities
- Provoke cost processing by means of direct deposit or test issuance
- Present notification to the claimant relating to the standing of their reimbursement
On this put up, we stroll by means of a real-world situation to make the complexity of this multi-step course of clearer. The next instance demonstrates how Amazon Bedrock Information Automation can streamline the claims processing workflow, from preliminary submission to last reimbursement.
Answer overview
Let’s think about a situation the place a profit plan participant seeks therapy and pays out of pocket for the physician’s charge utilizing a test. They then purchase the drugs prescribed by the physician on the pharmacy retailer. Later, they log in to their profit supplier’s portal and submit a declare together with the picture of the test and cost receipt for the drugs.
This answer makes use of Amazon Bedrock Information Automation to automate the 2 most crucial and time-consuming features of this workflow: doc consumption and cost verification processing. The next diagram illustrates the advantages claims processing structure.
The top-to-end course of works by means of 4 built-in levels: ingestion, extraction, validation, and integration.
Ingestion
When a beneficiary uploads supporting paperwork (test picture and pharmacy receipt) by means of the corporate’s profit claims portal, these paperwork are securely saved in an Amazon Easy Storage Service (Amazon S3) bucket, triggering the automated claims processing pipeline.
Extraction
After paperwork are ingested, the system instantly begins with clever knowledge extraction:
- The S3 object add triggers an AWS Lambda perform, which invokes the Amazon Bedrock Information Automation challenge.
- Amazon Bedrock Information Automation makes use of blueprints for file processing and extraction. Blueprints are artifacts used to configure file processing enterprise logic by specifying an inventory of discipline names for knowledge extraction, together with their desired knowledge codecs (string, quantity, or Boolean) and pure language context for knowledge normalization and validation guidelines. Amazon Bedrock Information Automation supplies a catalog of pattern blueprints out of the field. You’ll be able to create a customized blueprint on your distinctive doc varieties that aren’t predefined within the catalog. This answer makes use of two blueprints designed for various doc varieties, as proven within the following screenshot:
- The catalog blueprint
US-Financial institution-Examinefor test processing. - The customized blueprint
benefit-claims-pharmacy-receipt-blueprintfor pharmacy-specific receipts.
- The catalog blueprint
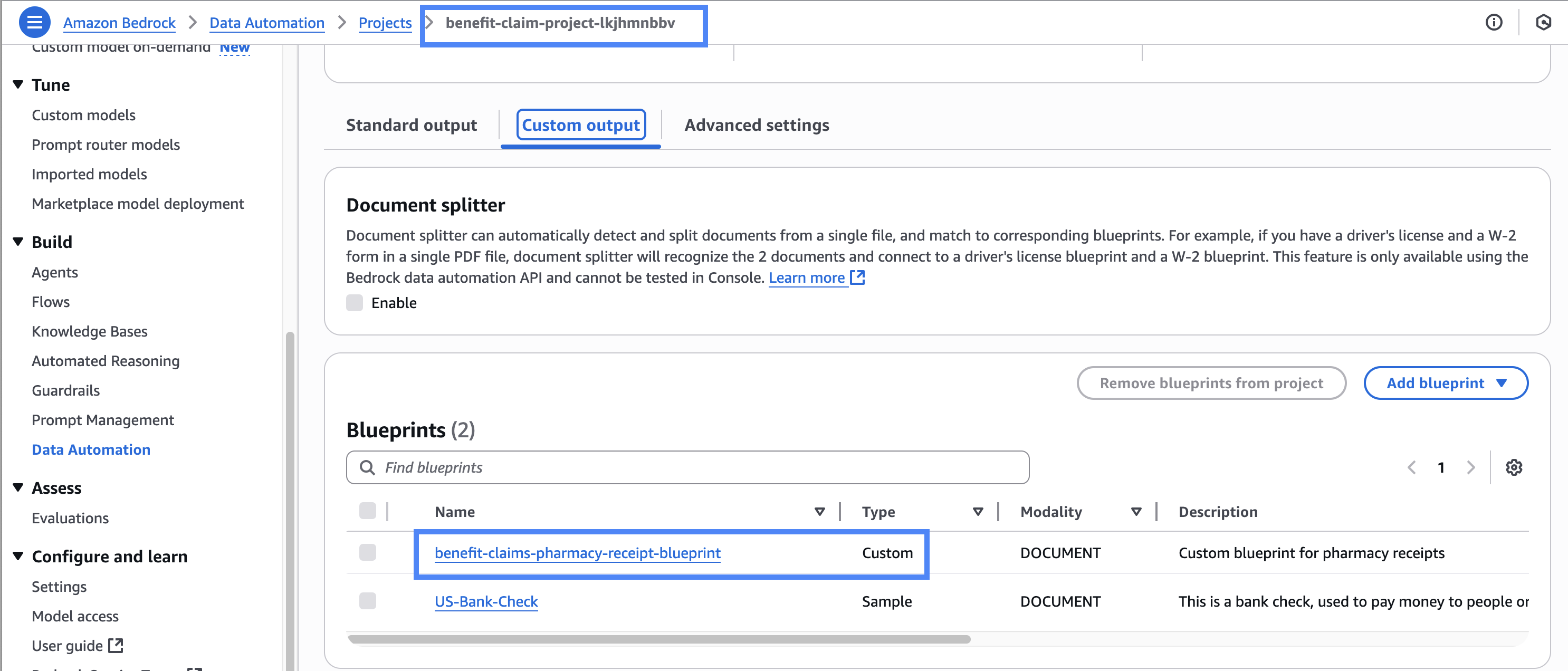
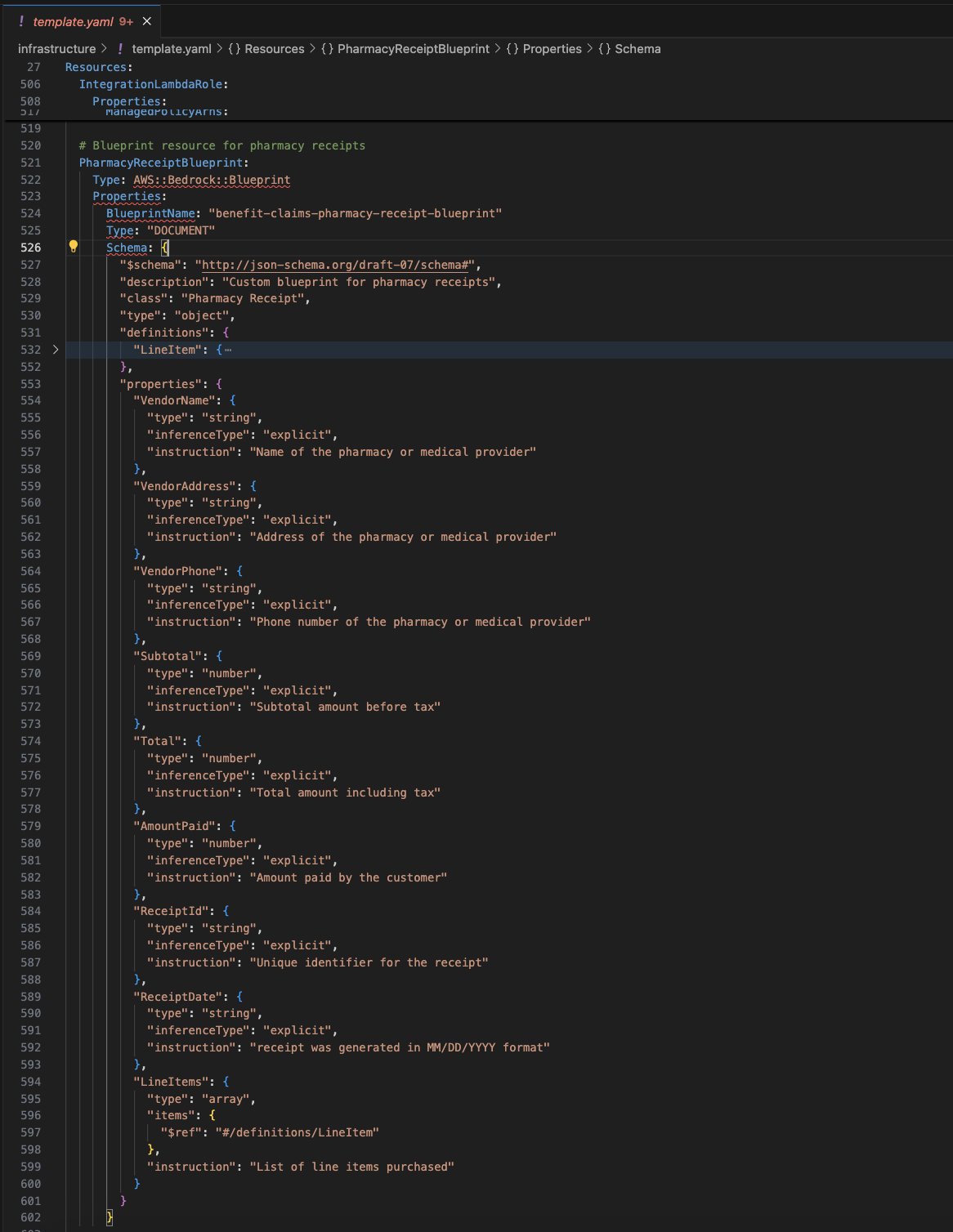
US-Financial institution-Examine is a catalog blueprint offered out of the field by Amazon Bedrock Information Automation. The customized blueprint benefit-claims-pharmacy-receipt-blueprint is created utilizing an AWS CloudFormation template to deal with pharmacy receipt processing, addressing a selected doc kind that wasn’t obtainable in the usual blueprint catalog. The profit administrator desires to search for vendor-specific data corresponding to identify, tackle, and cellphone particulars for advantages claims processing. The customized blueprint schema comprises pure language clarification of these fields, corresponding to VendorName, VendorAddress, VendorPhone, and extra fields, explaining what the sphere represents, anticipated knowledge varieties, and inference kind for every extracted discipline (defined in Creating Blueprints for Extraction), as proven within the following screenshot.
3. The 2 blueprints are added to the Amazon Bedrock Information Automation challenge. An Amazon Bedrock Information Automation challenge is a grouping of each customary and customized blueprints that you need to use to course of several types of recordsdata (like paperwork, audio, and pictures) utilizing particular configuration settings, the place you may management what sort of data you wish to extract from every file kind. When the challenge is invoked asynchronously, it robotically applies the suitable blueprint, extracts data corresponding to confidence scores and bounding field particulars for every discipline, and saves ends in a separate S3 bucket. This clever classification alleviates the necessity so that you can write advanced doc classification logic.
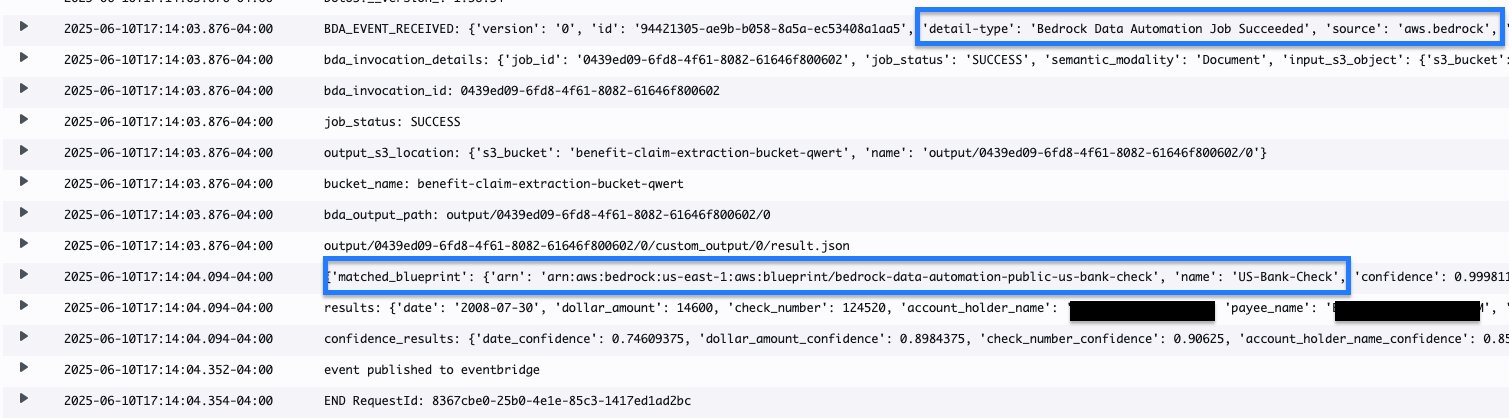
The next screenshot illustrates the doc classification by the usual catalog blueprint US-Financial institution-Examine.
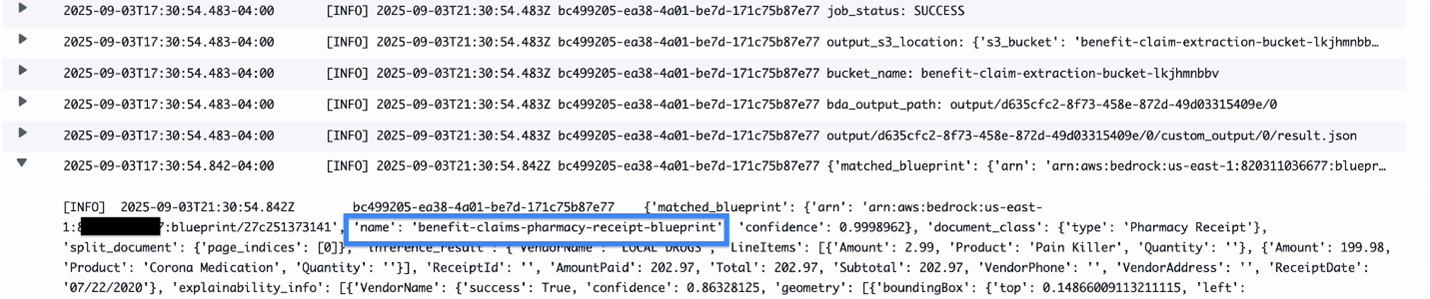
The next screenshot reveals the doc classification by the customized blueprint benefit-claims-pharmacy-receipt-blueprint.
Validation
With the information extracted, the system strikes to the validation and decision-making course of utilizing the enterprise guidelines particular to every doc kind.
The enterprise guidelines are documented in customary working process paperwork (AnyCompany Profit Checks Commonplace Working process.docx and AnyCompany Profit Claims Commonplace Working process.docx) and uploaded to an S3 bucket. Then the system creates a data base for Amazon Bedrock with the S3 bucket because the supply, as proven within the following screenshot.
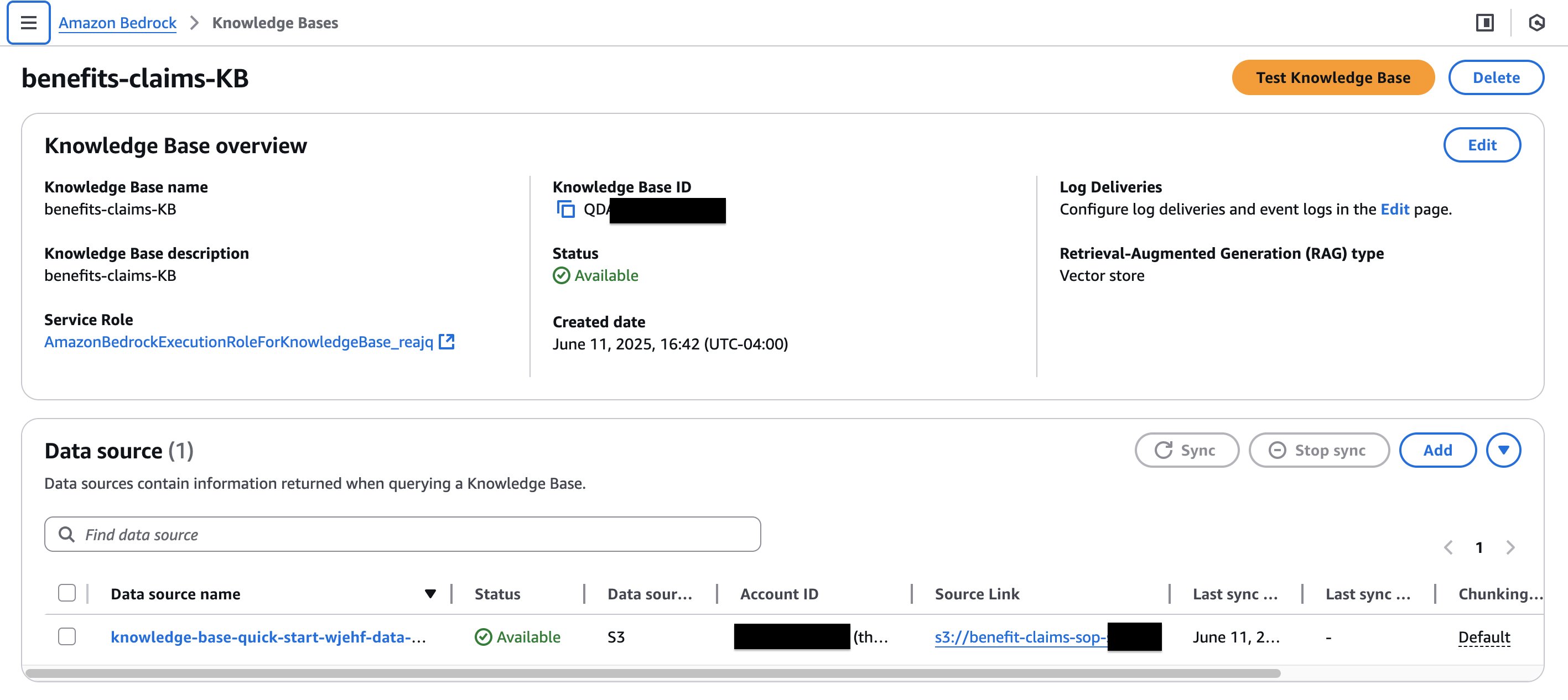
When the extracted Amazon Bedrock Information Automation outcomes are saved to the configured S3 bucket, a Lambda perform is triggered robotically. Primarily based on the enterprise guidelines retrieved from the data base for the precise doc kind and the extracted Amazon Bedrock Information Automation output, an Amazon Nova Lite giant langue mannequin (LLM) makes the automated approve/deny determination for claims.
The next screenshot reveals the profit declare adjudication automated determination for US-Financial institution-Examine.
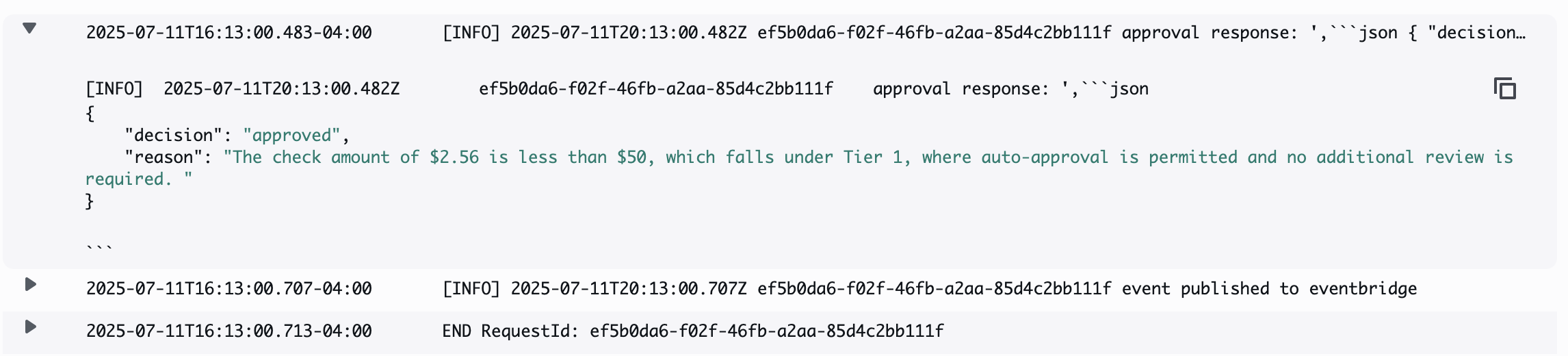
The next screenshot reveals the profit declare adjudication automated determination for benefit-claims-pharmacy-receipt-blueprint.

Integration
The system seamlessly integrates with current enterprise processes.
When validation is full, an occasion is pushed to Amazon EventBridge, which triggers a Lambda perform for downstream integration. On this implementation, we use an Amazon DynamoDB desk and Amazon Easy Notification Service (Amazon SNS) electronic mail for downstream integration. A DynamoDB desk is created as a part of the deployment stack, which is used to populate particulars together with doc classification, extracted knowledge, and automatic determination. An electronic mail notification is shipped for each test and receipts after the ultimate determination is made by the system. The next screenshot reveals an instance electronic mail for pharmacy receipt approval.
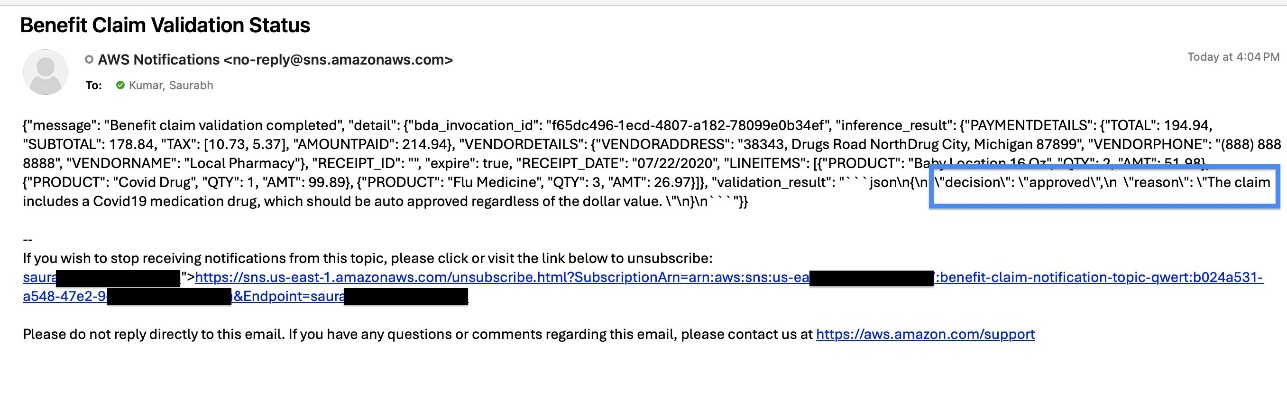
This versatile structure helps you combine together with your current functions by means of inside APIs or occasions to replace declare standing or set off extra workflows when validation fails.
Lowering handbook effort by means of clever enterprise guidelines administration
Past automating doc processing, this answer addresses a typical operational problem: Historically, prospects should write and keep code for dealing with enterprise guidelines round claims adjudication and processing. Each enterprise rule change requires growth effort and code updates, slowing time-to-market and rising upkeep overhead.
Our strategy converts enterprise guidelines and customary working procedures (SOPs) into data bases utilizing Amazon Bedrock Data Bases, which you need to use for automated decision-making. This strategy can dramatically cut back time-to-market when enterprise guidelines change, as a result of updates will be made by means of data administration fairly than code deployment.
Within the following sections, we stroll you thru the steps to deploy the answer to your individual AWS account.
Stipulations
To implement the answer offered on this put up, you will need to have the next:
This answer makes use of Python 3.13 with Boto3 1.38. or later model, and the AWS Serverless Utility Mannequin Command Line Interface (AWS SAM CLI) model 1.138.0. We assume that you’ve put in these in your native machine already. If not, consult with the next directions:
Arrange code in your native machine
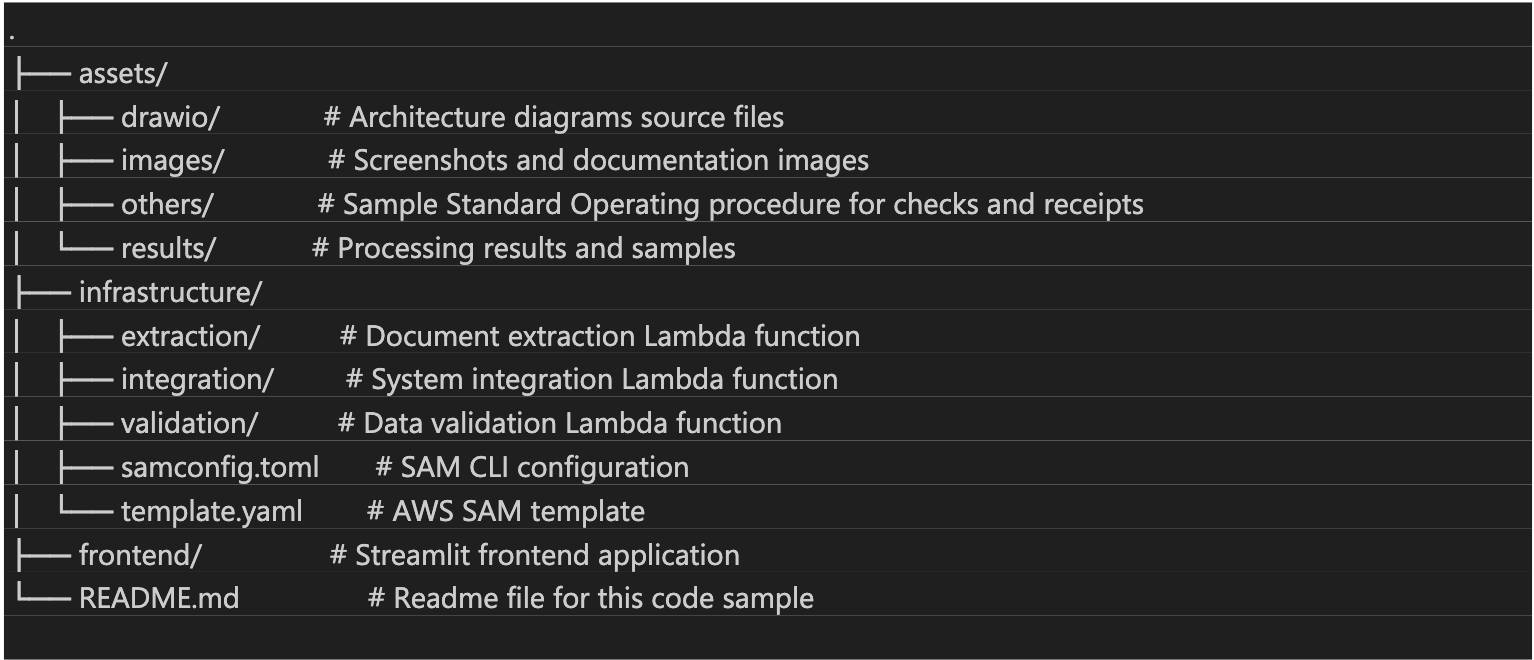
To arrange the code, clone the GitHub repository. After you could have cloned the repository to your native machine, the challenge folder construction will appear to be the next code, as talked about within the README file:
Deploy the answer in your account
The pattern code comes with a CloudFormation template that creates mandatory assets. To deploy the answer in your account, comply with the deployment directions within the README file.
Clear up
Deploying this answer in your account will incur prices. Observe the cleanup directions within the README file to keep away from costs if you end up completed.
Conclusion
Advantages administration firms can considerably improve their operations by automating claims processing utilizing the answer outlined on this put up. This strategic strategy straight addresses the {industry}’s core challenges and might ship a number of key benefits:
- Enhanced processing effectivity by means of accelerated claims decision instances, decreased handbook error charges, and better straight-through processing charges that decrease the irritating delays and handbook rework plaguing legacy programs
- Streamlined doc integration and fraud detection capabilities, the place including new supporting paperwork turns into seamless by means of new Amazon Bedrock Information Automation blueprints, whereas AI-powered analytics determine suspicious patterns with out delaying reputable claims, avoiding conventional months-long growth cycles and lowering pricey fraud, waste, and abuse
- Agile enterprise rule administration that allows fast adaptation to altering HIPAA and ERISA necessities and modification of enterprise guidelines, considerably lowering administrative prices and time-to-market whereas bettering scalability and integration with current HRIS and claims, in the end enhancing worker satisfaction, strengthening supplier relationships, and supporting aggressive advantages choices which might be essential for expertise retention and employer branding
To get began with this answer, consult with the GitHub repo. For extra details about Amazon Bedrock Information Automation, consult with Remodel unstructured knowledge into significant insights utilizing Amazon Bedrock Information Automation and take a look at the Doc Processing Utilizing Amazon Bedrock Information Automation workshop.
Concerning the authors
 Saurabh Kumar is a Senior Options Architect at AWS primarily based out of Raleigh, NC, with experience in Resilience Engineering, Chaos Engineering, and Generative AI options. He advises prospects on fault-tolerance methods and generative AI-driven modernization approaches, serving to organizations construct strong architectures whereas leveraging generative AI applied sciences to drive innovation.
Saurabh Kumar is a Senior Options Architect at AWS primarily based out of Raleigh, NC, with experience in Resilience Engineering, Chaos Engineering, and Generative AI options. He advises prospects on fault-tolerance methods and generative AI-driven modernization approaches, serving to organizations construct strong architectures whereas leveraging generative AI applied sciences to drive innovation.
 Kiran Lakkireddy is a Principal Options Architect at AWS with experience in Monetary Providers, Advantages Administration and HR Providers industries. Kiran supplies expertise and structure steering to prospects of their enterprise transformation, with a specialised give attention to GenAI safety, compliance, and governance. He usually speaks to buyer safety management on GenAI safety, compliance, and governance subjects, serving to organizations navigate the advanced panorama of AI implementation whereas sustaining strong safety requirements.
Kiran Lakkireddy is a Principal Options Architect at AWS with experience in Monetary Providers, Advantages Administration and HR Providers industries. Kiran supplies expertise and structure steering to prospects of their enterprise transformation, with a specialised give attention to GenAI safety, compliance, and governance. He usually speaks to buyer safety management on GenAI safety, compliance, and governance subjects, serving to organizations navigate the advanced panorama of AI implementation whereas sustaining strong safety requirements.
 Tamilmanam Sambasivam is a Options Architect and AI/ML Specialist at AWS. She helps enterprise prospects to unravel their enterprise issues by recommending the proper AWS options. Her sturdy again floor in Info Know-how (24+ years of expertise) helps prospects to strategize, develop and modernize their enterprise issues in AWS cloud. Within the spare time, Tamil wish to journey and gardening.
Tamilmanam Sambasivam is a Options Architect and AI/ML Specialist at AWS. She helps enterprise prospects to unravel their enterprise issues by recommending the proper AWS options. Her sturdy again floor in Info Know-how (24+ years of expertise) helps prospects to strategize, develop and modernize their enterprise issues in AWS cloud. Within the spare time, Tamil wish to journey and gardening.