
Producing high-quality customized movies stays a major problem, as a result of video technology fashions are restricted to their pre-trained information. This limitation impacts industries akin to promoting, media manufacturing, schooling, and gaming, the place customization and management of video technology is crucial.
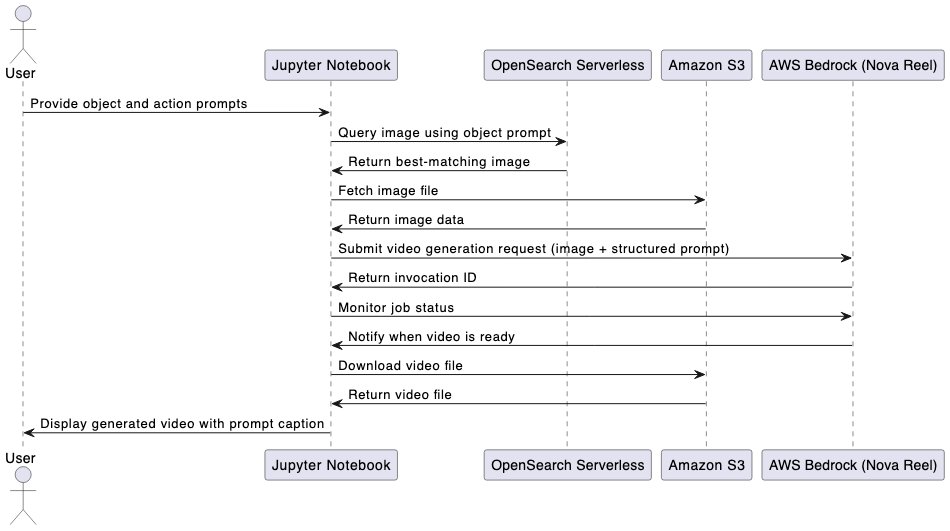
To deal with this, we developed a Video Retrieval Augmented Technology (VRAG) multimodal pipeline that transforms structured textual content into bespoke movies utilizing a library of photos as reference. Utilizing Amazon Bedrock, Amazon Nova Reel, the Amazon OpenSearch Service vector engine, and Amazon Easy Storage Service (Amazon S3), the answer seamlessly integrates picture retrieval, prompt-based video technology, and batch processing right into a single automated workflow. Customers present an object of curiosity, and the answer retrieves essentially the most related picture from an listed dataset. They then outline an motion immediate (for instance, “Digicam rotates clockwise”), which is mixed with the retrieved picture to generate the video. Structured prompts from textual content information permit a number of movies to be generated in a single execution, making a scalable, reusable basis for AI-assisted media technology.
On this publish, we discover our strategy to video technology via VRAG, remodeling pure language textual content prompts and pictures into grounded, high-quality movies. By way of this absolutely automated resolution, you may generate real looking, AI-powered video sequences from structured textual content and picture inputs, streamlining the video creation course of.
Answer overview
Our resolution is designed to take a structured textual content immediate, retrieve essentially the most related picture, and use Amazon Nova Reel for video technology. This resolution integrates a number of parts right into a seamless workflow:
- Picture retrieval and processing – Customers present an object of curiosity (for instance, “blue sky”) and the answer queries the OpenSearch vector engine to retrieve essentially the most related picture from an listed dataset, which incorporates pre-indexed photos and descriptions. Essentially the most related picture is retrieved from an S3 bucket.
- Immediate-based video technology – Customers outline an motion immediate (for instance, “Digicam pans down”), which is mixed with the retrieved picture to generate a video utilizing Amazon Nova Reel.
- Batch processing for a number of prompts – The answer reads a listing of textual content templates from
prompts.txt, which include placeholders to allow batch processing of a number of video technology requests with structured variations:– Dynamically changed with the queried object. – Dynamically changed with the digicam motion or scene motion.
- Monitoring and storage – The video technology is asynchronous, so the answer screens the job standing. When it’s full, the video is saved in an S3 bucket and mechanically downloaded for preview. The generated movies are displayed within the pocket book, with the corresponding immediate proven as a caption.
The next diagram illustrates the answer structure.
The next diagram illustrates the end-to-end workflow utilizing a Jupyter pocket book.
This resolution can serve the next use circumstances:
- Instructional movies – Mechanically creating educational movies by pulling related photos from a topic information base
- Advertising movies – Creating focused video advertisements by pulling photos that align with particular demographics or product options
- Personalised content material – Tailoring video content material to particular person customers by retrieving photos primarily based on their particular pursuits
Within the following sections, we break down every part, the way it works, and how one can customise it in your personal AI-driven video workflows.
Instance enter
On this part, we display the video technology capabilities of Amazon Nova Reel via two distinct enter strategies: text-only and textual content and picture inputs. These examples illustrate how video technology might be additional custom-made by incorporating enter photos, on this state of affairs for promoting. For our instance, a journey company needs to create an commercial that includes a good looking seashore scene from a particular location and panning to a kayak to entice potential trip bookings. We examine the outcomes of utilizing a text-only enter strategy vs. VRAG with a static picture to realize this objective.
Textual content-only enter
For the text-only instance, we use the enter “Very sluggish pan down from blue sky to a colourful kayak floating on turquoise water.” We get the next end result.

Textual content and picture enter
Utilizing the identical textual content immediate, the journey company can now use a particular shot they took at their location. For this instance, we use the next picture.

Journey company can now add content material into their current shot utilizing VRAG. They use the identical immediate: “Very sluggish pan down from blue sky to a colourful kayak floating on turquoise water.” This generates the next video.

Stipulations
Earlier than you deploy this resolution, be sure the next stipulations are in place:
Deploy the answer
For this publish, we use an AWS CloudFormation template to deploy the answer within the US East (N. Virginia) AWS Area. For a listing of Areas that help Amazon Nova Reel, see Mannequin help by AWS Area in Amazon Bedrock. Full the next steps:
- Select Launch Stack to deploy the stack:
![]()
- Enter a reputation for the stack, akin to
vrag-blogpost, and observe the steps to deploy. - On the CloudFormation console, find the
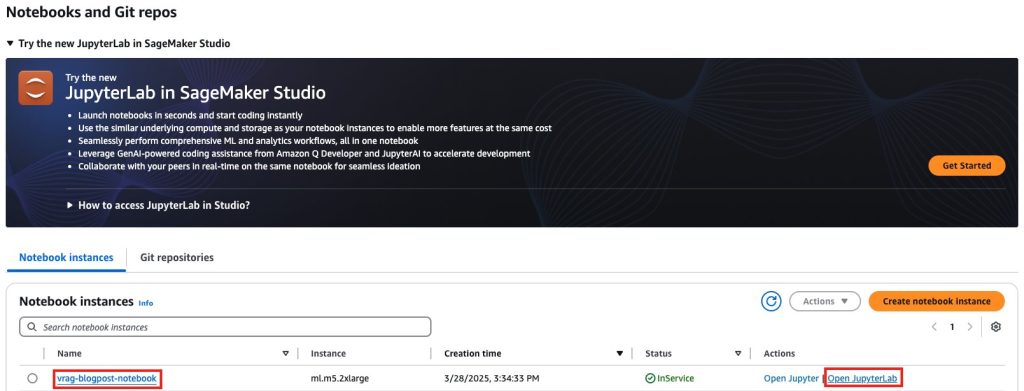
vrag-blogpoststack and make sure that its standing is CREATE_COMPLETE. - On the SageMaker AI console, select Notebooks within the navigation pane.
- On the Pocket book situations tab, find the pocket book occasion
vrag-blogpost-notebookprovisioned for this publish and selected Open JupyterLab.
- Open the folder
sample-video-ragto view the notebooks wanted for this publish.
Run notebooks
We now have offered seven sequential notebooks, numbered from _00 to _06, with step-by-step directions and goals that can assist you construct your understanding of a VRAG resolution. Your output would possibly fluctuate from the examples on this publish.
Picture processing (pocket book _00)
In _00_image_processing, you utilize Amazon Bedrock, Amazon S3, and SageMaker AI to carry out the next actions:
- Course of and resize photos
- Generate Base64 encodings
- Retailer information in Amazon S3
- Generate picture descriptions utilizing Amazon Nova
- Create a visualization of the outcomes
This pocket book illustrates the next capabilities:
- Automated processing pipeline:
- Bulk picture processing
- Clever resizing and optimization
- Base64 encoding for API compatibility
- Amazon S3 storage of photos
- AI-powered evaluation:
- Superior picture description technology
- Content material-based picture understanding
- Multi-modal AI integration
- Sturdy information administration:
- Environment friendly storage group
- Metadata extraction and indexing
For this instance, we use the next enter picture.

We obtain the next generated picture caption as output: “The picture encompasses a brown purse with white floral patterns, a straw hat with a blue ribbon, and a bottle of fragrance. The purse is positioned on a floor, and the straw hat is positioned subsequent to it. The purse has a strap and a series connected to it, and the straw hat has a blue ribbon tied round it. The fragrance bottle is positioned subsequent to the purse.”
Picture ingestion (pocket book _01)
In _01_oss_ingestion.ipynb, you utilize Amazon Bedrock (with Amazon Titan Embeddings to generate embeddings), Amazon S3, OpenSearch Serverless (for vector storage and search), and SageMaker AI (for pocket book internet hosting) to carry out the next actions:
- Course of and resize photos
- Generate base64 encodings
- Retailer information in Amazon S3
- Generate picture descriptions utilizing Amazon Nova
- Create visualization of the outcomes
This pocket book illustrates the next capabilities:
- Vector database administration:
- Index creation and configuration
- Bulk information ingestion
- Environment friendly vector storage
- Embedding technology:
- Multi-modal embedding creation
- Dimension optimization
- Batch processing help
- Semantic search capabilities:
- k-NN search implementation
- Question vector technology
- End result visualization
For our enter, we use the question “Constructing” and obtain the next picture because of this.

The picture has the related caption as output: “The picture depicts a contemporary architectural scene that includes a number of high-rise buildings with glass facades. The buildings are constructed with a mixture of glass and metal, giving them a smooth and modern look. The glass panels replicate the encompassing setting, together with the sky and different buildings, making a dynamic interaction of sunshine and reflections. The sky above is partly cloudy, with patches of blue seen, suggesting a transparent day with some cloud cowl. The buildings are tall and slender, with vertical strains emphasised by the construction of the glass panels and metal framework. The reflections on the glass surfaces present the encompassing buildings and the sky, including depth to the picture. The general impression is considered one of modernity, effectivity, and concrete sophistication.”
Video technology from textual content solely (pocket book _02)
In _02_video_gen_text_only.ipynb, you utilize Amazon Bedrock (to entry Amazon Nova Reel) and SageMaker AI (for pocket book internet hosting) to carry out the next actions:
- Assemble the request payload for video technology with textual content as immediate
- Provoke an asynchronous job utilizing Amazon Bedrock
- Monitor progress and wait till completion
- Retrieve the generated video from Amazon S3 and render it within the pocket book
This pocket book illustrates the next capabilities:
- Automated processing of video technology with textual content as enter
- Video technology at scale with observability
We use the next enter immediate: “Closeup of a big seashell within the sand, light waves move across the shell. Digicam zoom in.”We obtain the next generated video as output.

Video technology from textual content and picture prompts (pocket book _03)
In _03_video_gen_text_image.ipynb, you utilize Amazon Bedrock (to entry Amazon Nova Reel) and SageMaker AI (for pocket book internet hosting) to carry out the next actions:
- Assemble the request payload for video technology with textual content and picture as immediate
- Provoke an asynchronous job utilizing Amazon Bedrock
- Monitor progress and wait till completion
- Retrieve the generated video from Amazon S3 and render it within the pocket book
This pocket book illustrates the next capabilities:
- Automated processing of video technology with textual content and picture as enter
- Video technology at scale with observability
We use the immediate “digicam tilt up from the street to the sky” and the next picture as enter.

We obtain the next generated video as output.

Video technology from multi-modal inputs (pocket book _04)
In _04_video_gen_multi.ipynb, you utilize Amazon Bedrock (to entry Amazon Nova Reel) and SageMaker AI (for pocket book internet hosting) to carry out the next actions:
- Generate embedding for enter immediate and search the OpenSearch Serverless vector assortment index
- Mix textual content and retrieved photos to generate movies
This pocket book illustrates the next capabilities:
- The VRAG course of
- Video technology at scale with observability
We use the next immediate as enter: “A clear cinematic shot of pink footwear positioned below falling snow, whereas the setting stays silent and nonetheless.”We obtain the next video as output.

Replace photos with in-painting (pocket book _05)
In _05_inpainting.ipynb, you utilize Amazon Bedrock (to entry Amazon Nova Reel) and SageMaker AI (for pocket book internet hosting) to carry out the next actions:
- Learn base 64 picture
- Generate photos with in-painting
This pocket book illustrates the next capabilities:
- Exchange and choose areas of a picture primarily based on surrounding context and prompts
- Take away undesirable objects and repair parts of photos or creatively modify particular areas of a picture
Generate movies with enhanced photos (pocket book _06)
In _06_video_gen_inpainting.ipynb, you utilize Amazon Bedrock (to entry Amazon Nova Reel) and SageMaker AI (for pocket book internet hosting) to carry out the next actions:
- Seek for related photos in OpenSearch Service utilizing pure language queries
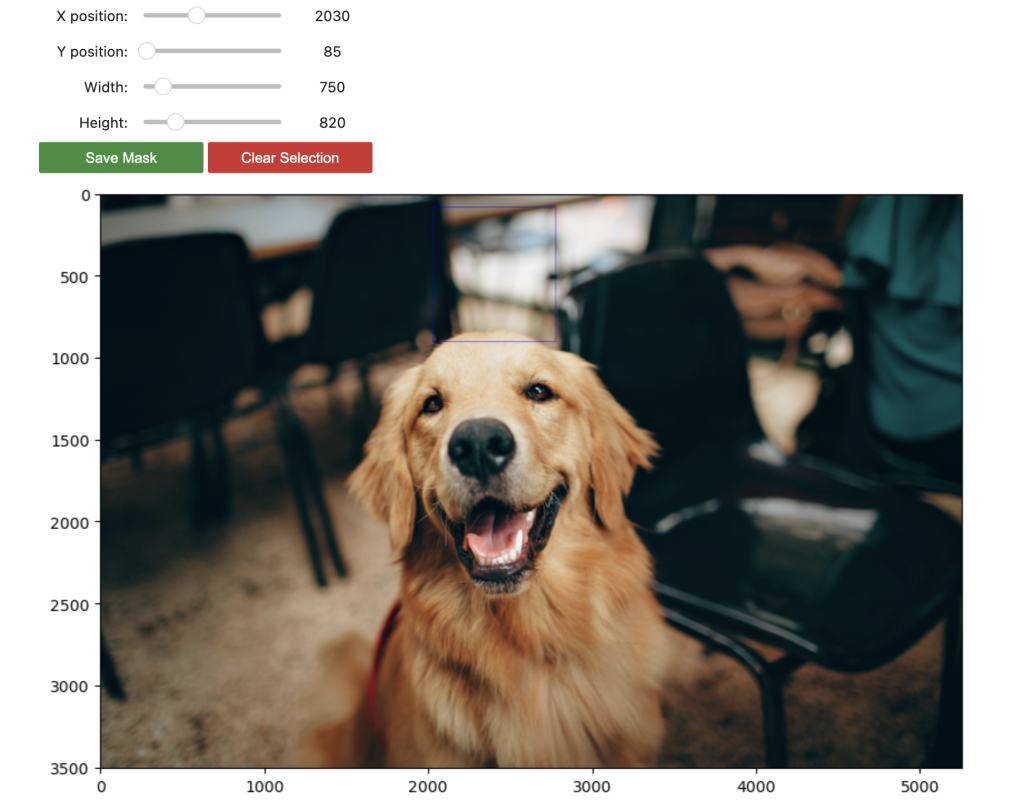
- Use specific picture masks to outline areas for in-painting
- Generate movies utilizing enhanced photos
This pocket book illustrates the next capabilities:
- Use in-painting to generate a picture
- Generate a video utilizing the improved picture
The next screenshot reveals the picture and masks we use for in-painting.
The next screenshot reveals the generated photos (few-shot) we obtain as output.

From the generated picture, we obtain the next video as output.

Finest practices
An environment friendly AI video technology course of requires seamless integration of knowledge administration, search optimization, and compliance measures. The method should deal with high-quality enter information whereas sustaining optimized OpenSearch queries and Amazon Bedrock integration for dependable processing. Correct Amazon S3 administration and enhanced consumer expertise options facilitate easy operation, and strict adherence to EU AI Act pointers maintains regulatory compliance.
For optimum implementation in manufacturing environments, think about these key components:
- Knowledge high quality – The standard of the generated video is closely depending on the standard and relevance of the picture database utilized in RAG
- Picture captioning – For optimum outcomes, think about incorporating picture captions or metadata to supply extra context for the RAG resolution
- Video modifying – Though RAG can present the core visible components, extra video modifying strategies is perhaps required to create a cultured ultimate product
Clear up
To keep away from incurring future fees, clear up the sources created on this publish.
- Empty the S3 bucket created by the CloudFormation stack. On the Amazon S3 console, choose the bucket, select Empty, and make sure the deletion.
- On the AWS CloudFormation console, choose the vrag-blogpost stack, select Delete, and make sure. This removes all provisioned sources, together with the SageMaker pocket book occasion, OpenSearch Serverless assortment, and IAM roles.
Conclusion
VRAG represents a major development in AI-powered video creation, seamlessly integrating current picture databases with consumer prompts to provide contextually related video content material. This resolution demonstrates highly effective functions throughout schooling, advertising, leisure, and past. As video technology know-how continues to evolve, VRAG gives a sturdy basis for creating partaking, context-aware video content material at scale. By following these greatest practices and sustaining deal with information high quality, organizations can use this know-how to remodel their video content material creation processes whereas producing constant, high-quality outputs. Check out VRAG for your self with the notebooks offered on this publish, and share your suggestions within the feedback part.
Concerning the Authors
 Nick Biso is a Machine Studying Engineer at AWS Skilled Providers. He solves advanced organizational and technical challenges utilizing information science and engineering. As well as, he builds and deploys AI/ML fashions on the AWS Cloud. His ardour extends to his proclivity for journey and numerous cultural experiences.
Nick Biso is a Machine Studying Engineer at AWS Skilled Providers. He solves advanced organizational and technical challenges utilizing information science and engineering. As well as, he builds and deploys AI/ML fashions on the AWS Cloud. His ardour extends to his proclivity for journey and numerous cultural experiences.
 Madhunika Mikkili is a Knowledge and Machine Studying Engineer at AWS. She is keen about serving to prospects obtain their targets utilizing information analytics and machine studying.
Madhunika Mikkili is a Knowledge and Machine Studying Engineer at AWS. She is keen about serving to prospects obtain their targets utilizing information analytics and machine studying.
 Shuai Cao is a Senior Utilized Science Supervisor targeted on generative AI at Amazon Net Providers. He leads groups of knowledge scientists, machine studying engineers, and utility architects to ship AI/ML options for patrons. Outdoors of labor, he enjoys composing and arranging music.
Shuai Cao is a Senior Utilized Science Supervisor targeted on generative AI at Amazon Net Providers. He leads groups of knowledge scientists, machine studying engineers, and utility architects to ship AI/ML options for patrons. Outdoors of labor, he enjoys composing and arranging music.
 Seif Elharaki is a Senior Cloud Utility Architect who focuses on constructing AI/ML functions for the manufacturing vertical. He combines his experience in cloud applied sciences with a deep understanding of business processes to create modern options. Outdoors of labor, Seif is an enthusiastic hobbyist sport developer, having fun with coding enjoyable video games utilizing instruments like Unreal Engine and Unity.
Seif Elharaki is a Senior Cloud Utility Architect who focuses on constructing AI/ML functions for the manufacturing vertical. He combines his experience in cloud applied sciences with a deep understanding of business processes to create modern options. Outdoors of labor, Seif is an enthusiastic hobbyist sport developer, having fun with coding enjoyable video games utilizing instruments like Unreal Engine and Unity.
 Vishwa Gupta is a Principal Guide with AWS Skilled Providers. He helps prospects implement generative AI, machine studying, and analytics options. Outdoors of labor, he enjoys spending time with household, touring, and attempting new meals.
Vishwa Gupta is a Principal Guide with AWS Skilled Providers. He helps prospects implement generative AI, machine studying, and analytics options. Outdoors of labor, he enjoys spending time with household, touring, and attempting new meals.
 Raechel Frick is a Sr Product Advertising Supervisor for Amazon Nova. With over 20 years of expertise within the tech trade, she brings a customer-first strategy and progress mindset to constructing built-in advertising packages. Based mostly within the higher Seattle space, Raechel balances her skilled life with being a soccer mother and cheerleading coach.
Raechel Frick is a Sr Product Advertising Supervisor for Amazon Nova. With over 20 years of expertise within the tech trade, she brings a customer-first strategy and progress mindset to constructing built-in advertising packages. Based mostly within the higher Seattle space, Raechel balances her skilled life with being a soccer mother and cheerleading coach.
 Maria Masood focuses on agentic AI, reinforcement fine-tuning, and multi-turn agent coaching. She has experience in Machine Studying, spanning giant language mannequin customization, reward modeling, and constructing end-to-end coaching pipelines for AI brokers. A sustainability fanatic at coronary heart, Maria enjoys gardening and making lattes.
Maria Masood focuses on agentic AI, reinforcement fine-tuning, and multi-turn agent coaching. She has experience in Machine Studying, spanning giant language mannequin customization, reward modeling, and constructing end-to-end coaching pipelines for AI brokers. A sustainability fanatic at coronary heart, Maria enjoys gardening and making lattes.