
Picture by Writer
# Introduction
When making use of for a job at Meta (previously Fb), Apple, Amazon, Netflix, or Alphabet (Google) — collectively often known as FAANG — interviews not often check whether or not you’ll be able to recite textbook definitions. As an alternative, interviewers wish to see whether or not you analyze information critically and whether or not you’ll establish a foul evaluation earlier than it ships to manufacturing. Statistical traps are probably the most dependable methods to check that.

These pitfalls replicate the varieties of choices that analysts face each day: a dashboard quantity that appears nice however is definitely deceptive, or an experiment outcome that appears actionable however comprises a structural flaw. The interviewer already is aware of the reply. What they’re watching is your thought course of, together with whether or not you ask the correct questions, discover lacking data, and push again on a quantity that appears good at first sight. Candidates stumble over these traps repeatedly, even these with robust mathematical backgrounds.
We’ll study 5 of the commonest traps.
# Understanding Simpson’s Paradox
This entice goals to catch individuals who unquestioningly belief aggregated numbers.
Simpson’s paradox occurs when a pattern seems in numerous teams of information however vanishes or reverses when combining these teams. The traditional instance is UC Berkeley’s 1973 admissions information: total admission charges favored males, however when damaged down by division, ladies had equal or higher admission charges. The mixture quantity was deceptive as a result of ladies utilized to extra aggressive departments.
The paradox is inevitable each time teams have completely different sizes and completely different base charges. Understanding that’s what can separate a surface-level reply from a deep one.
In interviews, a query may appear like this: “We ran an A/B check. General, variant B had the next conversion fee. Nonetheless, once we break it down by gadget sort, variant A carried out higher on each cellular and desktop. What is going on?” A powerful candidate refers to Simpson’s paradox, clarifies its trigger (group proportions differ between the 2 variants), and asks to see the breakdown fairly than belief the combination determine.
Interviewers use this to test whether or not you instinctively ask about subgroup distributions. For those who simply report the general quantity, you may have misplaced factors.
// Demonstrating With A/B Take a look at Knowledge
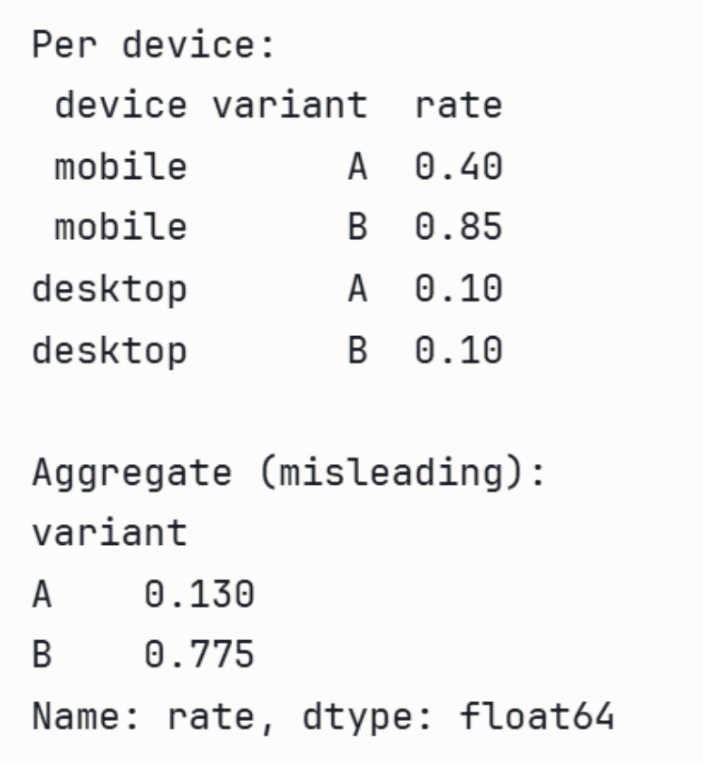
Within the following demonstration utilizing Pandas, we will see how the combination fee could be deceptive.
import pandas as pd
# A wins on each gadgets individually, however B wins in combination
# as a result of B will get most site visitors from higher-converting cellular.
information = pd.DataFrame({
'gadget': ['mobile', 'mobile', 'desktop', 'desktop'],
'variant': ['A', 'B', 'A', 'B'],
'converts': [40, 765, 90, 10],
'guests': [100, 900, 900, 100],
})
information['rate'] = information['converts'] / information['visitors']
print('Per gadget:')
print(information[['device', 'variant', 'rate']].to_string(index=False))
print('nAggregate (deceptive):')
agg = information.groupby('variant')[['converts', 'visitors']].sum()
agg['rate'] = agg['converts'] / agg['visitors']
print(agg['rate'])
Output:
# Figuring out Choice Bias
This check lets interviewers assess whether or not you concentrate on the place information comes from earlier than analyzing it.
Choice bias arises when the information you may have isn’t consultant of the inhabitants you are trying to know. As a result of the bias is within the information assortment course of fairly than within the evaluation, it’s easy to miss.
Contemplate these doable interview framings:
- We analyzed a survey of our customers and located that 80% are happy with the product. Does that inform us our product is nice? A stable candidate would level out that happy customers are extra doubtless to reply to surveys. The 80% determine in all probability overstates satisfaction since sad customers most probably selected to not take part.
- We examined prospects who left final quarter and found they primarily had poor engagement scores. Ought to our consideration be on engagement to cut back churn? The issue right here is that you simply solely have engagement information for churned customers. You don’t have engagement information for customers who stayed, which makes it unattainable to know if low engagement really predicts churn or whether it is only a attribute of churned customers generally.
A associated variant price figuring out is survivorship bias: you solely observe the outcomes that made it by way of some filter. For those who solely use information from profitable merchandise to research why they succeeded, you might be ignoring those who failed for a similar causes that you’re treating as strengths.
// Simulating Survey Non-Response
We will simulate how non-response bias skews outcomes utilizing NumPy.
import numpy as np
import pandas as pd
np.random.seed(42)
# Simulate customers the place happy customers usually tend to reply
satisfaction = np.random.alternative([0, 1], dimension=1000, p=[0.5, 0.5])
# Response chance: 80% for happy, 20% for unhappy
response_prob = np.the place(satisfaction == 1, 0.8, 0.2)
responded = np.random.rand(1000) < response_prob
print(f"True satisfaction fee: {satisfaction.imply():.2%}")
print(f"Survey satisfaction fee: {satisfaction[responded].imply():.2%}")
Output:

Interviewers use choice bias inquiries to see should you separate “what the information exhibits” from “what’s true about customers.”
# Stopping p-Hacking
p-hacking (additionally known as information dredging) occurs while you run many exams and solely report those with ( p < 0.05 ).
The difficulty is that ( p )-values are solely meant for particular person exams. One false constructive could be anticipated by likelihood alone if 20 exams have been run at a 5% significance stage. The false discovery fee is elevated by fishing for a major outcome.
An interviewer may ask you the next: “Final quarter, we performed fifteen characteristic experiments. At ( p < 0.05 ), three have been discovered to be vital. Do all three should be shipped?” A weak reply says sure.
A powerful reply would firstly ask what the hypotheses have been earlier than the exams have been run, if the importance threshold was set prematurely, and whether or not the group corrected for a number of comparisons.
The follow-up usually includes how you’ll design experiments to keep away from this. Pre-registering hypotheses earlier than information assortment is probably the most direct repair, because it removes the choice to determine after the very fact which exams have been “actual.”
// Watching False Positives Accumulate
We will observe how false positives happen by likelihood utilizing SciPy.
import numpy as np
from scipy import stats
np.random.seed(0)
# 20 A/B exams the place the null speculation is TRUE (no actual impact)
n_tests, alpha = 20, 0.05
false_positives = 0
for _ in vary(n_tests):
a = np.random.regular(0, 1, 1000)
b = np.random.regular(0, 1, 1000) # similar distribution!
if stats.ttest_ind(a, b).pvalue < alpha:
false_positives += 1
print(f'Exams run: {n_tests}')
print(f'False positives (p<0.05): {false_positives}')
print(f'Anticipated by likelihood alone: {n_tests * alpha:.0f}')
Output:

Even with zero actual impact, ~1 in 20 exams clears ( p < 0.05 ) by likelihood. If a group runs 15 experiments and stories solely the numerous ones, these outcomes are most probably noise.
It’s equally essential to deal with exploratory evaluation as a type of speculation technology fairly than affirmation. Earlier than anybody takes motion primarily based on an exploration outcome, a confirmatory experiment is required.
# Managing A number of Testing
This check is carefully associated to p-hacking, however it’s price understanding by itself.
The a number of testing downside is the formal statistical problem: while you run many speculation exams concurrently, the chance of no less than one false constructive grows rapidly. Even when the remedy has no impact, it’s best to anticipate roughly 5 false positives should you check 100 metrics in an A/B check and declare something with ( p < 0.05 ) as vital.
The corrections for this are well-known: Bonferroni correction (divide alpha by the variety of exams) and Benjamini-Hochberg (controls the false discovery fee fairly than the family-wise error fee).
Bonferroni is a conservative strategy: for instance, should you check 50 metrics, your per-test threshold drops to 0.001, making it more durable to detect actual results. Benjamini-Hochberg is extra applicable if you end up keen to simply accept some false discoveries in trade for extra statistical energy.
In interviews, this comes up when discussing how an organization tracks experiment metrics. A query is likely to be: “We monitor 50 metrics per experiment. How do you determine which of them matter?” A stable response discusses pre-specifying main metrics previous to the experiment’s execution and treating secondary metrics as exploratory whereas acknowledging the difficulty of a number of testing.
Interviewers are looking for out if you’re conscious that taking extra exams ends in extra noise fairly than extra data.
# Addressing Confounding Variables
This entice catches candidates who deal with correlation as causation with out asking what else may clarify the connection.
A confounding variable is one which influences each the unbiased and dependent variables, creating the phantasm of a direct relationship the place none exists.
The traditional instance: ice cream gross sales and drowning charges are correlated, however the confounder is summer season warmth; each go up in heat months. Appearing on that correlation with out accounting for the confounder results in unhealthy selections.
Confounding is especially harmful in observational information. In contrast to a randomized experiment, observational information doesn’t distribute potential confounders evenly between teams, so variations you see may not be brought on by the variable you might be finding out in any respect.
A typical interview framing is: “We seen that customers who use our cellular app extra are likely to have considerably increased income. Ought to we push notifications to extend app opens?” A weak candidate says sure. A powerful one asks what sort of person opens the app ceaselessly to start with: doubtless probably the most engaged, highest-value customers.
Engagement drives each app opens and spending. The app opens will not be inflicting income; they’re a symptom of the identical underlying person high quality.
Interviewers use confounding to check whether or not you distinguish correlation from causation earlier than drawing conclusions, and whether or not you’ll push for randomized experimentation or propensity rating matching earlier than recommending motion.
// Simulating A Confounded Relationship
import numpy as np
import pandas as pd
np.random.seed(42)
n = 1000
# Confounder: person high quality (0 = low, 1 = excessive)
user_quality = np.random.binomial(1, 0.5, n)
# App opens pushed by person high quality, not unbiased
app_opens = user_quality * 5 + np.random.regular(0, 1, n)
# Income additionally pushed by person high quality, not app opens
income = user_quality * 100 + np.random.regular(0, 10, n)
df = pd.DataFrame({
'user_quality': user_quality,
'app_opens': app_opens,
'income': income
})
# Naive correlation seems to be robust — deceptive
naive_corr = df['app_opens'].corr(df['revenue'])
# Inside-group correlation (controlling for confounder) is close to zero
corr_low = df[df['user_quality']==0]['app_opens'].corr(df[df['user_quality']==0]['revenue'])
corr_high = df[df['user_quality']==1]['app_opens'].corr(df[df['user_quality']==1]['revenue'])
print(f"Naive correlation (app opens vs income): {naive_corr:.2f}")
print(f"Correlation controlling for person high quality:")
print(f" Low-quality customers: {corr_low:.2f}")
print(f" Excessive-quality customers: {corr_high:.2f}")
Output:
Naive correlation (app opens vs income): 0.91
Correlation controlling for person high quality:
Low-quality customers: 0.03
Excessive-quality customers: -0.07
The naive quantity seems to be like a powerful sign. When you management for the confounder, it disappears solely. Interviewers who see a candidate run this type of stratified test (fairly than accepting the combination correlation) know they’re speaking to somebody who won’t ship a damaged advice.
# Wrapping Up
All 5 of those traps have one thing in widespread: they require you to decelerate and query the information earlier than accepting what the numbers appear to indicate at first look. Interviewers use these situations particularly as a result of your first intuition is commonly flawed, and the depth of your reply after that first intuition is what separates a candidate who can work independently from one who wants path on each evaluation.

None of those concepts are obscure, and interviewers inquire about them as a result of they’re typical failure modes in actual information work. The candidate who acknowledges Simpson’s paradox in a product metric, catches a range bias in a survey, or questions whether or not an experiment outcome survived a number of comparisons is the one who will ship fewer unhealthy selections.
For those who go into FAANG interviews with a reflex to ask the next questions, you might be already forward of most candidates:
- How was this information collected?
- Are there subgroups that inform a unique story?
- What number of exams contributed to this outcome?
Past serving to in interviews, these habits can even stop unhealthy selections from reaching manufacturing.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from prime firms. Nate writes on the most recent traits within the profession market, provides interview recommendation, shares information science tasks, and covers every part SQL.