
Video content material is now in all places, from safety surveillance and media manufacturing to social platforms and enterprise communications. Nevertheless, extracting significant insights from massive volumes of video stays a serious problem. Organizations want options that may perceive not solely what seems in a video, but in addition the context, narrative, and underlying which means of the content material.
On this submit, we discover how the multimodal basis fashions (FMs) of Amazon Bedrock allow scalable video understanding via three distinct architectural approaches. Every strategy is designed for various use circumstances and cost-performance trade-offs. The whole answer is accessible as an open supply AWS pattern on GitHub.
The evolution of video evaluation
Conventional video evaluation approaches depend on handbook evaluation or primary pc imaginative and prescient strategies that detect predefined patterns. Whereas purposeful, these strategies face important limitations:
- Scale constraints: Handbook evaluation is time-consuming and costly
- Restricted flexibility: Rule-based methods can’t adapt to new situations
- Context blindness: Conventional CV lacks semantic understanding
- Integration complexity: Troublesome to include into trendy purposes
The emergence of multimodal basis fashions on Amazon Bedrock modifications this paradigm. These fashions can course of each visible and textual data collectively. This permits them to grasp scenes, generate pure language descriptions, reply questions on video content material, and detect nuanced occasions that will be tough to outline programmatically.
Three approaches to video understanding
Understanding video content material is inherently complicated, combining visible, auditory, and temporal data that should be analyzed collectively for significant insights. Completely different use circumstances, corresponding to media scene evaluation, advert break detection, IP digital camera monitoring, or social media moderation, require distinct workflows with various price, accuracy, and latency trade-offs.This answer offers three distinct workflows, every utilizing completely different video extraction strategies optimized for particular situations.
Body-based workflow: precision at scale
The frame-based strategy samples picture frames at fastened intervals, removes comparable or redundant frames, and applies picture understanding basis fashions to extract visible data on the body stage. Audio transcription is carried out individually utilizing Amazon Transcribe.

This workflow is good for:
- Safety and surveillance: Detect particular situations or occasions throughout time
- High quality assurance: Monitor manufacturing or operational processes
- Compliance monitoring: Confirm adherence to security protocols
The structure makes use of AWS Step Features to orchestrate the whole pipeline:
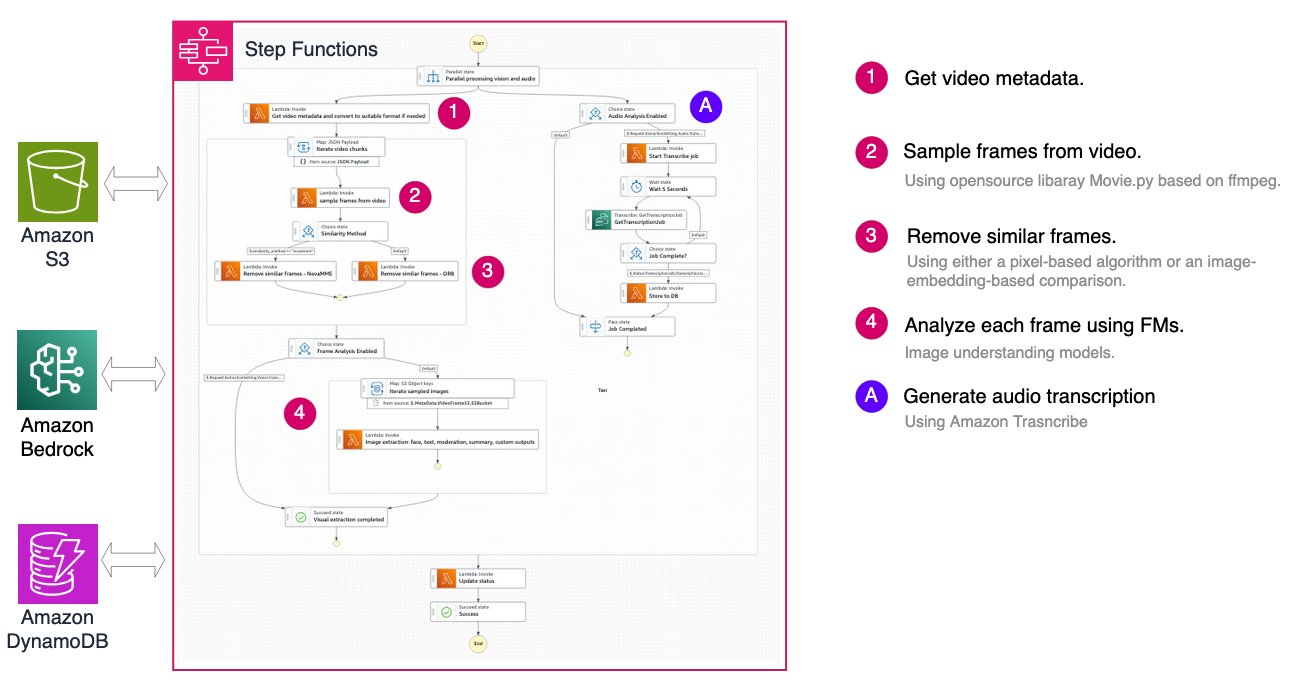
Good sampling: optimizing price and high quality
A key function of the frame-based workflow is clever body deduplication, which considerably reduces processing prices by eradicating redundant frames whereas preserving visible data. The answer offers two distinct similarity comparability strategies.
Nova Multimodal Embeddings (MME) Comparability makes use of the multimodal embeddings mannequin of Amazon Nova to generate 256-dimensional vector representations of every body. Every body is encoded right into a vector embedding utilizing the Nova MME mannequin, and the cosine distance between consecutive frames is computed. Frames with distance beneath the edge (default 0.2, the place decrease values point out increased similarity) are eliminated. This strategy excels at semantic understanding of picture content material, remaining sturdy to minor variations in lighting and perspective whereas capturing high-level visible ideas. Nevertheless, it incurs further Amazon Bedrock API prices for embedding technology and provides barely increased latency per body. This technique is beneficial for content material the place semantic similarity issues greater than pixel-level variations, corresponding to detecting scene modifications or figuring out distinctive moments.
OpenCV ORB (Oriented FAST and Rotated BRIEF) takes a pc imaginative and prescient strategy, utilizing function detection to establish and match key factors between consecutive frames with out requiring exterior API calls. ORB detects key factors and computes binary descriptors for every body, calculating the similarity rating because the ratio of matched options to complete key factors. With a default threshold of 0.325 (the place increased values point out increased similarity), this technique affords quick processing with minimal latency and no further API prices. The rotation-invariant function matching makes it wonderful for detecting digital camera motion and body transitions. Nevertheless, it may be delicate to important lighting modifications and should not seize semantic similarity as successfully as embedding-based approaches. This technique is beneficial for static digital camera situations like surveillance footage, or cost-sensitive purposes the place pixel-level similarity is ample.
Shot-based workflow: understanding narrative circulate
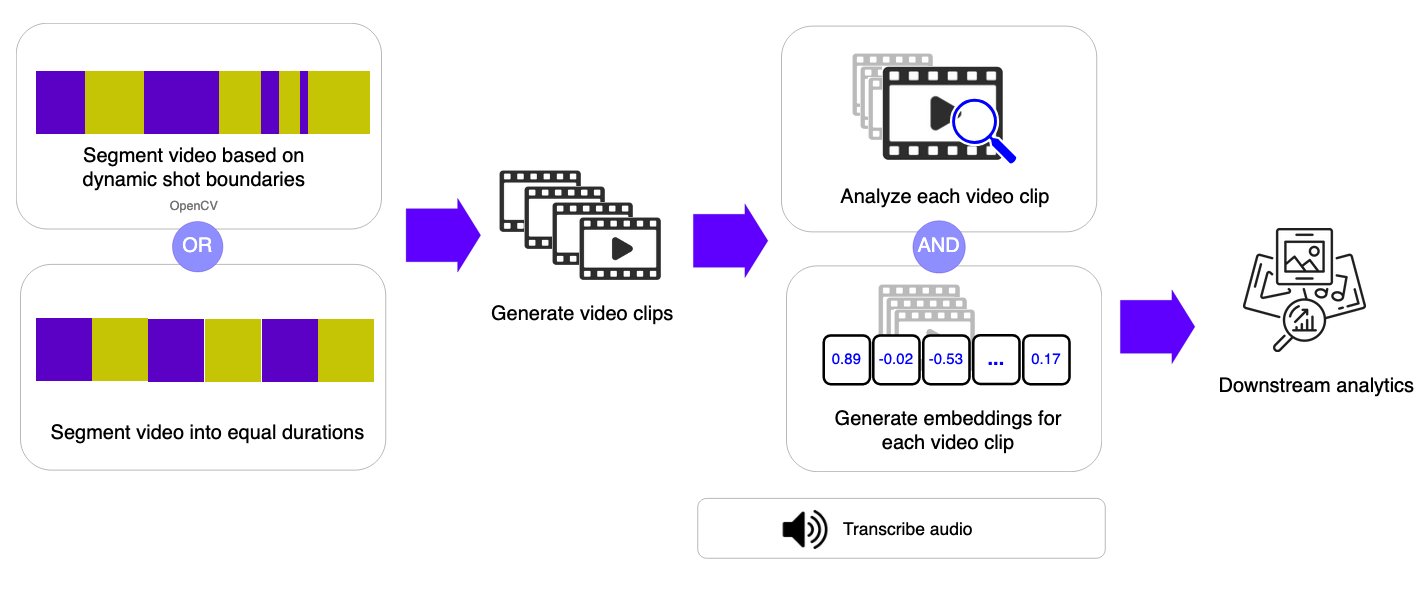
As an alternative of sampling particular person frames, the shot-based workflow segments video into brief clips (pictures) or fixed-duration segments and applies video understanding basis fashions to every section. This strategy captures temporal context inside every shot whereas sustaining the pliability to course of longer movies.
By producing each semantic labels and embeddings for every shot, this technique permits environment friendly video search and retrieval whereas balancing accuracy and adaptability. The structure teams pictures into batches of 10 for parallel processing in subsequent steps, enhancing throughput whereas managing AWS Lambda concurrency limits.
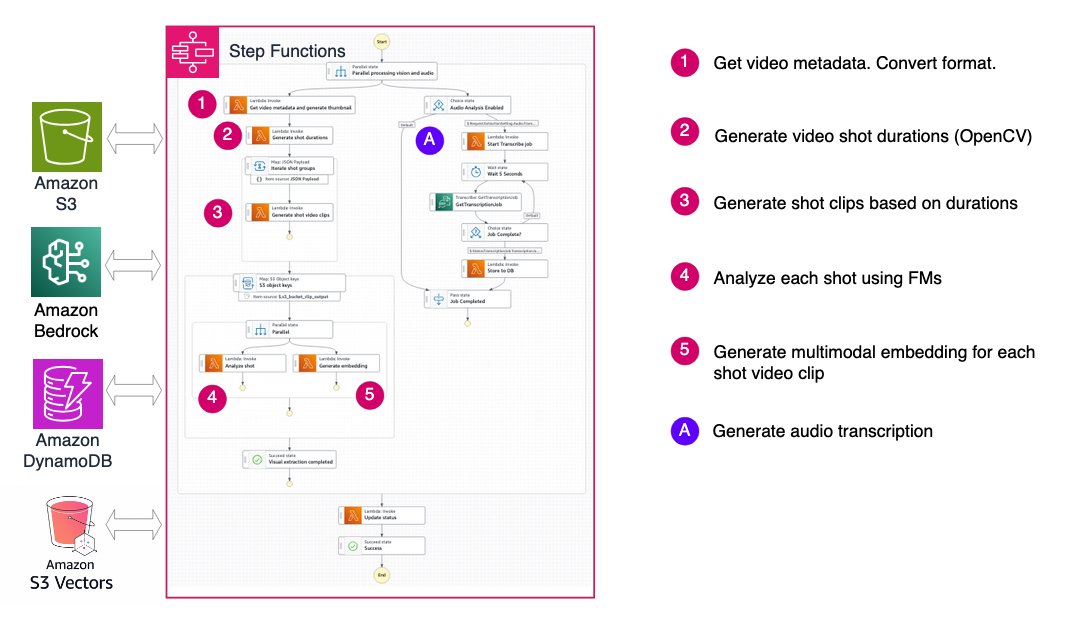
This workflow excels at:
- Media manufacturing: Analyze footage for chapter markers and scene descriptions
- Content material cataloging: Robotically tag and arrange video libraries
- Spotlight technology: Establish key moments in long-form content material
Video segmentation: two approaches
The shot-based workflow offers versatile segmentation choices to match completely different video traits and use circumstances. The system downloads the video file from Amazon Easy Storage Service (Amazon S3) to non permanent storage in AWS Lambda, then applies the chosen segmentation algorithm based mostly on the configuration parameters.
OpenCV Scene Detection mechanically divides a video into segments based mostly on visible modifications within the content material. This strategy makes use of the PySceneDetect library to detect transitions corresponding to cuts, digital camera modifications, or important shifts in visible content material.
By figuring out pure scene boundaries, the system retains associated moments grouped collectively. This makes the strategy notably efficient for edited or narrative-driven movies corresponding to films, TV exhibits, shows, and vlogs, the place scenes characterize significant items of content material. As a result of segmentation follows the construction of the video itself, section lengths can differ relying on the pacing and enhancing fashion.
Mounted-Period Segmentation divides a video into equal-length time intervals, regardless of what’s occurring within the video.
Every section covers a constant period (for instance, 10 seconds), creating predictable and uniform clips. This strategy streamlines processing and improves processing time and value estimations. Though it would break up scenes mid-action, fixed-duration segmentation works nicely for steady recordings corresponding to surveillance footage, sports activities occasions, or reside streams, the place common time sampling is extra necessary than preserving narrative boundaries.
Multimodal embedding: semantic video search
Multimodal embedding represents an rising strategy to video understanding, notably highly effective for video semantic search purposes. The answer affords workflows utilizing Amazon Nova Multimodal Embedding and TwelveLabs Marengo fashions out there on Amazon Bedrock.
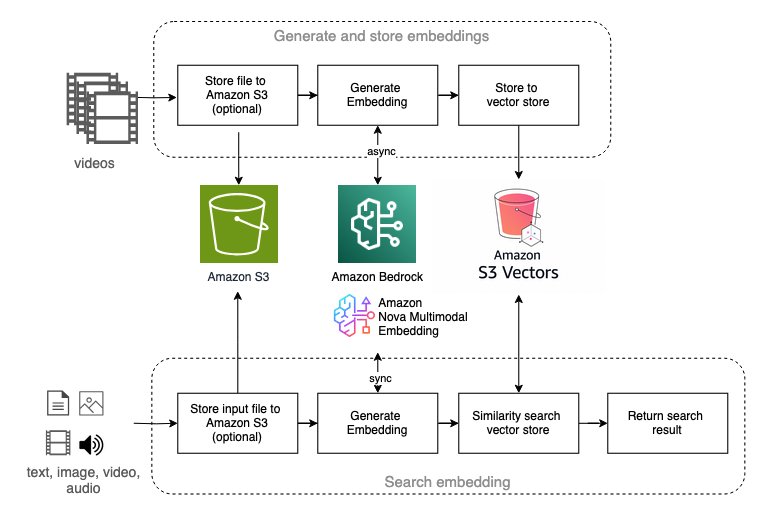
These workflows allow:
- Pure language search: Discover video segments utilizing textual content queries
- Visible similarity search: Find content material utilizing reference pictures
- Cross-modal retrieval: Bridge the hole between textual content and visible content material
The structure helps each embedding fashions with a unified interface:
Understanding price and efficiency trade-offs
One of many key challenges in manufacturing video evaluation is managing prices whereas sustaining high quality. The answer offers built-in token utilization monitoring and value estimation that can assist you make knowledgeable selections about mannequin choice and workflow configuration.
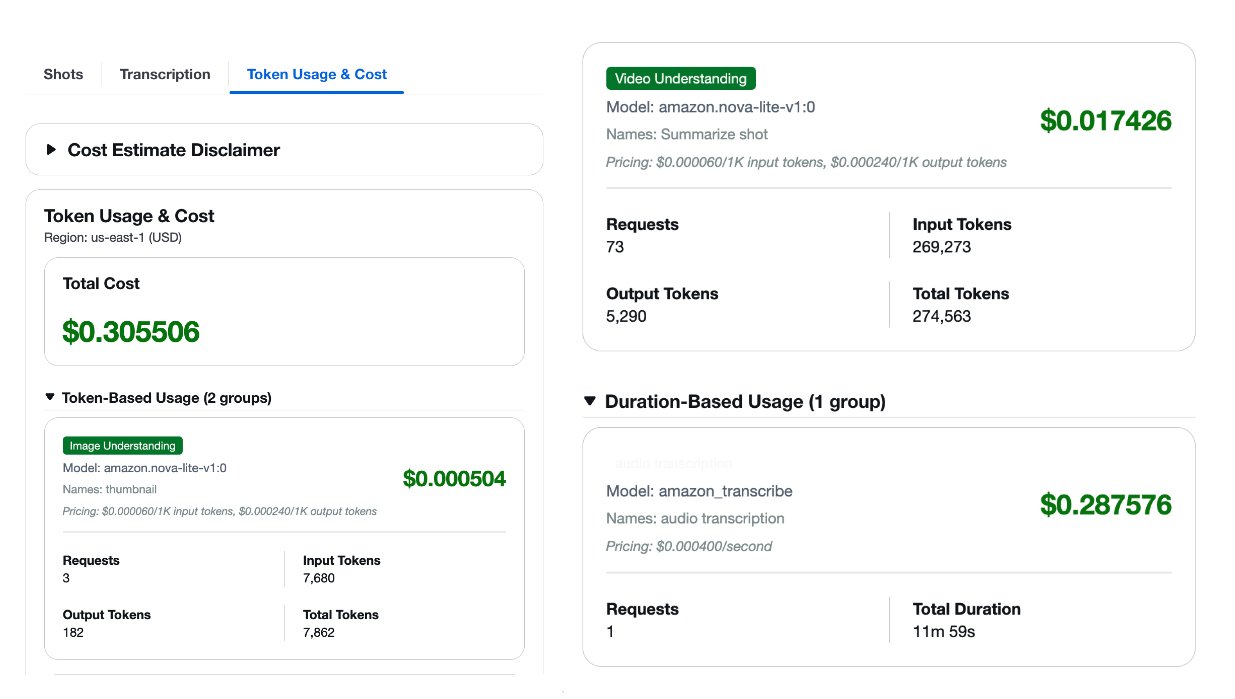
The earlier screenshot exhibits a pattern price estimate generated by the answer as an example the format. It shouldn’t be used as a pricing supply.For every processed video, you obtain an in depth price breakdown by mannequin kind, masking Amazon Bedrock basis fashions and Amazon Transcribe for audio transcription. With this visibility, you possibly can enhance your configuration based mostly in your particular necessities and price range constraints.
System structure
The whole answer is constructed on AWS serverless providers, offering scalability and cost-efficiency:
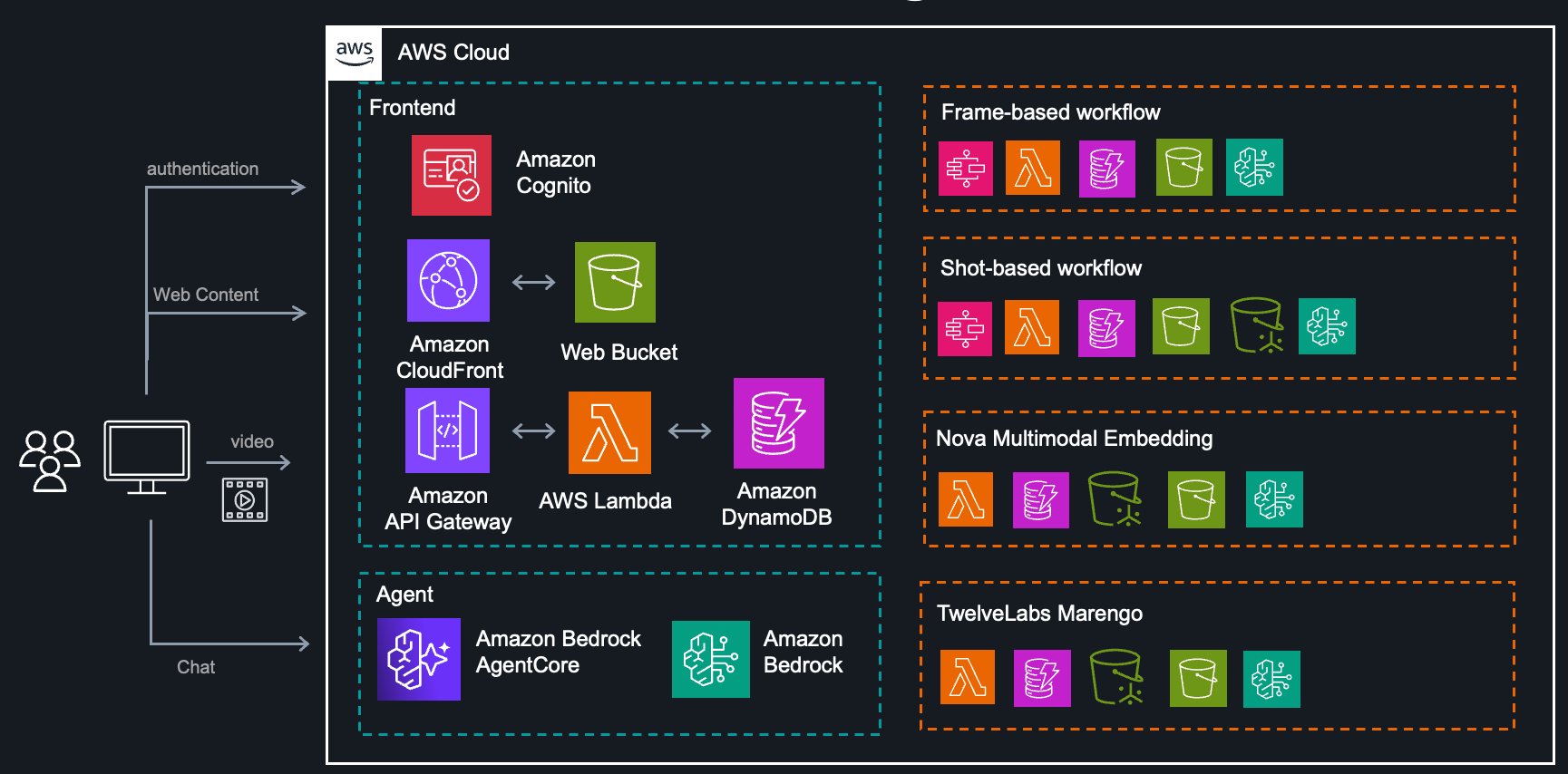
The structure consists of:
- Extraction Service: Orchestrates frame-based and shot-based workflows utilizing Step Features
- Nova Service: Backend for Nova Multimodal Embedding with vector search
- TwelveLabs Service: Backend for Marengo embedding fashions with vector search
- Agent Service: AI assistant powered by Amazon Bedrock Brokers for workflow suggestions
- Frontend: React utility served utilizing Amazon CloudFront for consumer interplay
- Analytics Service: Pattern notebooks demonstrating downstream evaluation patterns
Accessing your video metadata
The answer shops extracted metadata in a number of codecs for versatile entry:
- Amazon S3: Uncooked basis mannequin outputs, full job metadata, and processed belongings organized by job ID and knowledge kind.
- Amazon DynamoDB: Structured, queryable knowledge optimized for retrieval by video, timestamp, or evaluation kind throughout a number of tables for various providers.
- Programmatic API: Direct invocation for automation, bulk processing, and integration into present pipelines.
You should utilize this versatile entry mannequin to combine the instrument into your workflows—whether or not conducting exploratory evaluation in notebooks, constructing automated pipelines, or creating manufacturing purposes.
Actual-world use circumstances
The answer consists of pattern notebooks demonstrating three widespread situations:
- IP Digicam Occasion Detection: Robotically monitor surveillance footage for particular occasions or situations with out fixed human oversight.
- Media Chapter Evaluation: Section long-form video content material into logical chapters with automated descriptions and metadata.
- Social Media Content material Moderation: Evaluation user-generated video content material at scale to make sure that platform tips are met.
These examples present beginning factors that you could lengthen and customise on your particular use circumstances.
Getting began
Deploy the answer
The answer is accessible as a CDK bundle on GitHub and could be deployed to your AWS account with just a few instructions. The deployment creates all obligatory sources together with:
- Step Features state machines for orchestration
- Lambda capabilities for processing logic
- DynamoDB tables for metadata storage
- S3 buckets for asset storage
- CloudFront distribution for the net interface
- Amazon Cognito consumer pool for authentication
After deployment, you possibly can instantly begin importing movies, experimenting with completely different evaluation pipelines and basis fashions, and evaluating efficiency throughout configurations.
Conclusion
Video understanding is not restricted to organizations with specialised pc imaginative and prescient groups and infrastructure. The multimodal basis fashions of Amazon Bedrock, mixed with AWS serverless providers, make subtle video evaluation accessible and cost-effective.Whether or not you’re constructing safety monitoring methods, media manufacturing instruments, or content material moderation platforms, the three architectural approaches demonstrated on this answer present versatile beginning factors designed for various necessities. The secret’s choosing the proper strategy on your use case: frame-based for precision monitoring, shot-based for narrative content material, and embedding-based for semantic search.As multimodal fashions proceed to evolve, we are going to see much more subtle video understanding capabilities emerge. The longer term is about AI that doesn’t solely see video frames, however actually understands the story they inform.
Able to get began?
Be taught extra:
Concerning the authors