
With Apple Intelligence, we’re integrating highly effective generative AI proper into the apps and experiences folks use every single day, all whereas defending their privateness. On the 2025 Worldwide Builders Convention we launched a brand new era of language basis fashions particularly developed to reinforce the Apple Intelligence options in our newest software program releases. We additionally launched the brand new Basis Fashions framework, which provides app builders direct entry to the on-device basis language mannequin on the core of Apple Intelligence.
We crafted these generative fashions to energy the wide selection of clever options built-in throughout our platforms. The fashions have improved tool-use and reasoning capabilities, perceive picture and textual content inputs, are sooner and extra environment friendly, and are designed to assist 15 languages. Our newest basis fashions are optimized to run effectively on Apple silicon, and embrace a compact, roughly 3-billion-parameter mannequin, alongside a mixture-of-experts server-based mannequin with a novel structure tailor-made for Non-public Cloud Compute. These two basis fashions are half of a bigger household of generative fashions created by Apple to assist our customers.
On this overview, we element the architectures of the fashions we designed, the info we used for coaching, the coaching recipes we employed, the strategies we used to optimize inference, and our analysis outcomes when in comparison with comparable fashions. All through, we spotlight how we achieved an enlargement of capabilities and high quality enhancements whereas rising pace and effectivity on-device and on Non-public Cloud Compute. Lastly, in our continued dedication to uphold our core values, we illustrate how Accountable AI ideas are built-in all through all the mannequin improvement course of.
Mannequin Architectures
We developed each the on-device and server fashions to fulfill a variety of efficiency and deployment necessities. The on-device mannequin is optimized for effectivity and tailor-made for Apple silicon, enabling low-latency inference with minimal useful resource utilization, whereas the server mannequin is designed to ship excessive accuracy and scalability for extra complicated duties. Collectively, they kind a complementary suite of options adaptable to various purposes.
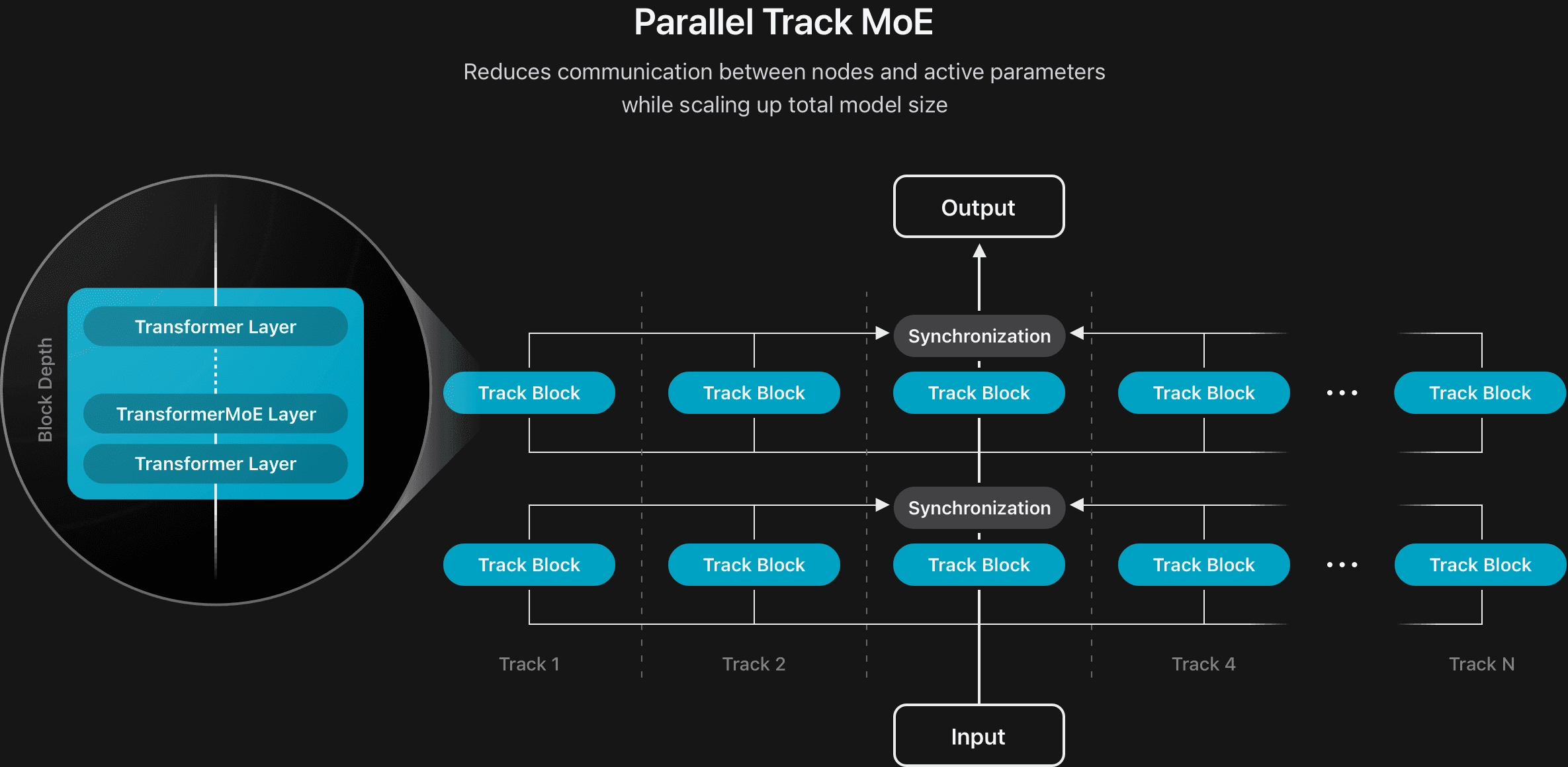
We have improved the effectivity of each fashions by growing new mannequin architectures. For the on-device mannequin, we divided the total mannequin into two blocks with a 5:3 depth ratio. All the key-value (KV) caches of block 2 are immediately shared with these generated by the ultimate layer of block 1, decreasing the KV cache reminiscence utilization by 37.5% and considerably bettering the time-to-first-token. We additionally developed a brand new structure for the server mannequin by introducing a parallel observe mixture-of-experts (PT-MoE) design (see Determine 2). This mannequin consists of a number of smaller transformers, known as tracks, that course of tokens independently, with synchronization utilized solely on the enter and output boundaries of every observe block. Every observe block moreover has its personal set of MoE layers. Mixed with the track-level parallelism enabled by observe independence, this design considerably diminished synchronization overhead and allowed the mannequin to scale effectively whereas sustaining low latency with out compromising high quality.
To assist longer context inputs, we designed an interleaved consideration structure combining the sliding-window native consideration layers with rotational positional embeddings (RoPE) and a worldwide consideration layer with out positional embeddings (NoPE). This setup improves size generalization, reduces KV cache measurement, and maintains mannequin high quality throughout long-context inference.
And to allow visible capabilities, we developed a imaginative and prescient encoder skilled on large-scale picture information. It consists of a imaginative and prescient spine for extracting wealthy options and a vision-language adapter to align the options with the LLM’s token representations. We used the usual Imaginative and prescient Transformer (ViT-g) with 1B parameters for the server mannequin and the extra environment friendly ViTDet-L spine with 300M parameters for on-device deployment. To additional successfully seize and combine each native particulars and broader world context, we added a novel Register-Window (RW) mechanism to the usual ViTDet, in order that each the worldwide context and the native particulars could be successfully captured.
Coaching Knowledge
We consider in coaching our fashions utilizing various and high-quality information. This contains information that we have licensed from publishers, curated from publicly obtainable or open-sourced datasets, and publicly obtainable info crawled by our web-crawler, Applebot. We don’t use our customers’ personal private information or person interactions when coaching our basis fashions. Moreover, we take steps to use filters to take away sure classes of personally identifiable info and to exclude profanity and unsafe materials.
Additional, we proceed to observe greatest practices for moral net crawling, together with following widely-adopted robots.txt protocols to permit net publishers to choose out of their content material getting used to coach Apple’s generative basis fashions. Internet publishers have fine-grained controls over which pages Applebot can see and the way they’re used whereas nonetheless showing in search outcomes inside Siri and Highlight.
Textual content Knowledge
Whereas respecting the opt-outs famous above, we continued to supply a good portion of the pre-training information for our fashions from net content material crawled by Applebot, spanning tons of of billions of pages and overlaying an intensive vary of languages, locales, and matters. Given the noisy nature of the net, Applebot employs superior crawling methods to prioritize high-quality and various content material. Specifically, we targeted on capturing high-fidelity HTML pages, which enrich the dataset with each textual content and structured metadata for aligning media with the encompassing textual content content material. To enhance relevance and high quality, the system leveraged a number of indicators, together with domain-level language identification, subject distribution evaluation, and URL path sample heuristics.
We took particular care to precisely extract the content material from paperwork and fashionable web sites. We enhanced our doc assortment with headless rendering, enabling full-page loading, dynamic content material interplay, and JavaScript execution, that are vital for extracting information from net architectures. For web sites that rely on dynamic content material and person interactions, we enabled full web page loading and interplay simulation to reliably extract significant info from complicated pages. We additionally integrated giant language fashions (LLMs) into our extraction pipeline, notably for domain-specific paperwork, as they typically outperformed conventional rule-based strategies.
Along with superior crawling methods, we considerably expanded the size and variety of our coaching information, and integrated a bigger quantity of high-quality general-domain, mathematical, and programming content material. We additionally prolonged our multilingual assist to new languages that will probably be obtainable later this 12 months.
We consider that high-quality filtering performs a vital position in total mannequin efficiency. We’ve refined our information filtering pipeline by decreasing our reliance on overly aggressive heuristic guidelines and incorporating extra model-based filtering strategies. By introducing model-informed indicators, we had been in a position to retain extra informative content material, leading to a bigger and higher-quality pre-training dataset.
Picture Knowledge
To reinforce our fashions and allow visible understanding capabilities for Apple Intelligence options, we launched picture information into the pre-training pipeline, leveraging high-quality licensed information together with publicly obtainable picture information.
Utilizing our net crawling technique, we sourced pairs of pictures with corresponding alt-texts. Along with filtering for authorized compliance, we filtered for information high quality, together with image-text alignment. After de-duplication, this course of yielded over 10B high-quality image-text pairs. As well as, we created image-text interleaved information by preserving pictures of their initially noticed textual content context from crawled paperwork. After filtering for high quality and authorized compliance, this resulted in 175M interleaved image-text paperwork, containing over 550M pictures. Since web-crawled image-text pairs are typically quick and sometimes do not comprehensively describe visible particulars in pictures, we used artificial picture captioning information to supply richer descriptions. We developed an in-house picture captioning mannequin able to offering high-quality captions at completely different ranges of element, starting from key phrases to a paragraph-level complete description, producing over 5B image-caption pairs that we used throughout the pre-training phases.
To enhance our fashions’ text-rich visible understanding capabilities, we curated varied units of text-rich information, together with PDFs, paperwork, manuscripts, infographics, tables, and charts by way of licensed information, net crawling, and in-house synthesis. We then extracted the texts and generated each transcriptions and question-answer pairs from the picture information.
We curated quite a lot of sorts of image-text information:
- Excessive-quality caption information and grounded captions: We employed Contrastive Language-Picture Pre-training (CLIP) fashions and Optical Character Recognition (OCR) instruments as filters to acquire high-quality pictures from the aforementioned artificial picture caption information. Then, we utilized an in-house grounding mannequin to localize the nouns within the captions and append the coordinates after the nouns to kind grounded captions.
- Tables, charts, and plots: For charts and plots, we first prompted an inner LLM to generate artificial information fields and corresponding values, then requested the LLM to write down code that may generate varied sorts of charts and plots based mostly on the previously-synthesized information samples. Lastly, we fed the charts, plots, and information samples right into a trainer mannequin to generate QAs for mannequin coaching. For tables, we parsed the tables from publicly obtainable web sites and transformed them into markdown, then used each the image-markdown pairs and image-synthetic QAs generated by a trainer mannequin for mannequin coaching.
Pre-Coaching
Our pre-training recipe has advanced to scale Apple Intelligence capabilities to assist extra languages in addition to a wider array of options, together with people who require picture understanding.
Pre-training was performed in a number of phases, the place the primary and most compute-intensive stage focused the textual content modality solely. We skilled the on-device mannequin utilizing a distillation loss, however as a substitute of using a big dense mannequin because the trainer and pre-training it from scratch, we sparse-upcycled a 64-expert, every-2-layer mixture-of-experts (MoE) from a pre-trained ~3B mannequin utilizing a small quantity of our highest-quality textual content information. This diminished the price of coaching the trainer mannequin by 90%. Nonetheless, we skilled the sparse server mannequin from scratch on 14T textual content tokens.
With a purpose to higher assist new languages throughout this stage, we prolonged the textual content tokenizer from a vocabulary measurement of 100k to 150k, attaining illustration high quality for a lot of extra languages with simply 25% extra tokens. And to allow visible notion, we skilled each the on-device and server visible encoders utilizing a CLIP-style contrastive loss to align 6B image-text pairs, leading to an encoder with good visible grounding.
Within the second stage of pre-training, we skilled the visible encoders collectively with a vision-language adaption module utilizing a small mannequin decoder to align picture options with the mannequin’s illustration area utilizing high-quality textual content information, interleaved image-text information, and domain-specific image-text information. We then utilized these visible encoders and pre-trained fashions to enhance code, math, multilingual, long-context understanding, and to include picture understanding by way of a number of continued pre-training phases.
Within the phases of continued pre-training, we tailored the dataset combination ratios, whereas incorporating artificial information verified for correctness to enhance code, math, and multilingual capabilities. We then integrated visible understanding by way of multimodal adaptation with out damaging the textual content capabilities of the fashions. We skilled a vision-language adaptation module from scratch throughout this stage to attach the visible encoder to each fashions. Within the ultimate continued pre-training stage, we skilled the mannequin to deal with considerably longer context lengths utilizing sequences as much as 65K tokens, sampled from naturally occurring long-form information, artificial long-form information designed to focus on particular capabilities, and blended information from earlier rounds of pre-training.
Submit-Coaching
Just like our method for pre-training, we advanced our post-training course of to assist language enlargement and visible understanding.
We scaled our Supervised Fantastic-Tuning (SFT) by combining human-written demonstrations and artificial information, with an emphasis on core imaginative and prescient capabilities. This included normal information, reasoning, text-rich picture understanding, textual content and visible grounding, and multi-image reasoning. We additional bootstrapped the variety of imaginative and prescient SFT information by retrieving extra pictures and synthesizing their corresponding prompts and responses.
We utilized this SFT stage to additional allow tool-use and multilingual assist. We designed a process-supervision annotation technique, the place annotators issued a question to a tool-use agent platform, returning the platform’s total trajectory, together with the device invocation particulars, corresponding execution responses, and the ultimate response. This allowed the annotator to examine the mannequin’s predictions and proper errors, yielding a tree-structured dataset to make use of for instructing. To broaden to extra languages, we matched the output language to the enter language by default, however we additionally enabled the choice to make use of completely different languages for prompts and responses by creating a various dataset with blended languages.
We utilized Reinforcement Studying from Human Suggestions (RLHF) after the SFT stage for each the on-device mannequin and the server mannequin. In the meantime, we proposed a novel immediate choice algorithm based mostly on reward variance of the fashions’ a number of generations to curate the immediate dataset for RLHF coaching. Our evaluations confirmed vital features with RLHF for each human and auto benchmarks. And, whereas we launched multilingual information in each the SFT and RLHF phases, we discovered that RLHF supplied vital carry over SFT, resulting in a 16:9 win/loss fee in human evaluations.
To proceed to enhance our fashions’ high quality on multilingual efficiency, we used the Instruction Following eval (IFEval) and Alpaca Evals with GPT-4o as a choose. We collected 1000 prompts in every supported language written by native audio system. With cautious immediate tuning, we achieved good alignment between auto evals and human evals, enabling sooner iteration.
Optimizations
Over the previous 12 months, we now have expanded Apple Intelligence capabilities and made high quality enhancements whereas rising inference effectivity and decreasing energy consumption of our on-device and server fashions.
We compressed the on-device mannequin to 2 bits per weight (bpw) utilizing Quantization-Conscious-Coaching (QAT) with a novel mixture of learnable weight clipping and weight initialization. The server mannequin was compressed utilizing a block-based texture compression technique referred to as Adaptive Scalable Texture Compression (ASTC), which whereas initially developed for graphics pipelines, we’ve discovered to be efficient for mannequin compression as properly. ASTC decompression was applied with a devoted {hardware} part in Apple GPUs that enables the weights to be decoded with out introducing extra compute overhead.
For each fashions, we quantized the embedding desk to 4 bits per weight—utilizing joint coaching with the bottom weights utilizing QAT for the on-device mannequin, and post-training quantization for the server mannequin. The KV cache was quantized to eight bits per weight. We then skilled low-rank adapters utilizing extra information with a purpose to get well the standard misplaced as a result of these compression steps. With these strategies, we observe some slight high quality regressions and even minor enhancements, e.g. a ~4.6% regression on MGSM and a 1.5% enchancment on MMLU for the on-device mannequin, and a 2.7% MGSM and a pair of.3% MMLU regression for the server mannequin.
| On-Gadget | Server | |
|---|---|---|
| Decoder Weights | 2-bpw by way of QAT | 3.56-bpw by way of ASTC |
| Embedding | 4-bit by way of QAT | 4-bit put up coaching |
| KV Cache | 8-bit | 8-bit |
| Adapter restoration | Sure | Sure |
Basis Fashions Framework
The brand new Basis Fashions framework provides entry to builders to start out creating their very own dependable, production-quality generative AI options with the ~3B parameter on-device language mannequin. The ~3B language basis mannequin on the core of Apple Intelligence excels at a various vary of textual content duties, like summarization, entity extraction, textual content understanding, refinement, quick dialog, producing inventive content material, and extra. It isn’t designed to be a chatbot for normal world information. We encourage app builders to make use of this framework to construct useful options tailor-made to their apps.
The spotlight of our framework is an intuitive Swift method to constrained decoding known as guided era. With guided era, builders work immediately with wealthy Swift information buildings by including a @Generable macro annotation to Swift structs or enums. This works due to vertical integration with the mannequin, the working system, and the Swift programming language. It begins with the Swift compiler macros, which translate developer-defined sorts right into a standardized output format specification. When prompting the mannequin, the framework injects the response format into the immediate, and the mannequin is ready to perceive and cling to it due to post-training on a particular dataset designed with the guided era specification. Subsequent, an OS daemon employs extremely optimized, complementary implementations of constrained decoding and speculative decoding to spice up inference pace whereas offering sturdy ensures that the mannequin’s output conforms to the anticipated format. Based mostly on these ensures, the framework is ready to reliably create cases of Swift sorts from the mannequin output. This streamlines the developer expertise by letting app builders write a lot less complicated code, backed by the Swift sort system.
Device calling affords builders the facility to customise the ~3B mannequin’s talents by creating instruments that present the mannequin with particular sorts of knowledge sources or companies.
The framework’s method to device calling builds on guided era. The developer gives an implementation of the easy Device Swift protocol, and the framework routinely and optimally handles the possibly complicated name graphs of parallel and serial device calls. Mannequin post-training on tool-use information improved the mannequin’s reliability for this framework function.
We have fastidiously designed the framework to assist app builders get the many of the on-device mannequin. For specialised use circumstances that require instructing the ~3B mannequin solely new expertise, we additionally present a Python toolkit for coaching rank 32 adapters. Adapters produced by the toolkit are absolutely appropriate with the Basis Fashions framework. Nonetheless, adapters have to be retrained with every new model of the bottom mannequin, so deploying one ought to be thought of for superior use circumstances after totally exploring the capabilities of the bottom mannequin.
Analysis
We performed high quality evaluations of our on-device and server-based fashions offline utilizing human graders. We consider alongside normal elementary language and reasoning capabilities, together with Analytical Reasoning, Brainstorming, Chat, Classification, Closed Query and Answering, Coding, Artistic Writing, Extraction, Mathematical Reasoning, Open Query and Answering, Rewriting, Summarization, and Device-use.
As we expanded our mannequin assist to extra languages and locales, we expanded our analysis activity set to be locale-specific. Human graders assessed the mannequin’s capability to provide a response that was native-sounding to a person in that locale. For instance, a mannequin responding to an English sports activities query from a person in Nice Britain is predicted to know “soccer” is a extra domestically acceptable time period than “soccer”. Graders might flag the mannequin’s response for quite a lot of points, together with unlocalized phrases or unnatural phrases. Locale-specific evaluations used related classes because the English US locale, besides they excluded technical domains like math and coding that are largely inherently locale agnostic.
We discovered that our on-device mannequin performs favorably towards the marginally bigger Qwen-2.5-3B throughout all languages and is aggressive towards the bigger Qwen-3-4B and Gemma-3-4B in English. Our server-based mannequin performs favorably towards Llama-4-Scout, whose complete measurement and lively variety of parameters are similar to our server mannequin, however is behind bigger fashions comparable to Qwen-3-235B and the proprietary GPT-4o.
Human Analysis of Textual content Responses
With our mannequin assist increasing to the picture modality, an analysis set of Picture-Query pairs was used to evaluate Picture Understanding capabilities. This analysis set contained related classes because the textual content analysis set, together with image-specific classes like Infographics, which problem the mannequin to cause about text-rich pictures. We in contrast the on-device mannequin to imaginative and prescient fashions of comparable measurement, specifically InternVL-2.5-4B, Qwen-2.5-VL-3B-Instruct, and Gemma-3-4B, and our server mannequin to Llama-4-Scout, Qwen-2.5-VL-32B, and GPT–4o. We discovered that Apple’s on-device mannequin performs favorably towards the bigger InternVL and Qwen and competitively towards Gemma, and our server mannequin outperforms Qwen-2.5-VL, at lower than half the inference FLOPS, however is behind Llama-4-Scout and GPT–4o.
Human Analysis of Picture Responses
Along with evaluating the bottom mannequin for generalist capabilities, feature-specific analysis on adaptors can also be carried out. For instance, contemplate the adaptor-based Visible Intelligence function that creates a calendar occasion from a picture of a flyer. An analysis set of flyers was collected throughout a broad vary of environmental settings, digital camera angles, and different difficult eventualities. This was used to evaluate the mannequin’s capability to precisely extract info from the flyer, together with the date and placement, to correctly create the calendar occasion.
Accountable AI
Apple Intelligence is designed with our core values at each step and constructed on a basis of industry-leading privateness safety. Moreover, we now have created our Accountable AI ideas to information how we develop AI instruments, in addition to the fashions that underpin them. These ideas are mirrored at each stage of the structure that permits Apple Intelligence and connects options and instruments with specialised fashions:
- Empower customers with clever instruments: We establish areas the place AI can be utilized responsibly to create instruments for addressing particular person wants. We respect how our customers select to make use of these instruments to perform their targets.
- Symbolize our customers: We construct deeply private merchandise with the objective of representing customers across the globe authentically. We work repeatedly to keep away from perpetuating stereotypes and systemic biases throughout our AI instruments and fashions.
- Design with care: We take precautions at each stage of our course of, together with design, mannequin coaching, function improvement, and high quality analysis to establish how our AI instruments could also be misused or result in potential hurt. We are going to repeatedly monitor and proactively enhance our AI instruments with the assistance of person suggestions.
- Defend privateness: We defend our customers’ privateness with highly effective on-device processing and groundbreaking infrastructure like Non-public Cloud Compute. We don’t use our customers’ personal private information or person interactions when coaching our basis fashions.
These ideas information our work all through the product improvement cycle, informing our product design, insurance policies, evaluations, and mitigations. As a part of Apple’s dedication to accountable AI, we have continued to establish and mitigate the dangers inherent to using basis fashions, comparable to hallucinations and susceptibility to immediate injections. Our security taxonomy helps us establish delicate content material that ought to be dealt with with care.
To guage the security of Apple Intelligence, we assessed each the inspiration fashions in addition to every function that makes use of the fashions previous to deployment. For basis fashions, we mixed inner and exterior human analysis with auto-grading, and in contrast our fashions to exterior fashions for benchmarking. We constructed focused security analysis datasets to evaluate the efficiency of the inspiration fashions on duties comparable to summarization, question-answering, and brainstorming, because it applies to high-risk and delicate content material. For particular person options, we designed datasets that concentrate on user-facing dangers to particularly establish undesirable or unintended outcomes, in addition to to check any impacts that high quality points could trigger when utilized to delicate app-specific content material. For instance, we took care in designing the brand new Basis Fashions framework and supporting sources to assist enhance generative AI security for apps. The framework enforces a base stage of security with built-in security guardrails to mitigate dangerous mannequin enter and output. To assist app designers and builders incorporate AI security that’s tailor-made to their apps, we created instructional sources, comparable to new Generative AI Human Interface Tips for Accountable AI ideas.
As we expanded our options to new languages, we expanded our security illustration throughout areas and cultures, and we now have continued to make enhancements to account for the large cultural and linguistic variety of our customers. Along with adhering to native legal guidelines and rules, we leveraged a mixture of high-quality exterior consultant information sources, engaged with inner and exterior authorized, language, and cultural specialists, in addition to reviewed precedents from earlier product selections to make sure that our method was contextually respectful and related. To design our mitigation steps for multilingual use, we started with multilingual post-training alignment on the foundational mannequin stage, then prolonged to feature-specific adapters that combine security alignment information. Moreover, we expanded our guardrail fashions, designed to intercept dangerous prompts, with language-specific coaching information whereas sustaining a multilingual adapter. We developed custom-made datasets to mitigate culture-specific dangers and biases and stereotypes in mannequin outputs. Equally, we prolonged our analysis datasets throughout languages and locales with instruments comparable to machine translation and focused artificial information era, all refined by native audio system. Lastly, we performed human purple teaming throughout options to establish dangers distinctive to every locale.
We repeatedly monitor and proactively enhance our options with the assistance of person suggestions. In Picture Playground, for instance, customers can present suggestions on generated pictures by tapping “thumbs up” or “thumbs down”, with the choice so as to add feedback. App builders can equally supply suggestions by way of Suggestions Assistant. Suggestions from customers and builders, together with analysis information and different metrics, helps us repeatedly enhance Apple Intelligence options and fashions.
Conclusion
We’re excited to make the language basis fashions on the core of Apple Intelligence extra environment friendly and extra succesful, unlocking a variety of useful options built-in throughout our software program platforms, and obtainable to our customers across the globe throughout many languages. We’re additionally giving app builders direct entry to our on-device language basis mannequin with a brand new Basis Fashions framework. App builders can reap the benefits of AI inference that is freed from price and accessible with just some traces of code, and convey capabilities comparable to textual content extraction and summarization to their apps with just some traces of code. Our newest basis fashions are constructed with our core values at each step, like our dedication to privateness, in addition to our Accountable AI method. We look ahead to sharing extra particulars on updates to our language basis fashions in a future technical report.