
On daily basis, organizations course of hundreds of thousands of paperwork, together with invoices, contracts, insurance coverage claims, medical data, and monetary statements. Regardless of the essential function these paperwork play, an estimated 80–90% of the info they include is unstructured and largely untapped, hiding useful insights that would rework enterprise outcomes. Regardless of advances in know-how, many organizations nonetheless depend on handbook knowledge entry, spending numerous hours extracting data from PDFs, scanned pictures, and types. This handbook method is time-consuming, error-prone, and prevents organizations from scaling their operations and responding rapidly to enterprise calls for.
Though generative AI has made it simpler to construct proof-of-concept doc processing options, the journey from proof of idea to manufacturing stays fraught with challenges. Organizations typically discover themselves rebuilding from scratch after they uncover their prototype can’t deal with manufacturing volumes, lacks correct error dealing with, doesn’t scale cost-effectively, or fails to satisfy enterprise safety and compliance necessities. What works in a demo with a handful of paperwork typically breaks down when processing 1000’s of paperwork every day in a manufacturing surroundings.
On this submit, we introduce our open supply GenAI IDP Accelerator—a examined answer that we use to assist clients throughout industries deal with their doc processing challenges. Automated doc processing workflows precisely extract structured data from paperwork, lowering handbook effort. We’ll present you the way this ready-to-deploy answer may also help you construct these workflows with generative AI on AWS in days as an alternative of months.
Understanding clever doc processing
Clever doc processing (IDP) encompasses the applied sciences and methods used to extract and course of knowledge from varied doc sorts. Frequent IDP duties embrace:
- OCR (Optical Character Recognition) – Changing scanned paperwork and pictures into machine-readable textual content
- Doc classification – Robotically figuring out doc sorts (similar to invoices, contracts, or types)
- Knowledge extraction – Pulling structured data from unstructured paperwork
- Evaluation – Evaluating the standard and confidence of extracted knowledge
- Summarization – Creating concise summaries of doc content material
- Analysis – Measuring accuracy and efficiency in opposition to anticipated outcomes
These capabilities are essential throughout industries. In monetary providers, organizations use IDP to course of mortgage functions, extract knowledge from financial institution statements, and validate insurance coverage claims. Healthcare suppliers depend on IDP to extract affected person data from medical data, course of insurance coverage types, and deal with lab outcomes effectively. Manufacturing and logistics firms use IDP to course of invoices and buy orders, extract transport data, and deal with high quality certificates. Authorities companies use IDP to course of citizen functions, extract knowledge from tax types, handle permits and licenses, and implement regulatory compliance.
The generative AI revolution in IDP
Conventional IDP options relied on template-based extraction, common expressions, and classical machine studying (ML) fashions. Although practical, these approaches required intensive setup, struggled with doc variations, and achieved restricted accuracy on complicated paperwork.
The emergence of huge language fashions (LLMs) and generative AI has basically remodeled IDP capabilities. Trendy AI fashions can perceive doc context, deal with variations with out templates, obtain near-human accuracy on complicated extractions, and adapt to new doc sorts with minimal examples. This shift from rule-based to intelligence-based processing means organizations can now course of totally different doc sorts with excessive accuracy, dramatically lowering the time and value of implementation.
GenAI IDP Accelerator
We’re excited to share the GenAI IDP Accelerator—an open supply answer that transforms how organizations deal with doc processing by dramatically lowering handbook effort and bettering accuracy. This serverless basis provides processing patterns which use Amazon Bedrock Knowledge Automation for wealthy out-of-the-box doc processing options, excessive accuracy, ease of use, and easy per-page pricing, Amazon Bedrock state-of-the-art basis fashions (FMs) for complicated paperwork requiring customized logic, and different AWS AI providers to supply a versatile, scalable start line for enterprises to construct doc automation tailor-made to their particular wants.
The next is a brief demo of the answer in motion, on this case showcasing the default Amazon Bedrock Knowledge Automation processing sample.
Actual-world affect
The GenAI IDP Accelerator is already reworking doc processing for organizations throughout industries.
Competiscan: Reworking advertising intelligence at scale
Competiscan, a pacesetter in aggressive advertising intelligence, confronted an enormous problem: processing 35,000–45,000 advertising campaigns every day whereas sustaining a searchable archive of 45 million campaigns spanning 15 years.
Utilizing the GenAI IDP Accelerator, Competiscan achieved the next:
- 85% classification and extraction accuracy throughout numerous advertising supplies
- Elevated scalability to deal with 35,000–45,000 every day campaigns
- Removing of essential bottlenecks, facilitating enterprise progress
- Manufacturing deployment in simply 8 weeks from preliminary idea
Ricoh: Scaling doc processing
Ricoh, a world chief in doc administration, carried out the GenAI IDP Accelerator to remodel healthcare doc processing for his or her purchasers. Processing over 10,000 healthcare paperwork month-to-month with potential to scale to 70,000, they wanted an answer that would deal with complicated medical documentation with excessive accuracy.
The outcomes communicate for themselves:
- Financial savings potential of over 1,900 person-hours yearly by automation
- Achieved extraction accuracy to assist reduce monetary penalties from processing errors
- Automated classification of grievances vs. appeals
- Created a reusable framework deployable throughout a number of healthcare clients
- Built-in with human-in-the-loop overview for instances requiring knowledgeable validation
- Leveraged modular structure to combine with current programs, enabling customized doc splitting and large-scale doc processing
Resolution overview
The GenAI IDP Accelerator is a modular, serverless answer that routinely converts unstructured paperwork into structured, actionable knowledge. Constructed solely on AWS providers, it offers enterprise-grade scalability, safety, and cost-effectiveness whereas requiring minimal setup and upkeep. Its configuration-driven design helps groups rapidly adapt prompts, extraction templates, and validation guidelines for his or her particular doc sorts with out touching the underlying infrastructure.
The answer follows a modular pipeline that enriches paperwork at every stage, from OCR to classification, to extraction, to evaluation, to summarization, and ending with analysis.
You possibly can deploy and customise every step independently, so you’ll be able to optimize in your particular use instances whereas sustaining the advantages of the built-in workflow.
The next diagram illustrates the answer structure, displaying the default Bedrock Knowledge Automation workflow (Sample-1).
Seek advice from the GitHub repo for added particulars and processing patterns.
Among the key options of the answer embrace:
- Serverless structure – Constructed on AWS Lambda, AWS Step Features, and different serverless applied sciences for queueing, concurrency administration, and retries to supply automated scaling and pay-per-use pricing for manufacturing workloads of many sizes
- Generative AI-powered doc packet splitting and classification – Clever doc classification utilizing Amazon Bedrock Knowledge Automation or Amazon Bedrock multimodal FMs, together with help for multi-document packets and packet splitting
- Superior AI key data extraction – Key data extraction utilizing Amazon Bedrock Knowledge Automation or Amazon Bedrock multimodal FMs
- A number of processing patterns – Select from pre-built patterns optimized for various workloads with totally different configurability, value, and accuracy necessities, or lengthen the answer with extra patterns:
- Sample 1 – Makes use of Amazon Bedrock Knowledge Automation, a completely managed service that gives wealthy out-of-the-box options, ease of use, and easy per-page pricing. This sample is beneficial for many use instances.
- Sample 2 – Makes use of Amazon Textract and Amazon Bedrock with Amazon Nova, Anthropic’s Claude, or customized fine-tuned Amazon Nova fashions. This sample is right for complicated paperwork requiring customized logic.
- Sample 3 – Makes use of Amazon Textract, Amazon SageMaker with a fine-tuned mannequin for classification, and Amazon Bedrock for extraction. This sample is right for paperwork requiring specialised classification.
We count on so as to add extra sample choices to deal with extra real-world doc processing wants, and to benefit from ever-improving state-of-the-art capabilities:
- Few-shot studying – Enhance accuracy for classification and extraction by offering few-shot examples to information the AI fashions
- Confidence evaluation – AI-powered high quality assurance that evaluates extraction subject confidence, used to point paperwork for human overview
- Human-in-the-loop (HITL) overview – Built-in workflow for human overview of low-confidence extractions utilizing Amazon SageMaker Augmented AI (Amazon A2I), at the moment accessible for Sample 1, with help for Patterns 2 and three coming quickly
- Net person interface – Responsive internet UI for monitoring doc processing, viewing outcomes, and managing configurations
- Information base integration – Question processed paperwork utilizing pure language by Amazon Bedrock Information Bases
- Constructed-in analysis – Framework to consider and enhance accuracy in opposition to baseline knowledge
- Analytics and reporting database – Centralized analytics database for monitoring processing metrics, accuracy developments, and value optimization throughout doc workflows, and for analyzing extracted doc content material utilizing Amazon Athena
- No-code configuration – Customise doc sorts, extraction fields, and processing logic by configuration, editable within the internet UI
- Developer-friendly python bundle – For knowledge science and engineering groups who wish to experiment, optimize, or combine the IDP capabilities straight into their workflows, the answer’s core logic is on the market by the idp_common Python bundle
Stipulations
Earlier than you deploy the answer, be sure you have an AWS account with administrator permissions and entry to Amazon and Anthropic fashions on Amazon Bedrock. For extra particulars, see Entry Amazon Bedrock basis fashions.
Deploy the GenAI IDP Accelerator
To deploy the GenAI IDP Accelerator, you should use the offered AWS CloudFormation template. For extra particulars, see the fast begin choice on the GitHub repo. The high-level steps are as follows:
- Log in to your AWS account.
- Select Launch Stack in your most popular AWS Area:
| Area | Launch Stack |
|---|---|
| US East (N. Virginia) | |
| US West (Oregon) |
- Enter your e mail deal with and select your processing sample (default is Sample 1, utilizing Amazon Bedrock Knowledge Automation).
- Use defaults for all different configuration parameters.
- Deploy the stack.
The stack takes roughly 15–20 minutes to deploy the assets. After deployment, you’ll obtain an e mail with login credentials for the online interface.
Course of paperwork
After you deploy the answer, you can begin processing paperwork:
- Use the online interface to add a pattern doc (you should use the offered pattern: lending_package.pdf).
In manufacturing, you usually automate loading your paperwork on to the Amazon Easy Storage Service (Amazon S3) enter bucket, routinely triggering processing. To study extra, see Testing with out the UI.
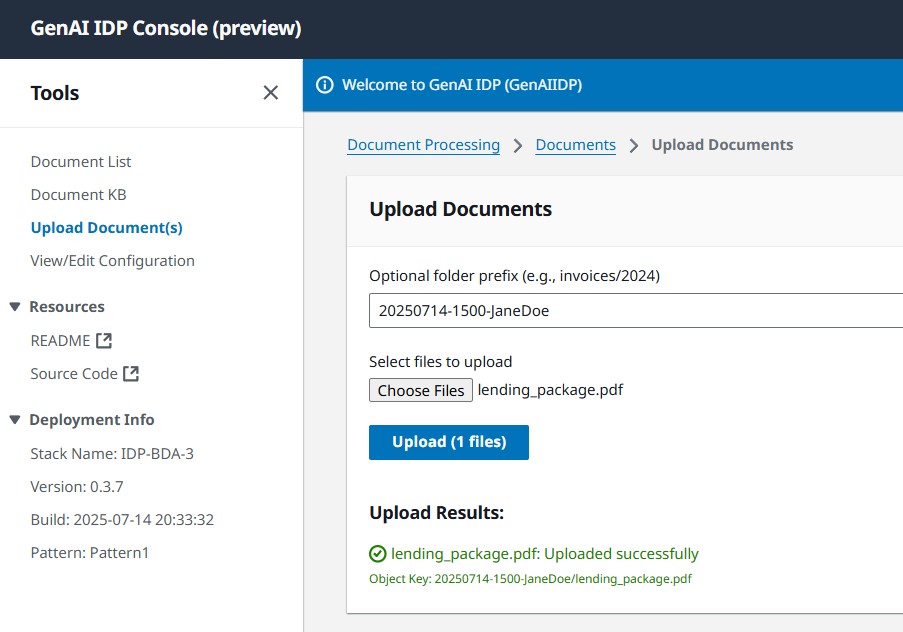
- Choose your doc from the doc record and select View Processing Stream to observe as your doc flows by the pipeline.
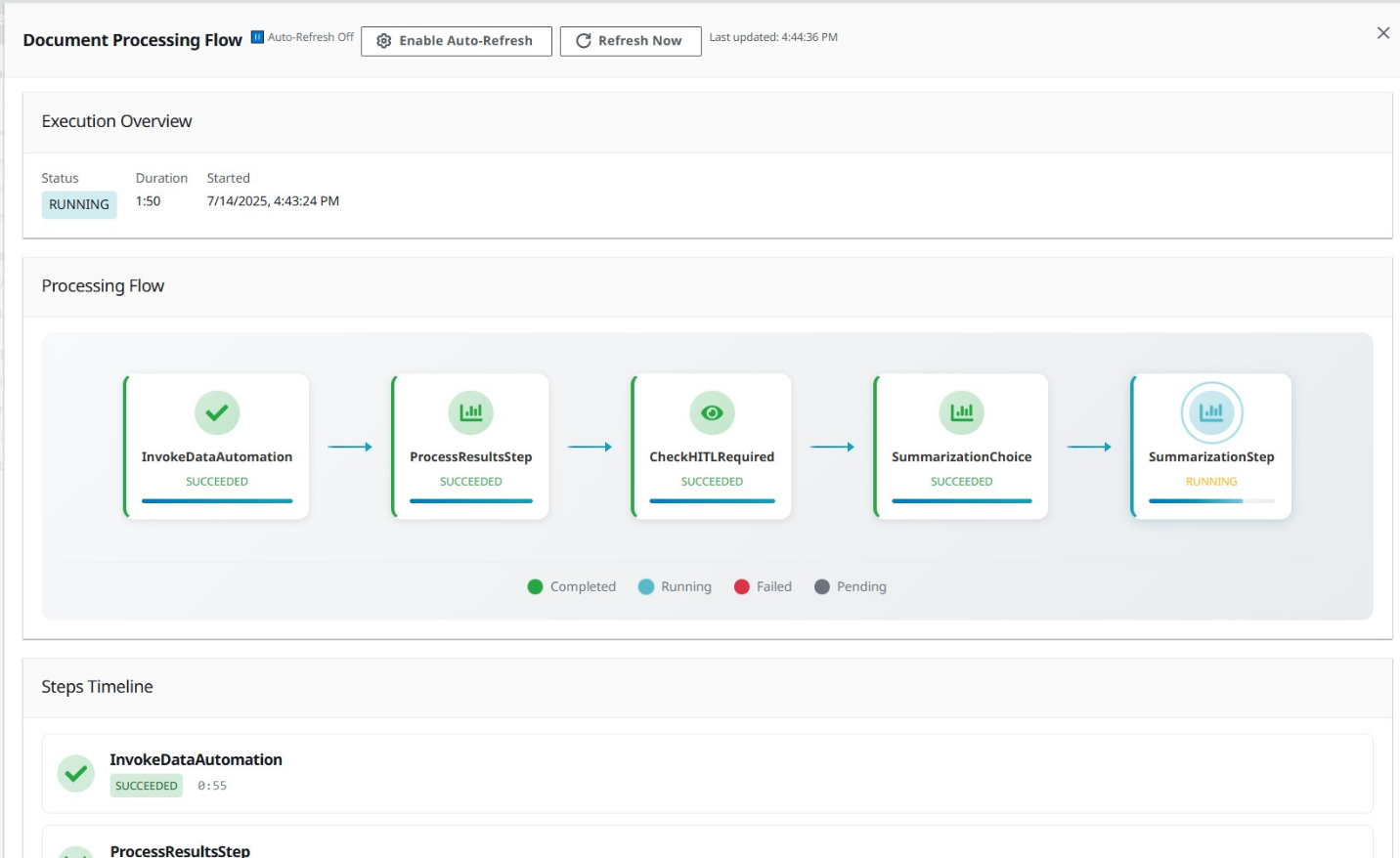
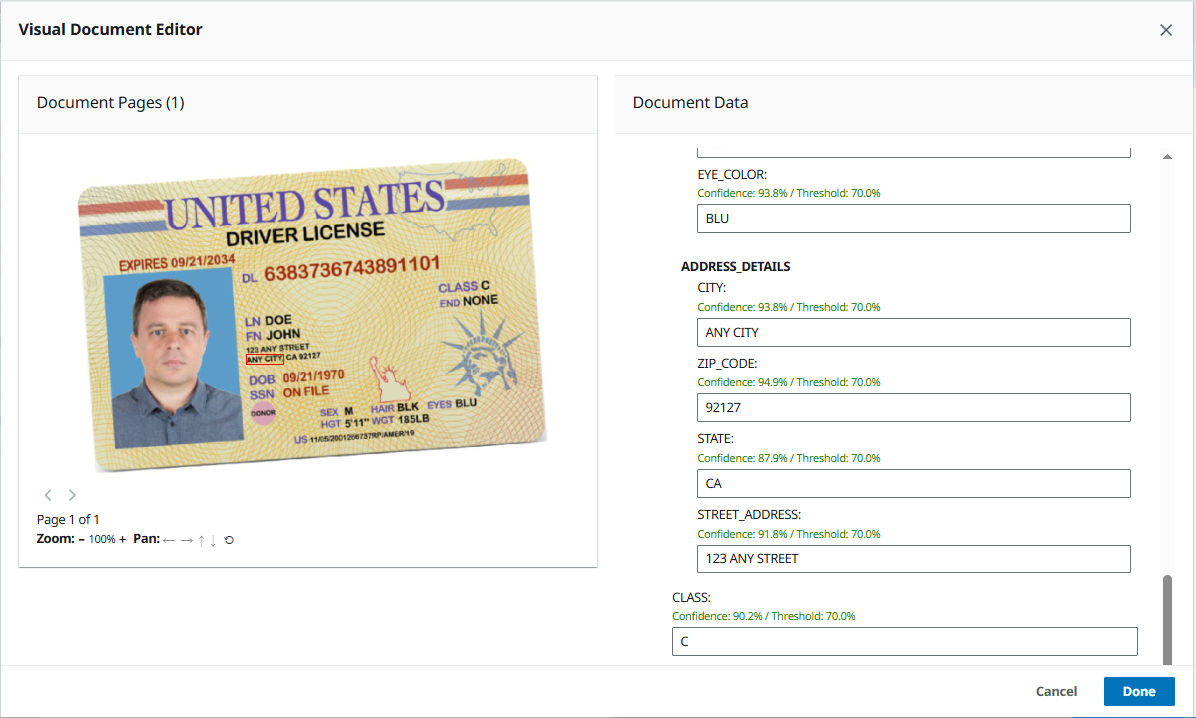
- Study the extracted knowledge with confidence scores.
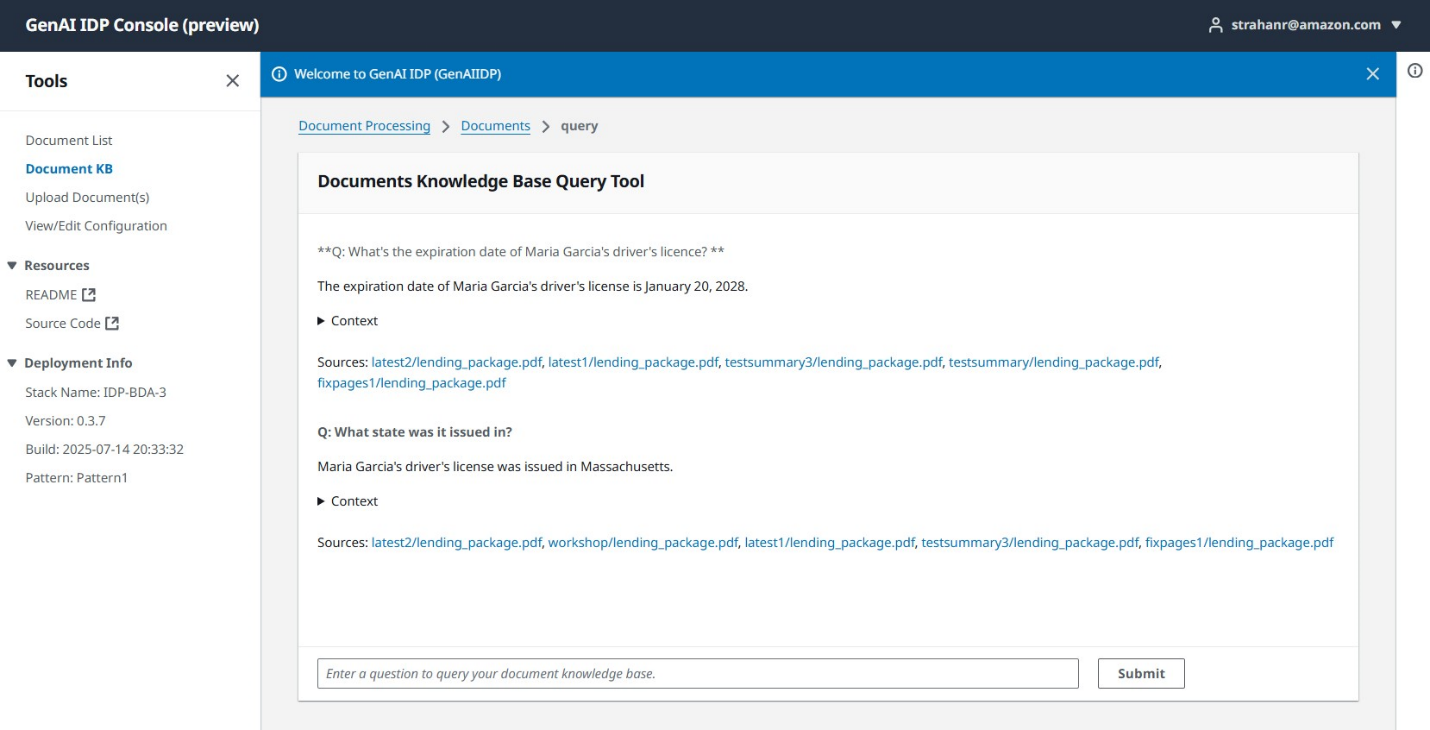
- Use the data base characteristic to ask questions on processed content material.
Various deployment strategies
You possibly can construct the answer from supply code if you’ll want to deploy the answer to extra Areas or construct and deploy code adjustments.
We hope so as to add help for AWS Cloud Growth Package (AWS CDK) and Terraform deployments. Observe the GitHub repository for updates, or contact AWS Skilled Companies for implementation help.
Replace an current GenAI IDP Accelerator stack
You possibly can replace your current GenAI IDP Accelerator stack to the most recent launch. For extra particulars, see Updating an Present Stack.
Clear up
Once you’re completed experimenting, clear up your assets by utilizing the AWS CloudFormation console to delete the IDP stack that you just deployed.
Conclusion
On this submit, we mentioned the GenAI IDP Accelerator, a brand new method to doc processing that mixes the ability of generative AI with the reliability and scale of AWS. You possibly can course of a whole lot and even hundreds of thousands of paperwork to attain higher outcomes sooner and extra cost-effectively than conventional approaches.
Go to the GitHub repository for detailed guides and examples and select watch to remain knowledgeable on new releases and options. AWS Skilled Companies and AWS Companions can be found to assist with implementation. You may as well be a part of the GitHub group to contribute enhancements and share your experiences.
Concerning the Authors
 Bob Strahan is a Principal Options Architect within the AWS Generative AI Innovation Heart.
Bob Strahan is a Principal Options Architect within the AWS Generative AI Innovation Heart.
 Joe King is a Senior Knowledge Scientist within the AWS Generative AI Innovation Heart.
Joe King is a Senior Knowledge Scientist within the AWS Generative AI Innovation Heart.
 Mofijul Islam is an Utilized Scientist within the AWS Generative AI Innovation Heart.
Mofijul Islam is an Utilized Scientist within the AWS Generative AI Innovation Heart.
 Vincil Bishop is a Senior Deep Studying Architect within the AWS Generative AI Innovation Heart.
Vincil Bishop is a Senior Deep Studying Architect within the AWS Generative AI Innovation Heart.
 David Kaleko is a Senior Utilized Scientist within the AWS Generative AI Innovation Heart.
David Kaleko is a Senior Utilized Scientist within the AWS Generative AI Innovation Heart.
 Rafal Pawlaszek is a Senior Cloud Utility Architect within the AWS Generative AI Innovation Heart.
Rafal Pawlaszek is a Senior Cloud Utility Architect within the AWS Generative AI Innovation Heart.
 Spencer Romo is a Senior Knowledge Scientist within the AWS Generative AI Innovation Heart.
Spencer Romo is a Senior Knowledge Scientist within the AWS Generative AI Innovation Heart.
 Vamsi Thilak Gudi is a Options Architect within the AWS World Broad Public Sector staff.
Vamsi Thilak Gudi is a Options Architect within the AWS World Broad Public Sector staff.
Acknowledgments
We wish to thank Abhi Sharma, Akhil Nooney, Aleksei Iancheruk, Ava Kong, Boyi Xie, Diego Socolinsky, Guillermo Tantachuco, Ilya Marmur, Jared Kramer, Jason Zhang, Jordan Ratner, Mariano Bellagamba, Mark Aiyer, Niharika Jain, Nimish Radia, Shean Sager, Sirajus Salekin, Yingwei Yu, and plenty of others in our increasing group, for his or her unwavering imaginative and prescient, ardour, contributions, and steerage all through.