
Computerized speech recognition (ASR) has come a good distance. Although it was invented way back, it was hardly utilized by anybody. Nonetheless, time and know-how have now modified considerably. Audio transcription has considerably advanced.
Applied sciences corresponding to AI (Synthetic Intelligence) have powered the method of audio-to-text translation for fast and correct outcomes. Consequently, its purposes in the true world have additionally elevated, with some fashionable apps like Tik Tok, Spotify, and Zoom embedding the method into their cellular apps.
So allow us to discover ASR and uncover why it is without doubt one of the hottest applied sciences in 2022.
What’s speech to textual content?
Speech-to-text (STT), additionally known as automated speech recognition (ASR), converts spoken audio into written textual content. Trendy programs are software program companies that analyze audio alerts and output phrases with timestamps and confidence scores.
For groups constructing contact-center, healthcare, and voice UX, STT is the gateway to searchable, analyzable conversations, assistive captions, and downstream AI like summarization or QA.
Frequent Names of Speech to Textual content
This superior speech recognition know-how can be fashionable and referred to by the names:
- Computerized speech recognition (ASR)
- Speech recognition
- Pc speech recognition
- Audio transcription
- Display Studying
Purposes of speech-to-text know-how
Contact facilities
Actual-time transcripts energy dwell agent help; batch transcripts drive QA, compliance audits, and searchable name archives.
Instance: Use streaming ASR to floor real-time prompts throughout a billing dispute, then run batch transcription after the decision to attain QA and auto-generate the abstract.
Healthcare
Clinicians dictate notes and get go to summaries; transcripts assist coding (CPT/ICD) and medical documentation—all the time with PHI safeguards.
Instance: A supplier information a session, runs ASR to draft the SOAP be aware, and auto-highlights drug names and vitals for coder evaluation with PHI redaction utilized.
Media & schooling
Generate captions/subtitles for lectures, webinars, and broadcasts; add gentle human modifying if you want near-perfect accuracy.
Instance: A college transcribes lecture movies in batch, then a reviewer fixes names and jargon earlier than publishing accessible subtitles.
Voice merchandise & IVR
Wake-word and command recognition allow hands-free UX in apps, kiosks, automobiles, and sensible units; IVR makes use of transcripts to route and resolve.
Instance: A banking IVR acknowledges “freeze my card,” confirms particulars, and triggers the workflow—no keypad navigation required.
Operations & information
Conferences and subject calls grow to be searchable textual content with timestamps, audio system, and motion objects for teaching and analytics.
Instance: Gross sales calls are transcribed, tagged by subject (pricing, objections), and summarized; managers filter by “renewal threat” to plan follow-ups.
Why must you use speech to textual content?
- Make conversations discoverable. Flip hours of audio into searchable textual content for audits, coaching, and buyer insights.
- Automate handbook transcription. Scale back turnaround time and value versus human-only workflows, whereas retaining a human go the place high quality should be good.
- Energy downstream AI. Transcripts feed summarization, intent/subject extraction, compliance flags, and training.
- Enhance accessibility. Captions and transcripts assist customers with listening to loss and enhance UX in noisy environments.
- Assist real-time choices. Streaming ASR allows on-call steering, real-time kinds, and dwell monitoring.
Advantages of speech-to-text know-how
Velocity & mode flexibility
Streaming provides sub-second partials for dwell use; batch chews by way of backlogs with richer post-processing.
Instance: Stream transcripts for agent help; batch re-transcribe later for QA-quality archives.
High quality options in-built
Get diarization, punctuation/casing, timestamps, and phrase hints/customized vocabulary to deal with jargon.
Instance: Label Physician/Affected person turns and increase medicine names so that they transcribe accurately.
Deployment selection
Use cloud APIs for scale/updates or on-prem/edge containers for knowledge residency and low latency.
Instance: A hospital runs ASR in its knowledge heart to maintain PHI on-prem.
Customization & multilingual
Shut accuracy gaps with phrase lists and area adaptation; assist a number of languages and code-switching.
Instance: A fintech app boosts model names and tickers in English/Hinglish, then fine-tunes for area of interest phrases.
Comprehending the Working of Computerized Speech Recognition
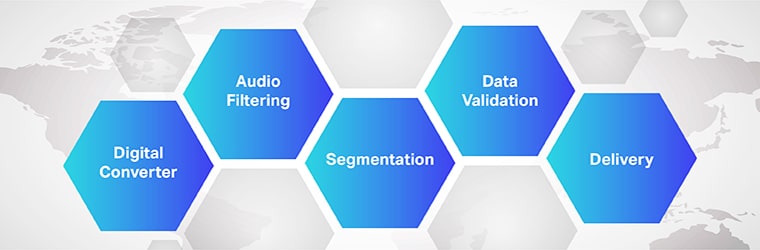
The working of audio-to-text translation software program is complicated and includes the implementation of a number of steps. As we all know, speech-to-text is an unique software program designed to transform audio recordsdata into an editable textual content format; it does it by leveraging voice recognition.
Course of
- Initially, utilizing an analog-to-digital converter, a pc program applies linguistic algorithms to the supplied knowledge to differentiate vibrations from auditory alerts.
- Subsequent, the related sounds are filtered by measuring the sound waves.
- Additional, the sounds are distributed/segmented into hundredths or thousandths of seconds and matched in opposition to phonemes (A measurable unit of sound to distinguish one phrase from one other).
- The phonemes are additional run by way of a mathematical mannequin to check the present knowledge with well-known phrases, sentences, and phrases.
- The output is in a textual content or computer-based audio file.
[Also Read: A Comprehensive Overview of Automatic Speech Recognition]
What are the Makes use of of Speech to Textual content?
There are a number of automated speech recognition software program makes use of, corresponding to
- Content material Search: Most of us have shifted from typing letters on our telephones to urgent a button for the software program to acknowledge our voice and supply the specified outcomes.
- Buyer Service: Chatbots and AI assistants that may information the shoppers by way of the few preliminary steps of the method have grow to be widespread.
- Actual-Time Closed Captioning: With elevated international entry to content material, closed captioning in real-time has grow to be a distinguished and important market, pushing ASR ahead for its use.
- Digital Documentation: A number of administration departments have began utilizing ASR to satisfy documentation functions, catering to raised pace and effectivity.
What are the Key Challenges to Speech Recognition?
Accents and dialects. The identical phrase can sound very totally different throughout areas, which confuses fashions skilled on “normal” speech. The repair is easy: accumulate and check with accent-rich audio, and add phrase/pronunciation hints for model, place, and individual names.
Context and homophones. Selecting the correct phrase (“to/too/two”) wants surrounding context and area information. Use stronger language fashions, adapt them with your individual area textual content, and validate essential entities like drug names or SKUs.
Noise and poor audio channels. Site visitors, crosstalk, name codecs, and far-field mics bury essential sounds. Denoise and normalize audio, use voice-activity detection, simulate actual noise/codecs in coaching, and like higher microphones the place you’ll be able to.
Code-switching and multilingual speech. Individuals usually combine languages or change mid-sentence, which breaks single-language fashions. Select multilingual or code-switch-aware fashions, consider on mixed-language audio, and keep locale-specific phrase lists.
A number of audio system and overlap. When voices overlap, transcripts blur “who mentioned what.” Allow speaker diarization to label turns, and use separation/beamforming if multi-mic audio is offered.
Video cues in recordings. In video, lip actions and on-screen textual content add that means that audio alone can miss. The place high quality issues, use audio-visual fashions and pair ASR with OCR to seize slide titles, names, and phrases.
Annotation and labeling high quality. Inconsistent transcripts, mistaken speaker tags, or sloppy punctuation undermine each coaching and analysis. Set a transparent type information, audit samples usually, and preserve a small gold set to measure annotator consistency.
Privateness and compliance. Calls and medical recordings can comprise PII/PHI, so storage and entry should be tightly managed. Redact or de-identify outputs, prohibit entry, and select cloud vs on-prem/edge deployments to satisfy your coverage.
How to decide on the perfect speech-to-text vendor
Decide a vendor by testing in your audio (accents, units, noise) and weighing accuracy in opposition to privateness, latency, and value. Begin small, measure, then scale.
Outline wants first
- Use circumstances: streaming, batch, or each
- Languages/accents (incl. code-switching)
- Audio channels: telephone (8 kHz), app/desktop, far-field
- Privateness/residency: PII/PHI, area, retention, audit
- Constraints: latency goal, SLA, price range, cloud vs on-prem/edge
Consider in your audio
- Accuracy: WER + entity accuracy (jargon, names, codes)
- Multi-speaker: diarization high quality (who spoke when)
- Formatting: punctuation, casing, numbers/dates
- Streaming: TTFT/TTF latency + stability
- Options: phrase lists, customized fashions, redaction, timestamps
Ask within the RFP
- Present uncooked outcomes on our check set (by accent/noise)
- Present p50/p95 streaming latency on our clips
- Diarization accuracy for two–3 audio system with overlap
- Information dealing with: in-region processing, retention, entry logs
- Path from phrase lists → customized mannequin (knowledge, time, value)
Look ahead to crimson flags
- Nice demo, weak outcomes in your audio
- “We’ll repair with fine-tuning” however no plan/knowledge
- Hidden charges for diarization/redaction/storage
[Also Read: Understanding the Collection Process of Audio Data for Automatic Speech Recognition]
The way forward for speech-to-text know-how
Larger multilingual “basis” fashions. Count on single fashions that cowl 100+ languages with higher low-resource accuracy, because of huge pre-training and light-weight fine-tuning.
Speech + translation in a single stack. Unified fashions will deal with ASR, speech-to-text translation, and even speech-to-speech—lowering latency and glue code.
Smarter formatting and diarization by default. Auto punctuation, casing, numbers, and dependable “who-spoke-when” labeling will more and more be built-in for each batch and streaming.
Audio-visual recognition for robust environments. Lip cues and on-screen textual content (OCR) will increase transcripts when audio is noisy—already a fast-moving analysis space and early product prototypes.
Privateness-first coaching and on-device/edge. Federated studying and containerized deployments will preserve knowledge native whereas nonetheless enhancing fashions—essential for regulated sectors.
Regulation-aware AI. EU AI Act timelines imply extra transparency, threat controls, and documentation baked into STT merchandise and procurement.
Richer analysis past WER. Groups will standardize on entity accuracy, diarization high quality, latency (TTFT/TTF), and equity throughout accents/units, not simply headline WER.
How Shaip helps you get there
As these tendencies land, success nonetheless hinges on your knowledge. Shaip provides accent-rich multilingual datasets, PHI-safe de-identification, and gold check units (WER, entity, diarization, latency) to pretty evaluate distributors and tune fashions—so you’ll be able to undertake the way forward for STT with confidence. Discuss to Shaip’s ASR knowledge consultants to plan a fast pilot.