
As organizations scale their use of generative AI, many workloads require cost-efficient, bulk processing quite than real-time responses. Amazon Bedrock batch inference addresses this want by enabling massive datasets to be processed in bulk with predictable efficiency—at 50% decrease price than on-demand inference. This makes it splendid for duties similar to historic information evaluation, large-scale textual content summarization, and background processing workloads.
On this put up, we discover the way to monitor and handle Amazon Bedrock batch inference jobs utilizing Amazon CloudWatch metrics, alarms, and dashboards to optimize efficiency, price, and operational effectivity.
New options in Amazon Bedrock batch inference
Batch inference in Amazon Bedrock is consistently evolving, and up to date updates convey vital enhancements to efficiency, flexibility, and price transparency:
- Expanded mannequin help – Batch inference now helps extra mannequin households, together with Anthropic’s Claude Sonnet 4 and OpenAI OSS fashions. For essentially the most up-to-date checklist, consult with Supported Areas and fashions for batch inference.
- Efficiency enhancements – Batch inference optimizations on newer Anthropic Claude and OpenAI GPT OSS fashions now ship greater batch throughput as in comparison with earlier fashions, serving to you course of massive workloads extra shortly.
- Job monitoring capabilities – Now you can observe how your submitted batch jobs are progressing straight in CloudWatch, with out the heavy lifting of constructing customized monitoring options. This functionality offers AWS account-level visibility into job progress, making it simple to handle large-scale workloads.
Use instances for batch inference
AWS recommends utilizing batch inference within the following use instances:
- Jobs are not time-sensitive and might tolerate minutes to hours of delay
- Processing is periodic, similar to every day or weekly summarization of enormous datasets (information, studies, transcripts)
- Bulk or historic information must be analyzed, similar to archives of name middle transcripts, emails, or chat logs
- Information bases want enrichment, together with producing embeddings, summaries, tags, or translations at scale
- Content material requires large-scale transformation, similar to classification, sentiment evaluation, or changing unstructured textual content into structured outputs
- Experimentation or analysis is required, for instance testing immediate variations or producing artificial datasets
- Compliance and threat checks have to be run on historic content material for delicate information detection or governance
Launch an Amazon Bedrock batch inference job
You can begin a batch inference job in Amazon Bedrock utilizing the AWS Administration Console, AWS SDKs, or AWS Command Line Interface (AWS CLI). For detailed directions, see Create a batch inference job.
To make use of the console, full the next steps:
- On the Amazon Bedrock console, select Batch inference beneath Infer within the navigation pane.
- Select Create batch inference job.
- For Job title, enter a reputation to your job.
- For Mannequin, select the mannequin to make use of.
- For Enter information, enter the situation of the Amazon Easy Storage Service (Amazon S3) enter bucket (JSONL format).
- For Output information, enter the S3 location of the output bucket.
- For Service entry, choose your methodology to authorize Amazon Bedrock.
- Select Create batch inference job.
Monitor batch inference with CloudWatch metrics
Amazon Bedrock now robotically publishes metrics for batch inference jobs beneath the AWS/Bedrock/Batch namespace. You may observe batch workload progress on the AWS account stage with the next CloudWatch metrics. For present Amazon Bedrock fashions, these metrics embrace data pending processing, enter and output tokens processed per minute, and for Anthropic Claude fashions, in addition they embrace tokens pending processing.
The next metrics will be monitored by modelId:
- NumberOfTokensPendingProcessing – Reveals what number of tokens are nonetheless ready to be processed, serving to you gauge backlog measurement
- NumberOfRecordsPendingProcessing – Tracks what number of inference requests stay within the queue, giving visibility into job progress
- NumberOfInputTokensProcessedPerMinute – Measures how shortly enter tokens are being consumed, indicating general processing throughput
- NumberOfOutputTokensProcessedPerMinute – Measures technology velocity
To view these metrics utilizing the CloudWatch console, full the next steps:
- On the CloudWatch console, select Metrics within the navigation pane.
- Filter metrics by AWS/Bedrock/Batch.
- Choose your
modelIdto view detailed metrics to your batch job.
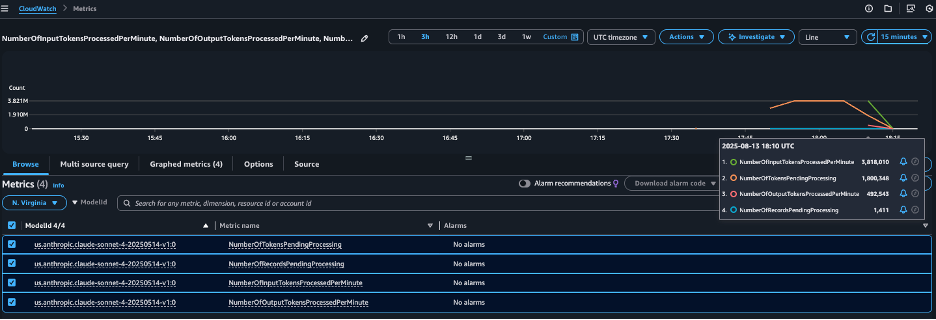
To study extra about the way to use CloudWatch to observe metrics, consult with Question your CloudWatch metrics with CloudWatch Metrics Insights.
Greatest practices for monitoring and managing batch inference
Take into account the next greatest practices for monitoring and managing your batch inference jobs:
- Value monitoring and optimization – By monitoring token throughput metrics (
NumberOfInputTokensProcessedPerMinuteandNumberOfOutputTokensProcessedPerMinute) alongside your batch job schedules, you may estimate inference prices utilizing data on the Amazon Bedrock pricing web page. This helps you perceive how briskly tokens are being processed, what meaning for price, and the way to regulate job measurement or scheduling to remain inside price range whereas nonetheless assembly throughput wants. - SLA and efficiency monitoring – The
NumberOfTokensPendingProcessingmetric is beneficial for understanding your batch backlog measurement and monitoring general job progress, however it shouldn’t be relied on to foretell job completion occasions as a result of they may differ relying on general inference site visitors to Amazon Bedrock. To know batch processing velocity, we suggest monitoring throughput metrics (NumberOfInputTokensProcessedPerMinuteandNumberOfOutputTokensProcessedPerMinute) as an alternative. If these throughput charges fall considerably beneath your anticipated baseline, you may configure automated alerts to set off remediation steps—for instance, shifting some jobs to on-demand processing to satisfy your anticipated timelines. - Job completion monitoring – When the metric
NumberOfRecordsPendingProcessingreaches zero, it signifies that every one operating batch inference jobs are full. You should utilize this sign to set off stakeholder notifications or begin downstream workflows.
Instance of CloudWatch metrics
On this part, we display how you should utilize CloudWatch metrics to arrange proactive alerts and automation.
For instance, you may create a CloudWatch alarm that sends an Amazon Easy Notification Service (Amazon SNS) notification when the common NumberOfInputTokensProcessedPerMinute exceeds 1 million inside a 6-hour interval. This alert may immediate an Ops crew evaluation or set off downstream information pipelines.
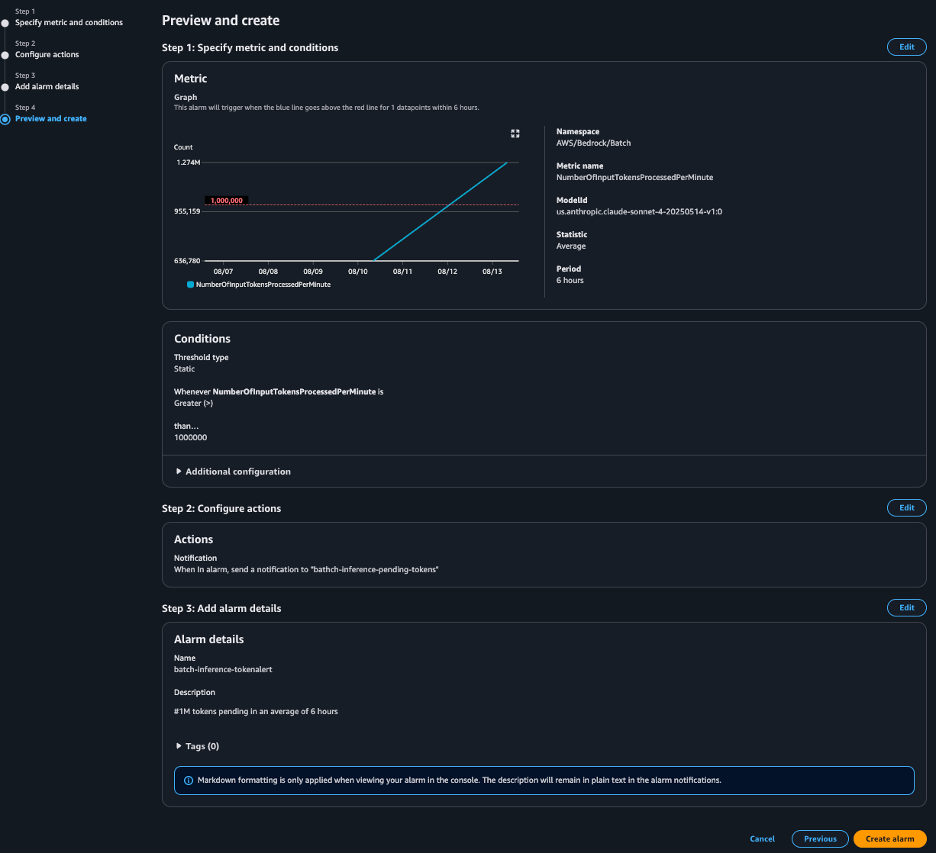
The next screenshot exhibits that the alert has In alarm standing as a result of the batch inference job met the brink. The alarm will set off the goal motion, in our case an SNS notification e-mail to the Ops crew.
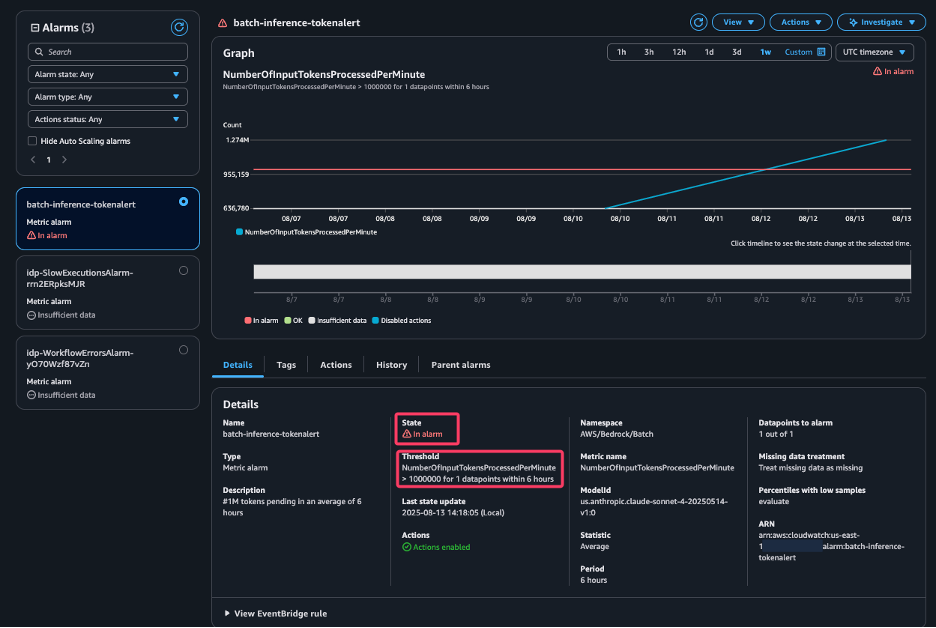
The next screenshot exhibits an instance of the e-mail the Ops crew acquired, notifying them that the variety of processed tokens exceeded their threshold.
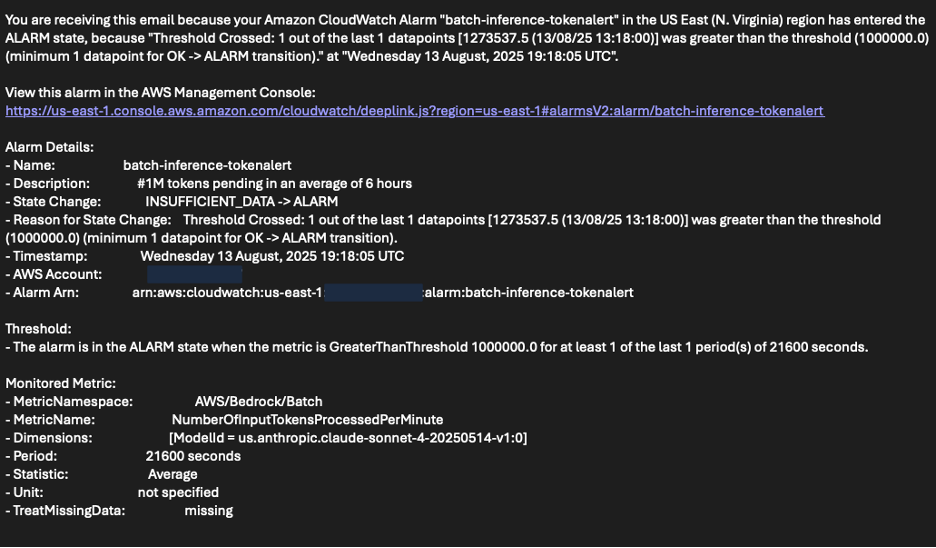
You may as well construct a CloudWatch dashboard displaying the related metrics. That is splendid for centralized operational monitoring and troubleshooting.
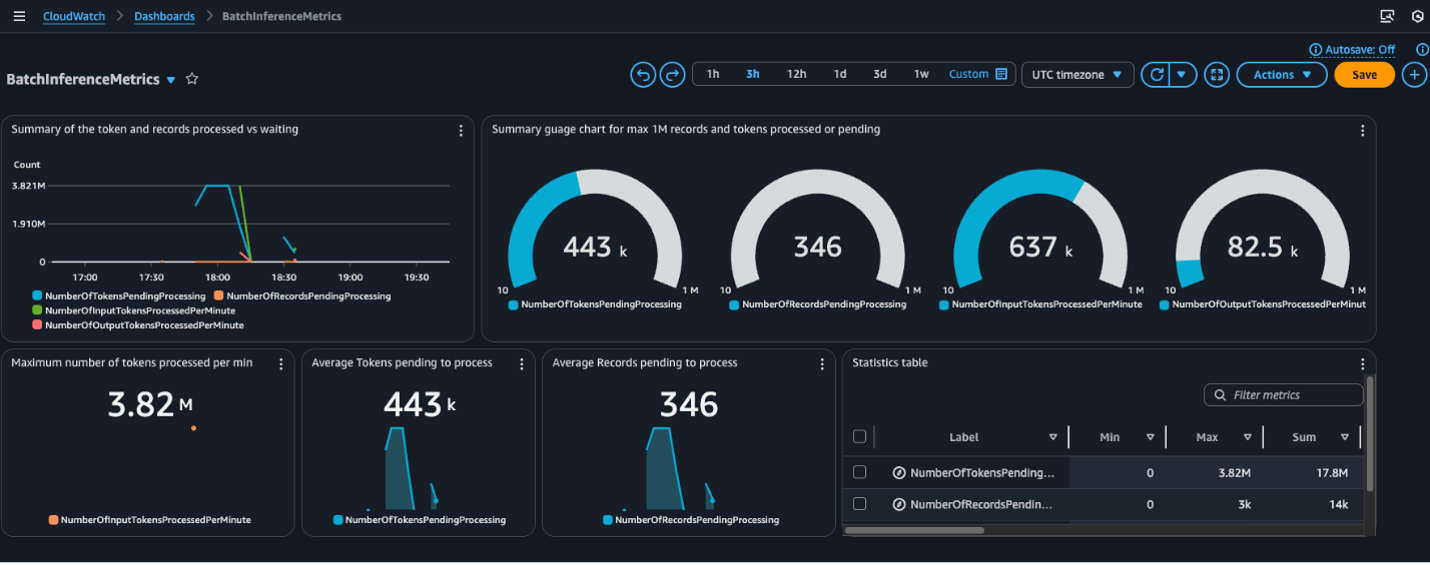
Conclusion
Amazon Bedrock batch inference now provides expanded mannequin help, improved efficiency, deeper visibility into the progress of your batch workloads, and enhanced price monitoring.
Get began right this moment by launching an Amazon Bedrock batch inference job, organising CloudWatch alarms, and constructing a monitoring dashboard, so you may maximize effectivity and worth out of your generative AI workloads.
Concerning the authors
 Vamsi Thilak Gudi is a Options Architect at Amazon Internet Providers (AWS) in Austin, Texas, serving to Public Sector prospects construct efficient cloud options. He brings various technical expertise to indicate prospects what’s doable with AWS applied sciences. He actively contributes to the AWS Technical Discipline Group for Generative AI.
Vamsi Thilak Gudi is a Options Architect at Amazon Internet Providers (AWS) in Austin, Texas, serving to Public Sector prospects construct efficient cloud options. He brings various technical expertise to indicate prospects what’s doable with AWS applied sciences. He actively contributes to the AWS Technical Discipline Group for Generative AI.
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to prospects use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, figuring out, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to prospects use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, figuring out, and exploring new issues.
 Avish Khosla is a software program developer on Bedrock’s Batch Inference crew, the place the crew construct dependable, scalable techniques to run large-scale inference workloads on generative AI fashions. he care about clear structure and nice docs. When he’s not transport code, he’s on a badminton courtroom or glued to a superb cricket match.
Avish Khosla is a software program developer on Bedrock’s Batch Inference crew, the place the crew construct dependable, scalable techniques to run large-scale inference workloads on generative AI fashions. he care about clear structure and nice docs. When he’s not transport code, he’s on a badminton courtroom or glued to a superb cricket match.
 Chintan Vyas serves as a Principal Product Supervisor–Technical at Amazon Internet Providers (AWS), the place he focuses on Amazon Bedrock companies. With over a decade of expertise in Software program Engineering and Product Administration, he focuses on constructing and scaling large-scale, safe, and high-performance Generative AI companies. In his present function, he leads the enhancement of programmatic interfaces for Amazon Bedrock. All through his tenure at AWS, he has efficiently pushed Product Administration initiatives throughout a number of strategic companies, together with Service Quotas, Useful resource Administration, Tagging, Amazon Personalize, Amazon Bedrock, and extra. Outdoors of labor, Chintan is keen about mentoring rising Product Managers and enjoys exploring the scenic mountain ranges of the Pacific Northwest.
Chintan Vyas serves as a Principal Product Supervisor–Technical at Amazon Internet Providers (AWS), the place he focuses on Amazon Bedrock companies. With over a decade of expertise in Software program Engineering and Product Administration, he focuses on constructing and scaling large-scale, safe, and high-performance Generative AI companies. In his present function, he leads the enhancement of programmatic interfaces for Amazon Bedrock. All through his tenure at AWS, he has efficiently pushed Product Administration initiatives throughout a number of strategic companies, together with Service Quotas, Useful resource Administration, Tagging, Amazon Personalize, Amazon Bedrock, and extra. Outdoors of labor, Chintan is keen about mentoring rising Product Managers and enjoys exploring the scenic mountain ranges of the Pacific Northwest.
 Mayank Parashar is a Software program Improvement Supervisor for Amazon Bedrock companies.
Mayank Parashar is a Software program Improvement Supervisor for Amazon Bedrock companies.